 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivergence-Augmented Policy Optimization
Jan 25, 2025In deep reinforcement learning, policy optimization methods need to deal with issues such as function approximation and the reuse of off-policy data. Standard policy gradient methods do not handle off-policy data well, leading to premature convergence and instability. This paper introduces a method to stabilize policy optimization when off-policy data are reused. The idea is to include a Bregman divergence between the behavior policy that generates the data and the current policy to ensure small and safe policy updates with off-policy data. The Bregman divergence is calculated between the state distributions of two policies, instead of only on the action probabilities, leading to a divergence augmentation formulation. Empirical experiments on Atari games show that in the data-scarce scenario where the reuse of off-policy data becomes necessary, our method can achieve better performance than other state-of-the-art deep reinforcement learning algorithms.
Diverse Policies Recovering via Pointwise Mutual Information Weighted Imitation Learning
Oct 21, 2024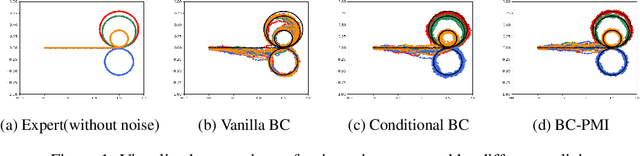
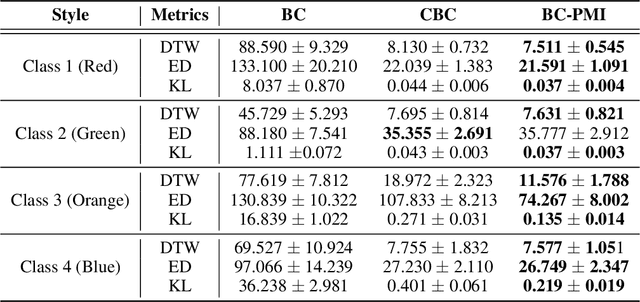
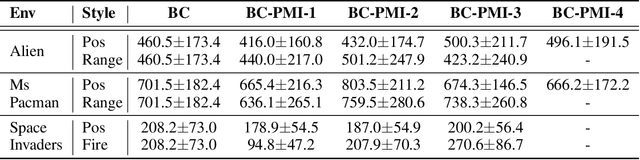
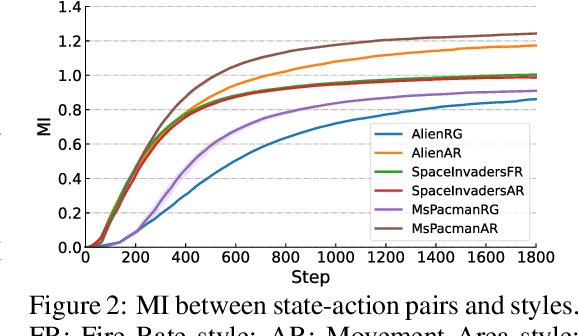
Recovering a spectrum of diverse policies from a set of expert trajectories is an important research topic in imitation learning. After determining a latent style for a trajectory, previous diverse policies recovering methods usually employ a vanilla behavioral cloning learning objective conditioned on the latent style, treating each state-action pair in the trajectory with equal importance. Based on an observation that in many scenarios, behavioral styles are often highly relevant with only a subset of state-action pairs, this paper presents a new principled method in diverse polices recovery. In particular, after inferring or assigning a latent style for a trajectory, we enhance the vanilla behavioral cloning by incorporating a weighting mechanism based on pointwise mutual information. This additional weighting reflects the significance of each state-action pair's contribution to learning the style, thus allowing our method to focus on state-action pairs most representative of that style. We provide theoretical justifications for our new objective, and extensive empirical evaluations confirm the effectiveness of our method in recovering diverse policies from expert data.
