 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowPRO: Reward-Free Reinforced Fine-Tuning of Flow-Matching VLAs via Proximalized Preference Optimization
Jun 03, 2026Post-training Vision-Language-Action (VLA) models into policies that can be reliably deployed on real robots remains a major bottleneck. SFT and DAgger exploit failure signals only indirectly, and reward-based RL is bottlenecked by the difficulty of real-world reward design and of training reliable critics. We present FlowPRO, a reward-free offline reinforced fine-tuning framework for flow-matching VLAs. Algorithmically, we propose RPRO (Robotic Flow-matching Proximalized Preference Optimization), a preference-optimization objective tailored to the flow-matching action head of VLA models. RPRO pairs a contrastive optimizer with an explicit proximal regularizer that anchors the absolute magnitude of the implicit reward, thereby eliminating the reward-hacking failure mode of plain Flow-DPO. On the data side, a teleoperated intervention-and-rollback paradigm produces naturally paired positive and negative trajectories $(τ^w, τ^l)$ on a real robot from a single operator action; a Smooth Interpolation procedure, combined with batch mixing, then converts these sparse corrections into dense per-state supervision while preserving the base policy's capabilities. On four long-horizon bimanual tasks, FlowPRO attains the highest success rate, outperforming four representative baselines, and ablations confirm the contribution of each loss component.
HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
Apr 08, 2026We introduce HY-Embodied-0.5, a family of foundation models specifically designed for real-world embodied agents. To bridge the gap between general Vision-Language Models (VLMs) and the demands of embodied agents, our models are developed to enhance the core capabilities required by embodied intelligence: spatial and temporal visual perception, alongside advanced embodied reasoning for prediction, interaction, and planning. The HY-Embodied-0.5 suite comprises two primary variants: an efficient model with 2B activated parameters designed for edge deployment, and a powerful model with 32B activated parameters targeted for complex reasoning. To support the fine-grained visual perception essential for embodied tasks, we adopt a Mixture-of-Transformers (MoT) architecture to enable modality-specific computing. By incorporating latent tokens, this design effectively enhances the perceptual representation of the models. To improve reasoning capabilities, we introduce an iterative, self-evolving post-training paradigm. Furthermore, we employ on-policy distillation to transfer the advanced capabilities of the large model to the smaller variant, thereby maximizing the performance potential of the compact model. Extensive evaluations across 22 benchmarks, spanning visual perception, spatial reasoning, and embodied understanding, demonstrate the effectiveness of our approach. Our MoT-2B model outperforms similarly sized state-of-the-art models on 16 benchmarks, while the 32B variant achieves performance comparable to frontier models such as Gemini 3.0 Pro. In downstream robot control experiments, we leverage our robust VLM foundation to train an effective Vision-Language-Action (VLA) model, achieving compelling results in real-world physical evaluations. Code and models are open-sourced at https://github.com/Tencent-Hunyuan/HY-Embodied.
Listening with the Eyes: Benchmarking Egocentric Co-Speech Grounding across Space and Time
Mar 09, 2026In situated collaboration, speakers often use intentionally underspecified deictic commands (e.g., ``pass me \textit{that}''), whose referent becomes identifiable only by aligning speech with a brief co-speech pointing \emph{stroke}. However, many embodied benchmarks admit language-only shortcuts, allowing MLLMs to perform well without learning the \emph{audio--visual alignment} required by deictic interaction. To bridge this gap, we introduce \textbf{Egocentric Co-Speech Grounding (EcoG)}, where grounding is executable only if an agent jointly predicts \textit{What}, \textit{Where}, and \textit{When}. To operationalize this, we present \textbf{EcoG-Bench}, an evaluation-only bilingual (EN/ZH) diagnostic benchmark of \textbf{811} egocentric clips with dense spatial annotations and millisecond-level stroke supervision. It is organized under a \textbf{Progressive Cognitive Evaluation} protocol. Benchmarking state-of-the-art MLLMs reveals a severe executability gap: while human subjects achieve near-ceiling performance on EcoG-Bench (\textbf{96.9\%} strict Eco-Accuracy), the best native video-audio setting remains low (Gemini-3-Pro: \textbf{17.0\%}). Moreover, in a diagnostic ablation, replacing the native video--audio interface with timestamped frame samples and externally verified ASR (with word-level timing) substantially improves the same model (\textbf{17.0\%}$\to$\textbf{42.9\%}). Overall, EcoG-Bench provides a strict, executable testbed for event-level speech--gesture binding, and suggests that multimodal interfaces may bottleneck the observability of temporal alignment cues, independently of model reasoning.
