 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLeague: A Framework for Competitive Self-Play based Distributed Multi-Agent Reinforcement Learning
Nov 30, 2020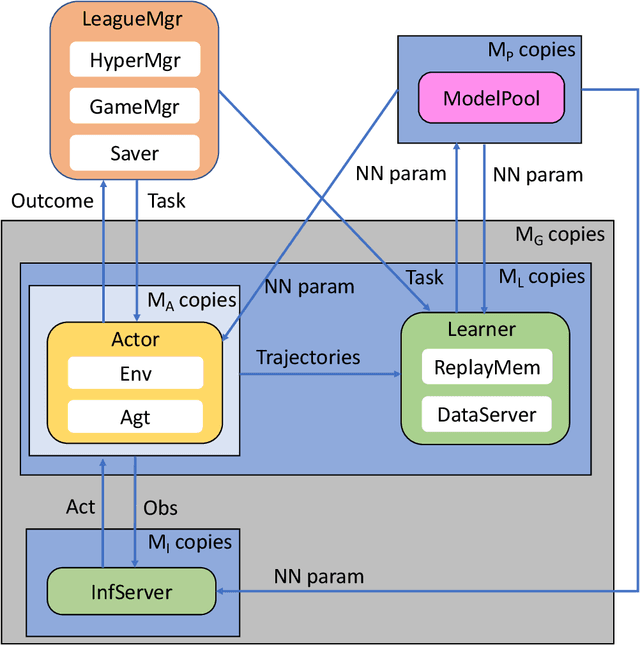

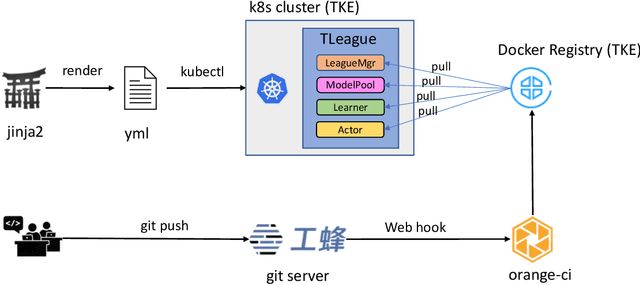
Competitive Self-Play (CSP) based Multi-Agent Reinforcement Learning (MARL) has shown phenomenal breakthroughs recently. Strong AIs are achieved for several benchmarks, including Dota 2, Glory of Kings, Quake III, StarCraft II, to name a few. Despite the success, the MARL training is extremely data thirsty, requiring typically billions of (if not trillions of) frames be seen from the environment during training in order for learning a high performance agent. This poses non-trivial difficulties for researchers or engineers and prevents the application of MARL to a broader range of real-world problems. To address this issue, in this manuscript we describe a framework, referred to as TLeague, that aims at large-scale training and implements several main-stream CSP-MARL algorithms. The training can be deployed in either a single machine or a cluster of hybrid machines (CPUs and GPUs), where the standard Kubernetes is supported in a cloud native manner. TLeague achieves a high throughput and a reasonable scale-up when performing distributed training. Thanks to the modular design, it is also easy to extend for solving other multi-agent problems or implementing and verifying MARL algorithms. We present experiments over StarCraft II, ViZDoom and Pommerman to show the efficiency and effectiveness of TLeague. The code is open-sourced and available at https://github.com/tencent-ailab/tleague_projpage
TStarBot-X: An Open-Sourced and Comprehensive Study for Efficient League Training in StarCraft II Full Game
