 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative-Competitive Team Play of Real-World Craft Robots
Feb 24, 2026Multi-agent deep Reinforcement Learning (RL) has made significant progress in developing intelligent game-playing agents in recent years. However, the efficient training of collective robots using multi-agent RL and the transfer of learned policies to real-world applications remain open research questions. In this work, we first develop a comprehensive robotic system, including simulation, distributed learning framework, and physical robot components. We then propose and evaluate reinforcement learning techniques designed for efficient training of cooperative and competitive policies on this platform. To address the challenges of multi-agent sim-to-real transfer, we introduce Out of Distribution State Initialization (OODSI) to mitigate the impact of the sim-to-real gap. In the experiments, OODSI improves the Sim2Real performance by 20%. We demonstrate the effectiveness of our approach through experiments with a multi-robot car competitive game and a cooperative task in real-world settings.
AgentWorld: An Interactive Simulation Platform for Scene Construction and Mobile Robotic Manipulation
Aug 13, 2025We introduce AgentWorld, an interactive simulation platform for developing household mobile manipulation capabilities. Our platform combines automated scene construction that encompasses layout generation, semantic asset placement, visual material configuration, and physics simulation, with a dual-mode teleoperation system supporting both wheeled bases and humanoid locomotion policies for data collection. The resulting AgentWorld Dataset captures diverse tasks ranging from primitive actions (pick-and-place, push-pull, etc.) to multistage activities (serve drinks, heat up food, etc.) across living rooms, bedrooms, and kitchens. Through extensive benchmarking of imitation learning methods including behavior cloning, action chunking transformers, diffusion policies, and vision-language-action models, we demonstrate the dataset's effectiveness for sim-to-real transfer. The integrated system provides a comprehensive solution for scalable robotic skill acquisition in complex home environments, bridging the gap between simulation-based training and real-world deployment. The code, datasets will be available at https://yizhengzhang1.github.io/agent_world/
HumanVLA: Towards Vision-Language Directed Object Rearrangement by Physical Humanoid
Jun 28, 2024Physical Human-Scene Interaction (HSI) plays a crucial role in numerous applications. However, existing HSI techniques are limited to specific object dynamics and privileged information, which prevents the development of more comprehensive applications. To address this limitation, we introduce HumanVLA for general object rearrangement directed by practical vision and language. A teacher-student framework is utilized to develop HumanVLA. A state-based teacher policy is trained first using goal-conditioned reinforcement learning and adversarial motion prior. Then, it is distilled into a vision-language-action model via behavior cloning. We propose several key insights to facilitate the large-scale learning process. To support general object rearrangement by physical humanoid, we introduce a novel Human-in-the-Room dataset encompassing various rearrangement tasks. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed approach.
Learning Highly Dynamic Behaviors for Quadrupedal Robots
Feb 21, 2024Learning highly dynamic behaviors for robots has been a longstanding challenge. Traditional approaches have demonstrated robust locomotion, but the exhibited behaviors lack diversity and agility. They employ approximate models, which lead to compromises in performance. Data-driven approaches have been shown to reproduce agile behaviors of animals, but typically have not been able to learn highly dynamic behaviors. In this paper, we propose a learning-based approach to enable robots to learn highly dynamic behaviors from animal motion data. The learned controller is deployed on a quadrupedal robot and the results show that the controller is able to reproduce highly dynamic behaviors including sprinting, jumping and sharp turning. Various behaviors can be activated through human interaction using a stick with markers attached to it. Based on the motion pattern of the stick, the robot exhibits walking, running, sitting and jumping, much like the way humans interact with a pet.