Cooperative-Competitive Team Play of Real-World Craft Robots
Feb 24, 2026Multi-agent deep Reinforcement Learning (RL) has made significant progress in developing intelligent game-playing agents in recent years. However, the efficient training of collective robots using multi-agent RL and the transfer of learned policies to real-world applications remain open research questions. In this work, we first develop a comprehensive robotic system, including simulation, distributed learning framework, and physical robot components. We then propose and evaluate reinforcement learning techniques designed for efficient training of cooperative and competitive policies on this platform. To address the challenges of multi-agent sim-to-real transfer, we introduce Out of Distribution State Initialization (OODSI) to mitigate the impact of the sim-to-real gap. In the experiments, OODSI improves the Sim2Real performance by 20%. We demonstrate the effectiveness of our approach through experiments with a multi-robot car competitive game and a cooperative task in real-world settings.
ProAct: A Benchmark and Multimodal Framework for Structure-Aware Proactive Response
Feb 03, 2026While passive agents merely follow instructions, proactive agents align with higher-level objectives, such as assistance and safety by continuously monitoring the environment to determine when and how to act. However, developing proactive agents is hindered by the lack of specialized resources. To address this, we introduce ProAct-75, a benchmark designed to train and evaluate proactive agents across diverse domains, including assistance, maintenance, and safety monitoring. Spanning 75 tasks, our dataset features 91,581 step-level annotations enriched with explicit task graphs. These graphs encode step dependencies and parallel execution possibilities, providing the structural grounding necessary for complex decision-making. Building on this benchmark, we propose ProAct-Helper, a reference baseline powered by a Multimodal Large Language Model (MLLM) that grounds decision-making in state detection, and leveraging task graphs to enable entropy-driven heuristic search for action selection, allowing agents to execute parallel threads independently rather than mirroring the human's next step. Extensive experiments demonstrate that ProAct-Helper outperforms strong closed-source models, improving trigger detection mF1 by 6.21%, saving 0.25 more steps in online one-step decision, and increasing the rate of parallel actions by 15.58%.
ESearch-R1: Learning Cost-Aware MLLM Agents for Interactive Embodied Search via Reinforcement Learning
Dec 21, 2025Multimodal Large Language Models (MLLMs) have empowered embodied agents with remarkable capabilities in planning and reasoning. However, when facing ambiguous natural language instructions (e.g., "fetch the tool" in a cluttered room), current agents often fail to balance the high cost of physical exploration against the cognitive cost of human interaction. They typically treat disambiguation as a passive perception problem, lacking the strategic reasoning to minimize total task execution costs. To bridge this gap, we propose ESearch-R1, a cost-aware embodied reasoning framework that unifies interactive dialogue (Ask), episodic memory retrieval (GetMemory), and physical navigation (Navigate) into a single decision process. We introduce HC-GRPO (Heterogeneous Cost-Aware Group Relative Policy Optimization). Unlike traditional PPO which relies on a separate value critic, HC-GRPO optimizes the MLLM by sampling groups of reasoning trajectories and reinforcing those that achieve the optimal trade-off between information gain and heterogeneous costs (e.g., navigate time, and human attention). Extensive experiments in AI2-THOR demonstrate that ESearch-R1 significantly outperforms standard ReAct-based agents. It improves task success rates while reducing total operational costs by approximately 50\%, validating the effectiveness of GRPO in aligning MLLM agents with physical world constraints.