Nov 27, 2020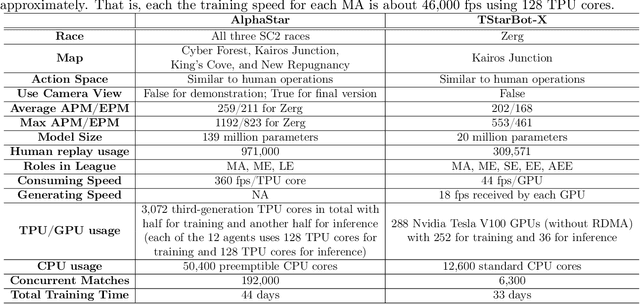
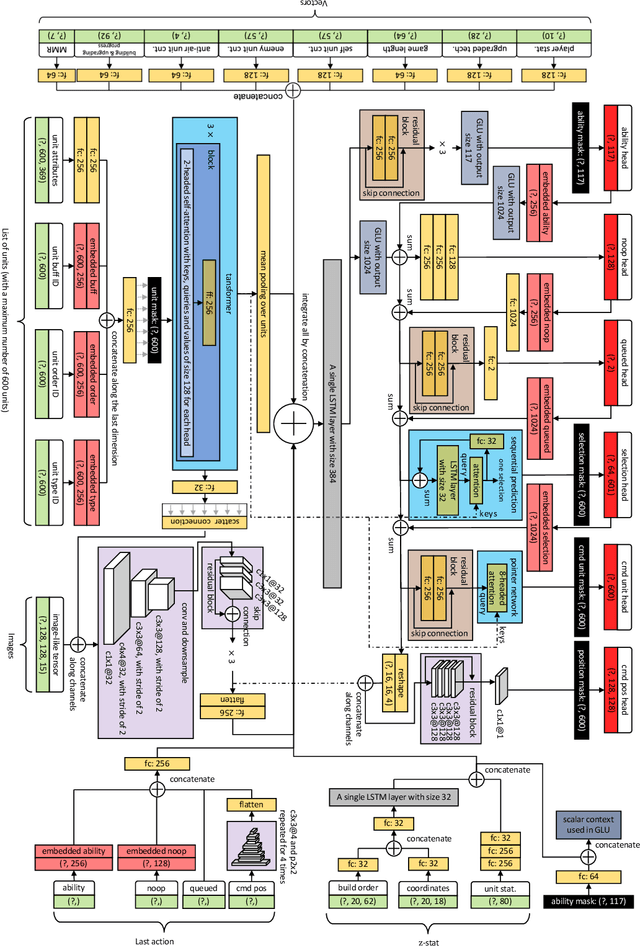
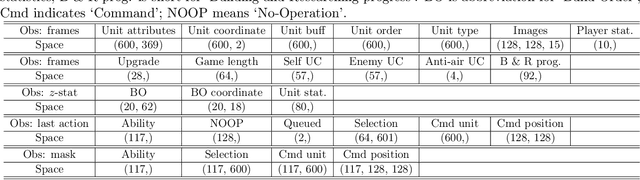

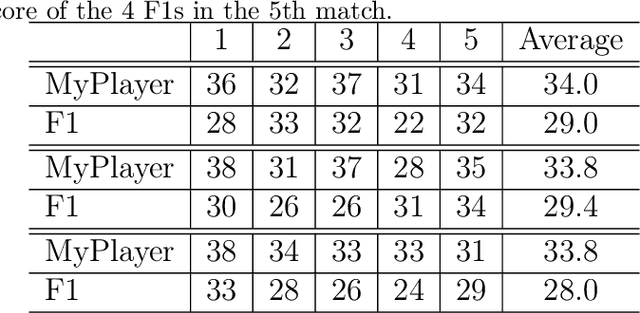
StarCraft, one of the most difficult esport games with long-standing history of professional tournaments, has attracted generations of players and fans, and also, intense attentions in artificial intelligence research. Recently, Google's DeepMind announced AlphaStar, a grandmaster level AI in StarCraft II. In this paper, we introduce a new AI agent, named TStarBot-X, that is trained under limited computation resources and can play competitively with expert human players. TStarBot-X takes advantage of important techniques introduced in AlphaStar, and also benefits from substantial innovations including new league training methods, novel multi-agent roles, rule-guided policy search, lightweight neural network architecture, and importance sampling in imitation learning, etc. We show that with limited computation resources, a faithful reimplementation of AlphaStar can not succeed and the proposed techniques are necessary to ensure TStarBot-X's competitive performance. We reveal all technical details that are complementary to those mentioned in AlphaStar, showing the most sensitive parts in league training, reinforcement learning and imitation learning that affect the performance of the agents. Most importantly, this is an open-sourced study that all codes and resources (including the trained model parameters) are publicly accessible via https://github.com/tencent-ailab/tleague_projpage We expect this study could be beneficial for both academic and industrial future research in solving complex problems like StarCraft, and also, might provide a sparring partner for all StarCraft II players and other AI agents.
