 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Policy-Transition Optimization for Fast Policy Transfer
Paper and Code
Jun 13, 2022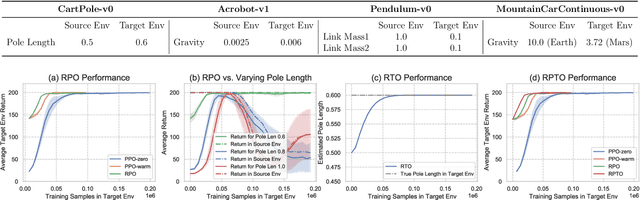
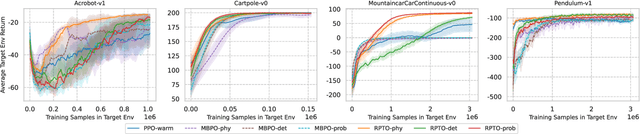
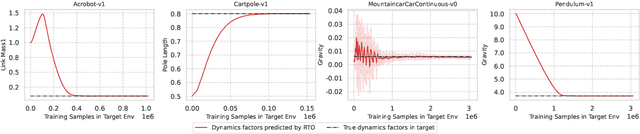
We consider the problem of policy transfer between two Markov Decision Processes (MDPs). We introduce a lemma based on existing theoretical results in reinforcement learning (RL) to measure the relativity between two arbitrary MDPs, that is the difference between any two cumulative expected returns defined on different policies and environment dynamics. Based on this lemma, we propose two new algorithms referred to as Relative Policy Optimization (RPO) and Relative Transition Optimization (RTO), which can offer fast policy transfer and dynamics modeling, respectively. RPO updates the policy using the relative policy gradient to transfer the policy evaluated in one environment to maximize the return in another, while RTO updates the parameterized dynamics model (if there exists) using the relative transition gradient to reduce the gap between the dynamics of the two environments. Then, integrating the two algorithms offers the complete algorithm Relative Policy-Transition Optimization (RPTO), in which the policy interacts with the two environments simultaneously, such that data collections from two environments, policy and transition updates are completed in one closed loop to form a principled learning framework for policy transfer. We demonstrate the effectiveness of RPTO in OpenAI gym's classic control tasks by creating policy transfer problems via variant dynamics.