TLeague: A Framework for Competitive Self-Play based Distributed Multi-Agent Reinforcement Learning
Nov 30, 2020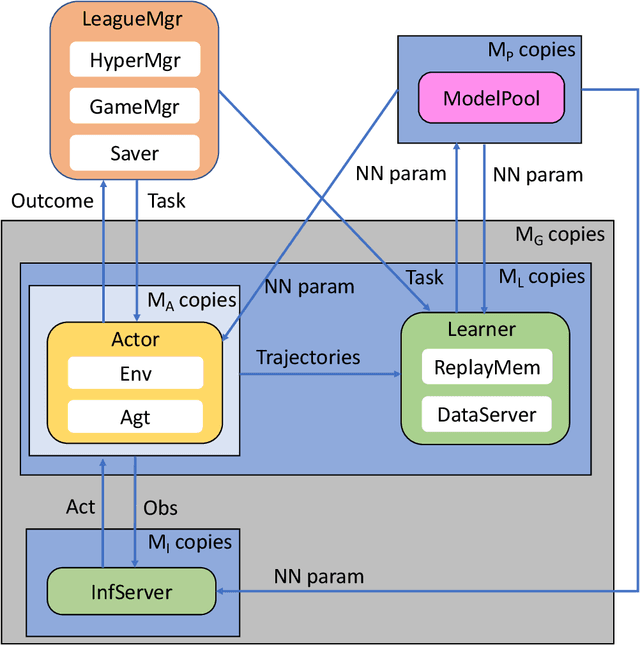

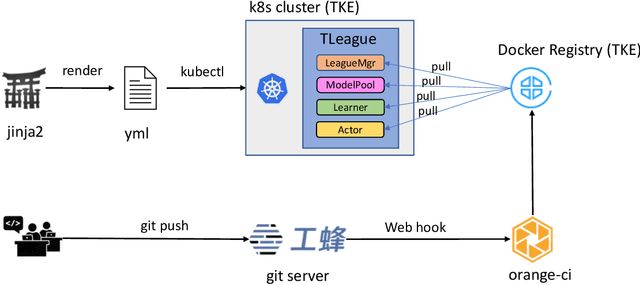
Competitive Self-Play (CSP) based Multi-Agent Reinforcement Learning (MARL) has shown phenomenal breakthroughs recently. Strong AIs are achieved for several benchmarks, including Dota 2, Glory of Kings, Quake III, StarCraft II, to name a few. Despite the success, the MARL training is extremely data thirsty, requiring typically billions of (if not trillions of) frames be seen from the environment during training in order for learning a high performance agent. This poses non-trivial difficulties for researchers or engineers and prevents the application of MARL to a broader range of real-world problems. To address this issue, in this manuscript we describe a framework, referred to as TLeague, that aims at large-scale training and implements several main-stream CSP-MARL algorithms. The training can be deployed in either a single machine or a cluster of hybrid machines (CPUs and GPUs), where the standard Kubernetes is supported in a cloud native manner. TLeague achieves a high throughput and a reasonable scale-up when performing distributed training. Thanks to the modular design, it is also easy to extend for solving other multi-agent problems or implementing and verifying MARL algorithms. We present experiments over StarCraft II, ViZDoom and Pommerman to show the efficiency and effectiveness of TLeague. The code is open-sourced and available at https://github.com/tencent-ailab/tleague_projpage
TStarBot-X: An Open-Sourced and Comprehensive Study for Efficient League Training in StarCraft II Full Game
Nov 27, 2020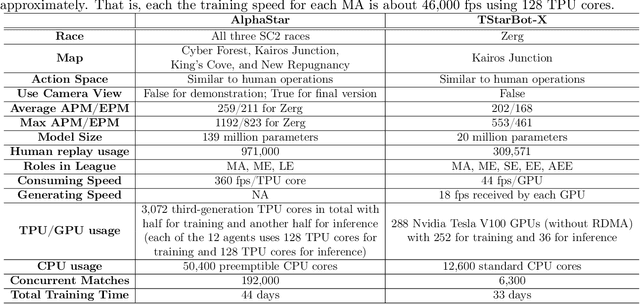
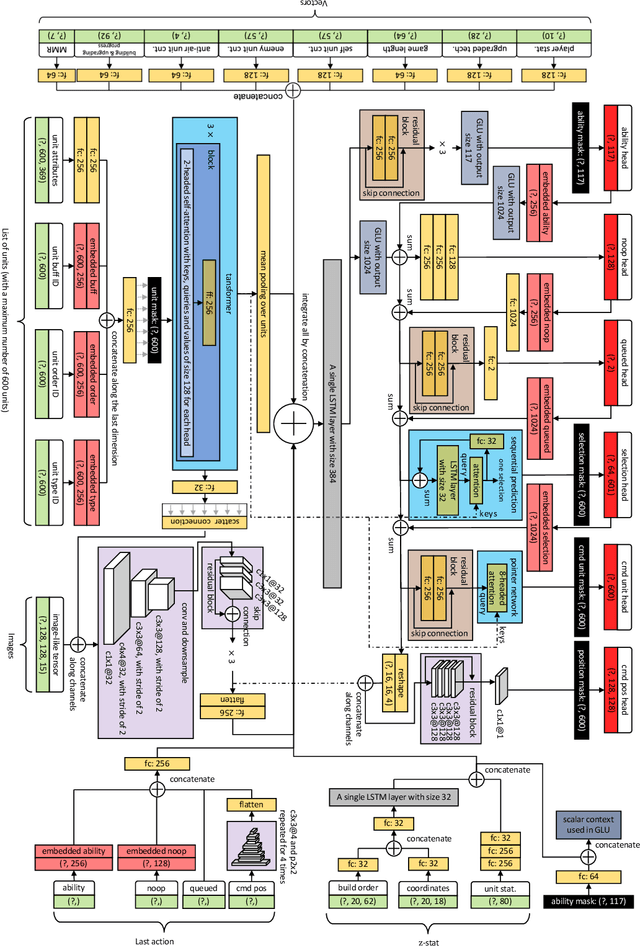
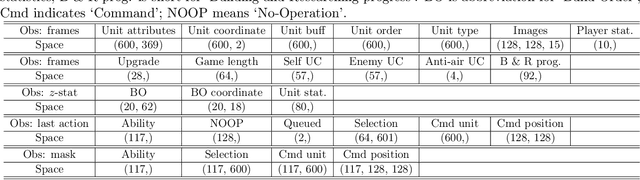

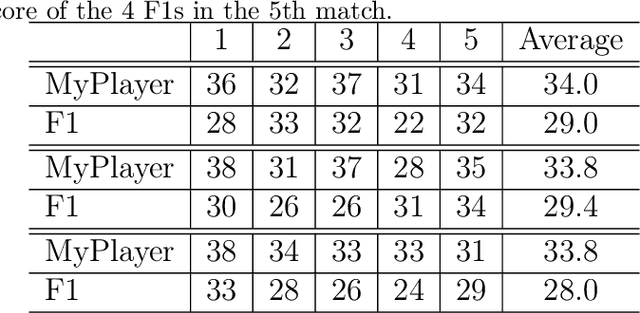
StarCraft, one of the most difficult esport games with long-standing history of professional tournaments, has attracted generations of players and fans, and also, intense attentions in artificial intelligence research. Recently, Google's DeepMind announced AlphaStar, a grandmaster level AI in StarCraft II. In this paper, we introduce a new AI agent, named TStarBot-X, that is trained under limited computation resources and can play competitively with