 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTStarBot-X: An Open-Sourced and Comprehensive Study for Efficient League Training in StarCraft II Full Game
Nov 27, 2020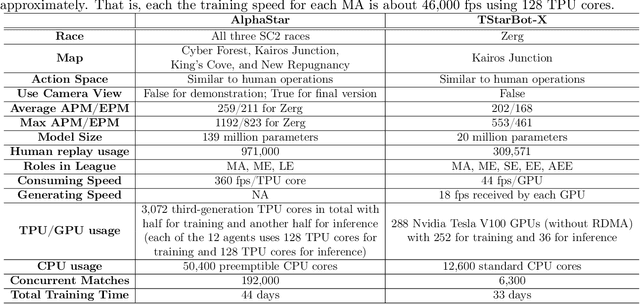
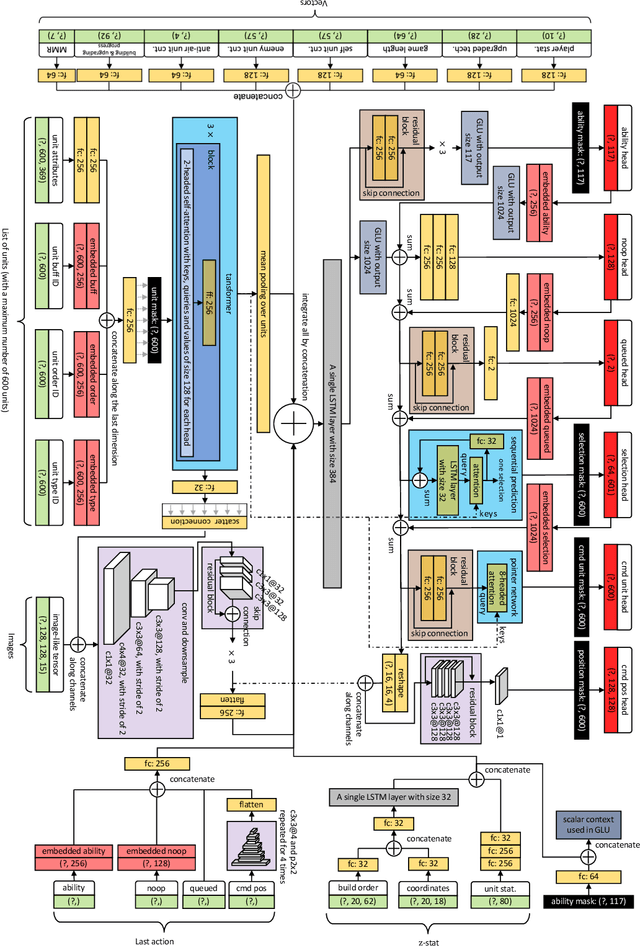
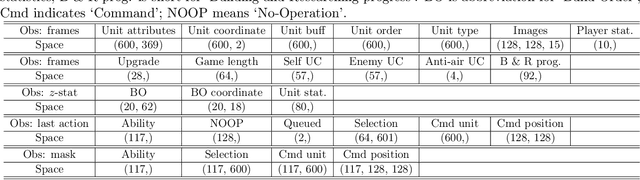