Arena: a toolkit for Multi-Agent Reinforcement Learning
Jul 20, 2019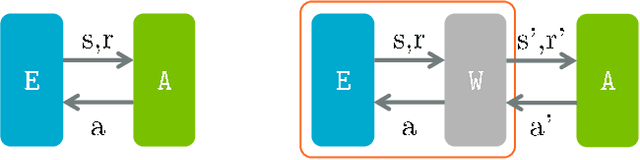
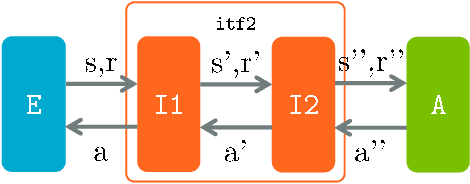
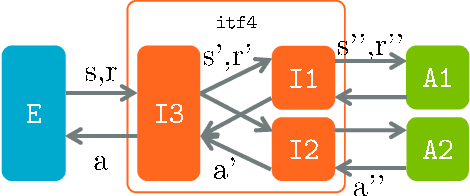

We introduce Arena, a toolkit for multi-agent reinforcement learning (MARL) research. In MARL, it usually requires customizing observations, rewards and actions for each agent, changing cooperative-competitive agent-interaction, and playing with/against a third-party agent, etc. We provide a novel modular design, called Interface, for manipulating such routines in essentially two ways: 1) Different interfaces can be concatenated and combined, which extends the OpenAI Gym Wrappers concept to MARL scenarios. 2) During MARL training or testing, interfaces can be embedded in either wrapped OpenAI Gym compatible Environments or raw environment compatible Agents. We offer off-the-shelf interfaces for several popular MARL platforms, including StarCraft II, Pommerman, ViZDoom, Soccer, etc. The interfaces effectively support self-play RL and cooperative-competitive hybrid MARL. Also, Arena can be conveniently extended to your own favorite MARL platform.
TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game
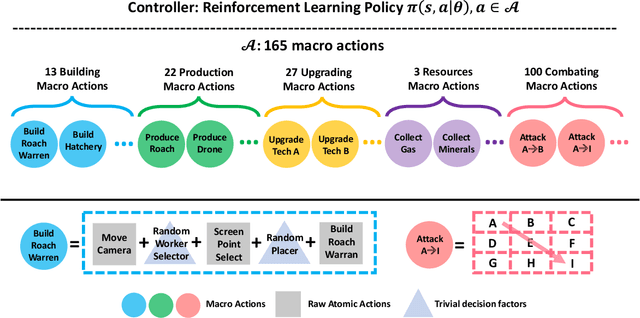
Nov 02, 2018


Starcraft II (SC2) is widely considered as the most challenging Real Time Strategy (RTS) game. The underlying challenges include a large observation space, a huge (continuous and infinite) action space, partial observations, simultaneous move for all players, and long horizon delayed rewards for local decisions. To push the frontier of AI research, Deepmind and Blizzard jointly developed the StarCraft II Learning Environment (SC2LE) as a testbench of complex decision making systems. SC2LE provides a few mini games such as MoveToBeacon, CollectMineralShards, and DefeatRoaches, where some AI agents have achieved the performance level of human professional players. However, for full games, the current AI agents are still far from achieving human professional level performance. To bridge this gap, we present two full game AI agents in this paper - the AI agent TStarBot1 is based on deep reinforcement learning over a flat action structure, and the AI agent TStarBot2 is based on hard-coded rules over a hierarchical action structure. Both TStarBot1 and TStarBot2 are able to defeat the built-in AI agents from level 1 to level 10 in a full game (1v1 Zerg-vs-Zerg game on the AbyssalReef map), noting that level 8, level 9, and level 10 are cheating agents with unfair advantages such as full vision on the whole map and resource harvest boosting. To the best of our knowledge, this is the first public work to investigate AI agents that can defeat the built-in AI in the StarCraft II full game.