expert human players. TStarBot-X takes advantage of important techniques introduced in AlphaStar, and also benefits from substantial innovations including new league training methods, novel multi-agent roles, rule-guided policy search, lightweight neural network architecture, and importance sampling in imitation learning, etc. We show that with limited computation resources, a faithful reimplementation of AlphaStar can not succeed and the proposed techniques are necessary to ensure TStarBot-X's competitive performance. We reveal all technical details that are complementary to those mentioned in AlphaStar, showing the most sensitive parts in league training, reinforcement learning and imitation learning that affect the performance of the agents. Most importantly, this is an open-sourced study that all codes and resources (including the trained model parameters) are publicly accessible via https://github.com/tencent-ailab/tleague_projpage We expect this study could be beneficial for both academic and industrial future research in solving complex problems like StarCraft, and also, might provide a sparring partner for all StarCraft II players and other AI agents.
Zeroth-Order Supervised Policy Improvement
Jun 11, 2020



Despite the remarkable progress made by the policy gradient algorithms in reinforcement learning (RL), sub-optimal policies usually result from the local exploration property of the policy gradient update. In this work, we propose a method referred to as Zeroth-Order Supervised Policy Improvement (ZOSPI) that exploits the estimated value function Q globally while preserves the local exploitation of the policy gradient methods. We prove that with a good function structure, the zeroth-order optimization strategy combining both local and global samplings can find the global minima within a polynomial number of samples. To improve the exploration efficiency in unknown environments, ZOSPI is further combined with bootstrapped Q networks. Different from the standard policy gradient methods, the policy learning of ZOSPI is conducted in a self-supervision manner so that the policy can be implemented with gradient-free non-parametric models besides the neural network approximator. Experiments show that ZOSPI achieves competitive results on MuJoCo locomotion tasks with a remarkable sample efficiency.