Lifelike Agility and Play on Quadrupedal Robots using Reinforcement Learning and Generative Pre-trained Models
Aug 29, 2023Summarizing knowledge from animals and human beings inspires robotic innovations. In this work, we propose a framework for driving legged robots act like real animals with lifelike agility and strategy in complex environments. Inspired by large pre-trained models witnessed with impressive performance in language and image understanding, we introduce the power of advanced deep generative models to produce motor control signals stimulating legged robots to act like real animals. Unlike conventional controllers and end-to-end RL methods that are task-specific, we propose to pre-train generative models over animal motion datasets to preserve expressive knowledge of animal behavior. The pre-trained model holds sufficient primitive-level knowledge yet is environment-agnostic. It is then reused for a successive stage of learning to align with the environments by traversing a number of challenging obstacles that are rarely considered in previous approaches, including creeping through narrow spaces, jumping over hurdles, freerunning over scattered blocks, etc. Finally, a task-specific controller is trained to solve complex downstream tasks by reusing the knowledge from previous stages. Enriching the knowledge regarding each stage does not affect the usage of other levels of knowledge. This flexible framework offers the possibility of continual knowledge accumulation at different levels. We successfully apply the trained multi-level controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles, and play in a designed challenging multi-agent Chase Tag Game, where lifelike agility and strategy emerge on the robots. The present research pushes the frontier of robot control with new insights on reusing multi-level pre-trained knowledge and solving highly complex downstream tasks in the real world.
Learning Terrain-Adaptive Locomotion with Agile Behaviors by Imitating Animals
Aug 07, 2023
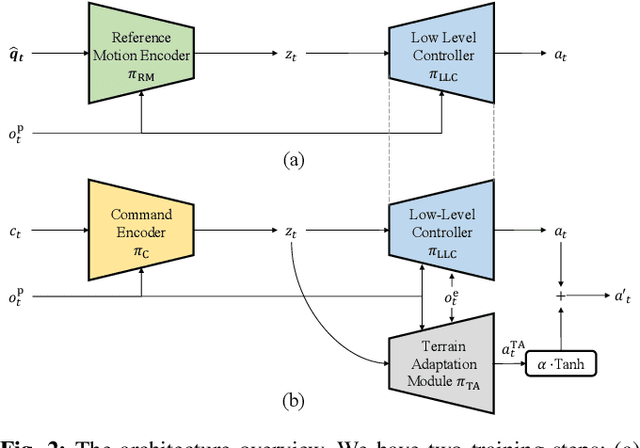
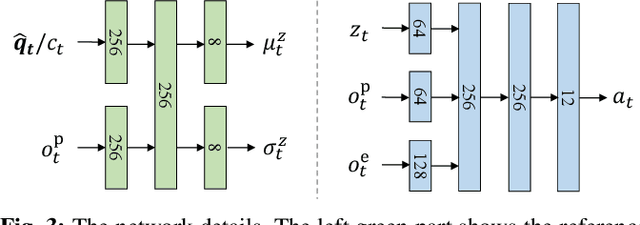
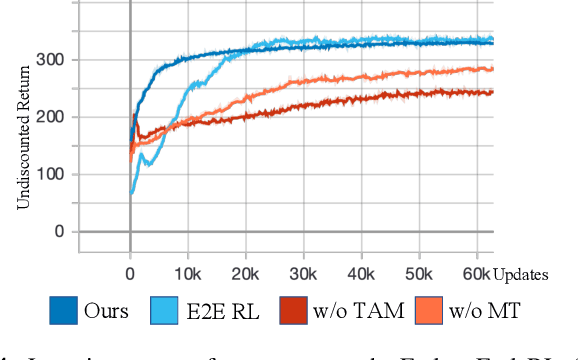
In this paper, we present a general learning framework for controlling a quadruped robot that can mimic the behavior of real animals and traverse challenging terrains. Our method consists of two steps: an imitation learning step to learn from motions of real animals, and a terrain adaptation step to enable generalization to unseen terrains. We capture motions from a Labrador on various terrains to facilitate terrain adaptive locomotion. Our experiments demonstrate that our policy can traverse various terrains and produce a natural-looking behavior. We deployed our method on the real quadruped robot Max via zero-shot simulation-to-reality transfer, achieving a speed of 1.1 m/s on stairs climbing.