Compliance while resisting: a shear-thickening fluid controller for physical human-robot interaction
Feb 03, 2025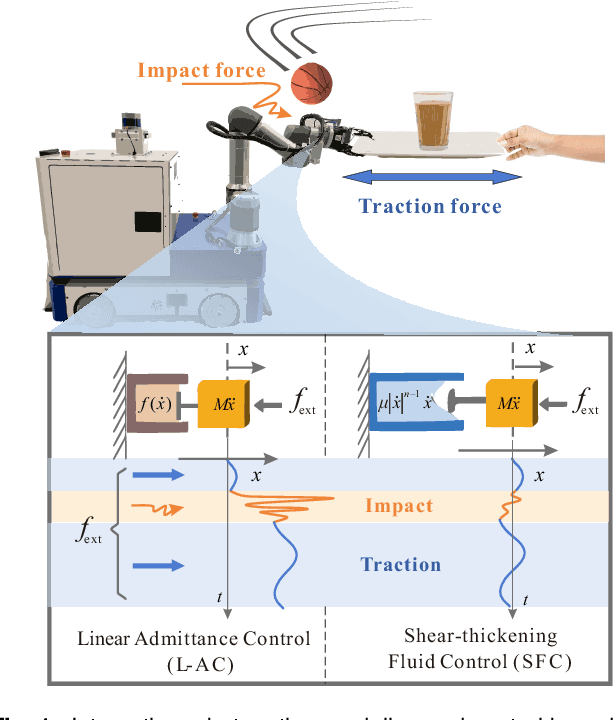


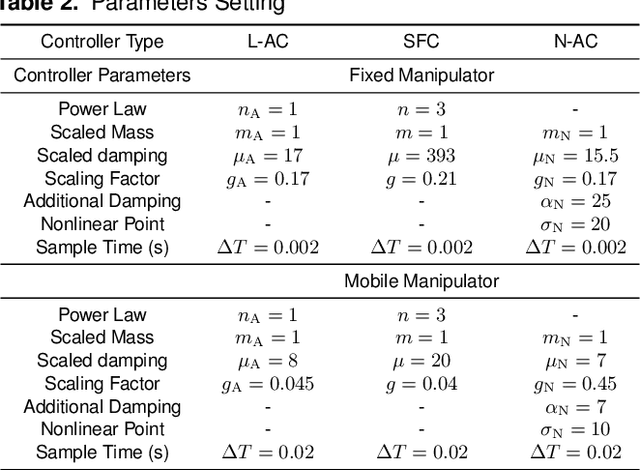
Physical human-robot interaction (pHRI) is widely needed in many fields, such as industrial manipulation, home services, and medical rehabilitation, and puts higher demands on the safety of robots. Due to the uncertainty of the working environment, the pHRI may receive unexpected impact interference, which affects the safety and smoothness of the task execution. The commonly used linear admittance control (L-AC) can cope well with high-frequency small-amplitude noise, but for medium-frequency high-intensity impact, the effect is not as good. Inspired by the solid-liquid phase change nature of shear-thickening fluid, we propose a Shear-thickening Fluid Control (SFC) that can achieve both an easy human-robot collaboration and resistance to impact interference. The SFC's stability, passivity, and phase trajectory are analyzed in detail, the frequency and time domain properties are quantified, and parameter constraints in discrete control and coupled stability conditions are provided. We conducted simulations to compare the frequency and time domain characteristics of L-AC, nonlinear admittance controller (N-AC), and SFC, and validated their dynamic properties. In real-world experiments, we compared the performance of L-AC, N-AC, and SFC in both fixed and mobile manipulators. L-AC exhibits weak resistance to impact. N-AC can resist moderate impacts but not high-intensity ones, and may exhibit self-excited oscillations. In contrast, SFC demonstrated superior impact resistance and maintained stable collaboration, enhancing comfort in cooperative water delivery tasks. Additionally, a case study was conducted in a factory setting, further affirming the SFC's capability in facilitating human-robot collaborative manipulation and underscoring its potential in industrial applications.