Arena: a toolkit for Multi-Agent Reinforcement Learning
Jul 20, 2019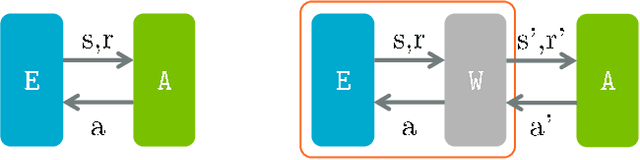
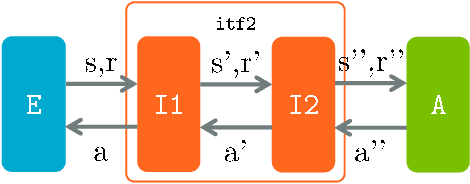
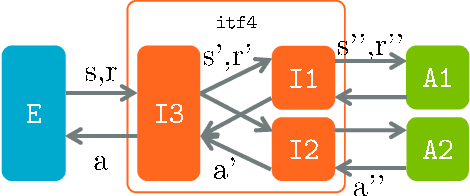

We introduce Arena, a toolkit for multi-agent reinforcement learning (MARL) research. In MARL, it usually requires customizing observations, rewards and actions for each agent, changing cooperative-competitive agent-interaction, and playing with/against a third-party agent, etc. We provide a novel modular design, called Interface, for manipulating such routines in essentially two ways: 1) Different interfaces can be concatenated and combined, which extends the OpenAI Gym Wrappers concept to MARL scenarios. 2) During MARL training or testing, interfaces can be embedded in either wrapped OpenAI Gym compatible Environments or raw environment compatible Agents. We offer off-the-shelf interfaces for several popular MARL platforms, including StarCraft II, Pommerman, ViZDoom, Soccer, etc. The interfaces effectively support self-play RL and cooperative-competitive hybrid MARL. Also, Arena can be conveniently extended to your own favorite MARL platform.
TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game
Nov 02, 2018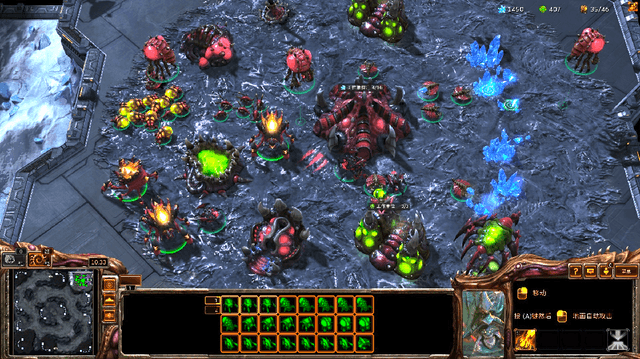


Starcraft II (SC2) is widely considered as the most challenging Real Time Strategy (RTS) game. The underlying challenges include a large observation space, a huge (continuous and infinite) action space, partial observations, simultaneous move for all players, and long horizon delayed rewards for local decisions. To push the frontier of AI research, Deepmind and Blizzard jointly developed the StarCraft II Learning Environment (SC2LE) as a testbench of complex decision making systems. SC2LE provides a few mini games such as MoveToBeacon, CollectMineralShards, and DefeatRoaches, where some AI agents have achieved the performance level of human professional players. However, for full games, the current AI agents are still far from achieving human professional level performance. To bridge this gap, we present two full game AI agents in this paper - the AI agent TStarBot1 is based on deep reinforcement learning over a flat action structure, and the AI agent TStarBot2 is based on hard-coded rules over a hierarchical action structure. Both TStarBot1 and TStarBot2 are able to defeat the built-in AI agents from level 1 to level 10 in a full game (1v1 Zerg-vs-Zerg game on the AbyssalReef map), noting that level 8, level 9, and level 10 are cheating agents with unfair advantages such as full vision on the whole map and resource harvest boosting. To the best of our knowledge, this is the first public work to investigate AI agents that can defeat the built-in AI in the StarCraft II full game.