StarCraft, one of the most difficult esport games with long-standing history of professional tournaments, has attracted generations of players and fans, and also, intense attentions in artificial intelligence research. Recently, Google's DeepMind announced AlphaStar, a grandmaster level AI in StarCraft II. In this paper, we introduce a new AI agent, named TStarBot-X, that is trained under limited computation resources and can play competitively with expert human players. TStarBot-X takes advantage of important techniques introduced in AlphaStar, and also benefits from substantial innovations including new league training methods, novel multi-agent roles, rule-guided policy search, lightweight neural network architecture, and importance sampling in imitation learning, etc. We show that with limited computation resources, a faithful reimplementation of AlphaStar can not succeed and the proposed techniques are necessary to ensure TStarBot-X's competitive performance. We reveal all technical details that are complementary to those mentioned in AlphaStar, showing the most sensitive parts in league training, reinforcement learning and imitation learning that affect the performance of the agents. Most importantly, this is an open-sourced study that all codes and resources (including the trained model parameters) are publicly accessible via https://github.com/tencent-ailab/tleague_projpage We expect this study could be beneficial for both academic and industrial future research in solving complex problems like StarCraft, and also, might provide a sparring partner for all StarCraft II players and other AI agents.
Mastering Complex Control in MOBA Games with Deep Reinforcement Learning
Jan 03, 2020
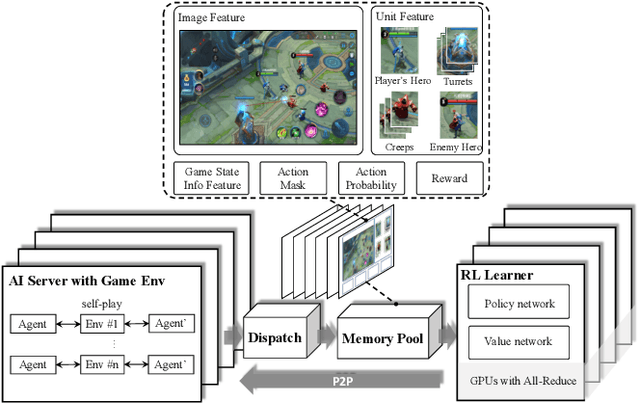
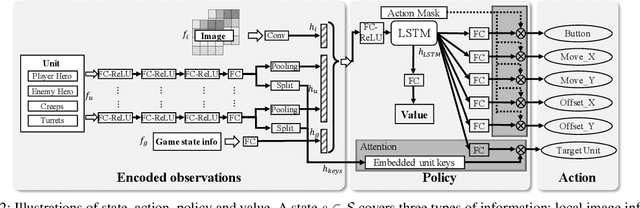

We study the reinforcement learning problem of complex action control in the Multi-player Online Battle Arena (MOBA) 1v1 games. This problem involves far more complicated state and action spaces than those of traditional 1v1 games, such as Go and Atari series, which makes it very difficult to search any policies with human-level performance. In this paper, we present a deep reinforcement learning framework to tackle this problem from the perspectives of both system and algorithm. Our system is of low coupling and high scalability, which enables efficient explorations at large scale. Our algorithm includes several novel strategies, including control dependency decoupling, action mask, target attention, and dual-clip PPO, with which our proposed actor-critic network can be effectively trained in our system. Tested on the MOBA game Honor of Kings, the trained AI agents can defeat top professional human players in full 1v1 games.
Crowd counting via scale-adaptive convolutional neural network
Feb 06, 2018

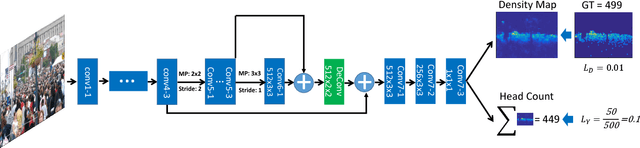

The task of crowd counting is to automatically estimate the pedestrian number in crowd images. To cope with the scale and perspective changes that commonly exist in crowd images, state-of-the-art approaches employ multi-column CNN architectures to regress density maps of crowd images. Multiple columns have different receptive fields corresponding to pedestrians (heads) of different scales. We instead propose a scale-adaptive CNN (SaCNN) architecture with a backbone of fixed small receptive fields. We extract feature maps from multiple layers and adapt them to have the same output size; we combine them to produce the final density map. The number of people is computed by integrating the density map. We also introduce a relative count loss along with the density map loss to improve the network generalization on crowd scenes with few pedestrians, where most representative approaches perform poorly on. We conduct extensive experiments on the ShanghaiTech, UCF_CC_50 and WorldExpo datasets as well as a new dataset SmartCity that we collect for crowd scenes with few people. The results demonstrate significant improvements of SaCNN over the state-of-the-art.