Whole-Body Impedance Coordinative Control of Wheel-Legged Robot on Uncertain Terrain
Nov 15, 2024



This article propose a whole-body impedance coordinative control framework for a wheel-legged humanoid robot to achieve adaptability on complex terrains while maintaining robot upper body stability. The framework contains a bi-level control strategy. The outer level is a variable damping impedance controller, which optimizes the damping parameters to ensure the stability of the upper body while holding an object. The inner level employs Whole-Body Control (WBC) optimization that integrates real-time terrain estimation based on wheel-foot position and force data. It generates motor torques while accounting for dynamic constraints, joint limits,friction cones, real-time terrain updates, and a model-free friction compensation strategy. The proposed whole-body coordinative control method has been tested on a recently developed quadruped humanoid robot. The results demonstrate that the proposed algorithm effectively controls the robot, maintaining upper body stability to successfully complete a water-carrying task while adapting to varying terrains.
RiskAwareBench: Towards Evaluating Physical Risk Awareness for High-level Planning of LLM-based Embodied Agents
Aug 08, 2024



The integration of large language models (LLMs) into robotics significantly enhances the capabilities of embodied agents in understanding and executing complex natural language instructions. However, the unmitigated deployment of LLM-based embodied systems in real-world environments may pose potential physical risks, such as property damage and personal injury. Existing security benchmarks for LLMs overlook risk awareness for LLM-based embodied agents. To address this gap, we propose RiskAwareBench, an automated framework designed to assess physical risks awareness in LLM-based embodied agents. RiskAwareBench consists of four modules: safety tips generation, risky scene generation, plan generation, and evaluation, enabling comprehensive risk assessment with minimal manual intervention. Utilizing this framework, we compile the PhysicalRisk dataset, encompassing diverse scenarios with associated safety tips, observations, and instructions. Extensive experiments reveal that most LLMs exhibit insufficient physical risk awareness, and baseline risk mitigation strategies yield limited enhancement, which emphasizes the urgency and cruciality of improving risk awareness in LLM-based embodied agents in the future.
TencentLLMEval: A Hierarchical Evaluation of Real-World Capabilities for Human-Aligned LLMs
Nov 09, 2023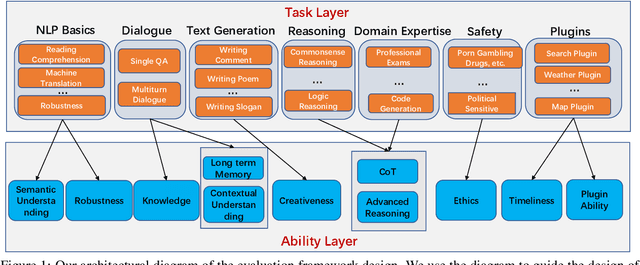



Large language models (LLMs) have shown impressive capabilities across various natural language tasks. However, evaluating their alignment with human preferences remains a challenge. To this end, we propose a comprehensive human evaluation framework to assess LLMs' proficiency in following instructions on diverse real-world tasks. We construct a hierarchical task tree encompassing 7 major areas covering over 200 categories and over 800 tasks, which covers diverse capabilities such as question answering, reasoning, multiturn dialogue, and text generation, to evaluate LLMs in a comprehensive and in-depth manner. We also design detailed evaluation standards and processes to facilitate consistent, unbiased judgments from human evaluators. A test set of over 3,000 instances is released, spanning different difficulty levels and knowledge domains. Our work provides a standardized methodology to evaluate human alignment in LLMs for both English and Chinese. We also analyze the feasibility of automating parts of evaluation with a strong LLM (GPT-4). Our framework supports a thorough assessment of LLMs as they are integrated into real-world applications. We have made publicly available the task tree, TencentLLMEval dataset, and evaluation methodology which have been demonstrated as effective in assessing the performance of Tencent Hunyuan LLMs. By doing so, we aim to facilitate the benchmarking of advances in the development of safe and human-aligned LLMs.