Parametrized Deep Q-Networks Learning: Reinforcement Learning with Discrete-Continuous Hybrid Action Space
Oct 10, 2018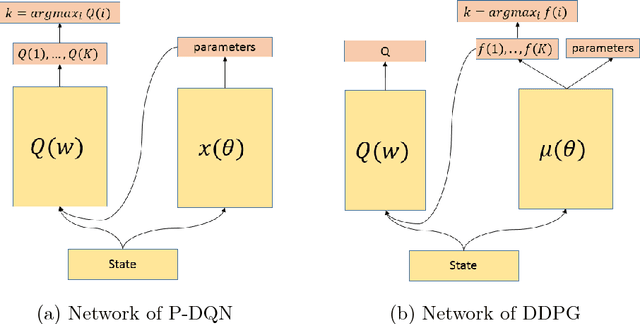
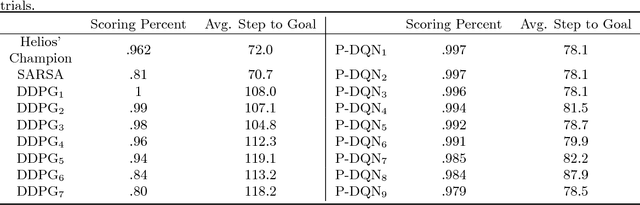


Most existing deep reinforcement learning (DRL) frameworks consider either discrete action space or continuous action space solely. Motivated by applications in computer games, we consider the scenario with discrete-continuous hybrid action space. To handle hybrid action space, previous works either approximate the hybrid space by discretization, or relax it into a continuous set. In this paper, we propose a parametrized deep Q-network (P- DQN) framework for the hybrid action space without approximation or relaxation. Our algorithm combines the spirits of both DQN (dealing with discrete action space) and DDPG (dealing with continuous action space) by seamlessly integrating them. Empirical results on a simulation example, scoring a goal in simulated RoboCup soccer and the solo mode in game King of Glory (KOG) validate the efficiency and effectiveness of our method.
A Margin-based MLE for Crowdsourced Partial Ranking
Jul 29, 2018



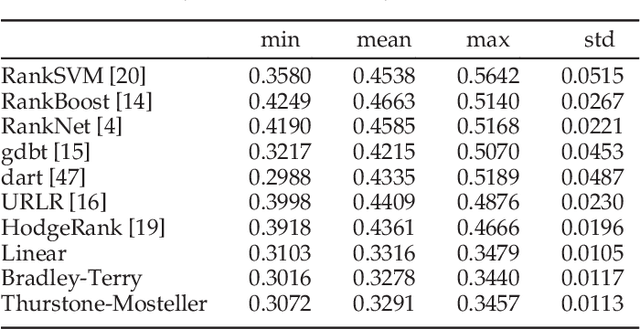
A preference order or ranking aggregated from pairwise comparison data is commonly understood as a strict total order. However, in real-world scenarios, some items are intrinsically ambiguous in comparisons, which may very well be an inherent uncertainty of the data. In this case, the conventional total order ranking can not capture such uncertainty with mere global ranking or utility scores. In this paper, we are specifically interested in the recent surge in crowdsourcing applications to predict partial but more accurate (i.e., making less incorrect statements) orders rather than complete ones. To do so, we propose a novel framework to learn some probabilistic models of partial orders as a \emph{margin-based Maximum Likelihood Estimate} (MLE) method. We prove that the induced MLE is a joint convex optimization problem with respect to all the parameters, including the global ranking scores and margin parameter. Moreover, three kinds of generalized linear models are studied, including the basic uniform model, Bradley-Terry model, and Thurstone-Mosteller model, equipped with some theoretical analysis on FDR and Power control for the proposed methods. The validity of these models are supported by experiments with both simulated and real-world datasets, which shows that the proposed models exhibit improvements compared with traditional state-of-the-art algorithms.
From Social to Individuals: a Parsimonious Path of Multi-level Models for Crowdsourced Preference Aggregation
Mar 08, 2018


In crowdsourced preference aggregation, it is often assumed that all the annotators are subject to a common preference or social utility function which generates their comparison behaviors in experiments. However, in reality annotators are subject to variations due to multi-criteria, abnormal, or a mixture of such behaviors. In this paper, we propose a parsimonious mixed-effects model, which takes into account both the fixed effect that the majority of annotators follows a common linear utility model, and the random effect that some annotators might deviate from the common significantly and exhibit strongly personalized preferences. The key algorithm in this paper establishes a dynamic path from the social utility to individual variations, with different levels of sparsity on personalization. The algorithm is based on the Linearized Bregman Iterations, which leads to easy parallel implementations to meet the need of large-scale data analysis. In this unified framework, three kinds of random utility models are presented, including the basic linear model with L2 loss, Bradley-Terry model, and Thurstone-Mosteller model. The validity of these multi-level models are supported by experiments with both simulated and real-world datasets, which shows that the parsimonious multi-level models exhibit improvements in both interpretability and predictive precision compared with traditional HodgeRank.