Relative Policy-Transition Optimization for Fast Policy Transfer
Jun 13, 2022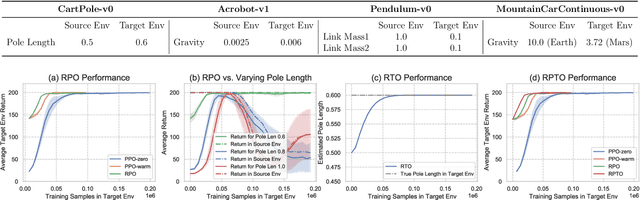
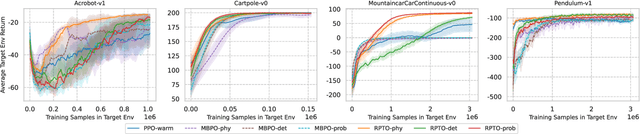
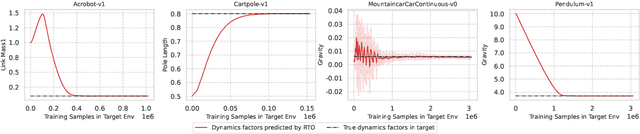
We consider the problem of policy transfer between two Markov Decision Processes (MDPs). We introduce a lemma based on existing theoretical results in reinforcement learning (RL) to measure the relativity between two arbitrary MDPs, that is the difference between any two cumulative expected returns defined on different policies and environment dynamics. Based on this lemma, we propose two new algorithms referred to as Relative Policy Optimization (RPO) and Relative Transition Optimization (RTO), which can offer fast policy transfer and dynamics modeling, respectively. RPO updates the policy using the relative policy gradient to transfer the policy evaluated in one environment to maximize the return in another, while RTO updates the parameterized dynamics model (if there exists) using the relative transition gradient to reduce the gap between the dynamics of the two environments. Then, integrating the two algorithms offers the complete algorithm Relative Policy-Transition Optimization (RPTO), in which the policy interacts with the two environments simultaneously, such that data collections from two environments, policy and transition updates are completed in one closed loop to form a principled learning framework for policy transfer. We demonstrate the effectiveness of RPTO in OpenAI gym's classic control tasks by creating policy transfer problems via variant dynamics.
Tactical Reward Shaping: Bypassing Reinforcement Learning with Strategy-Based Goals
Oct 08, 2019

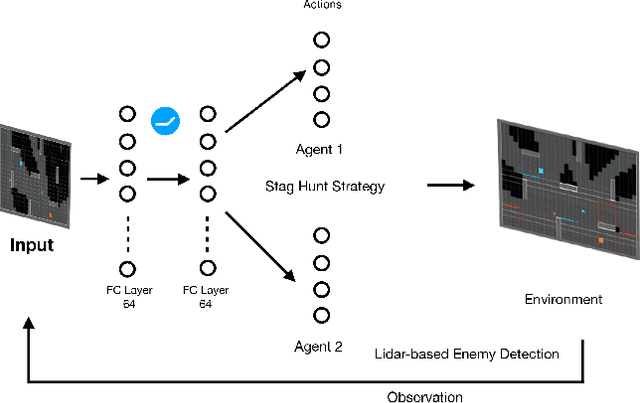
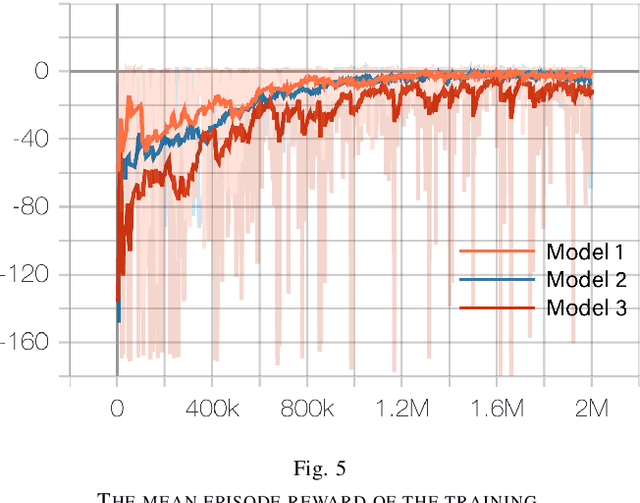
Deep Reinforcement Learning (DRL) has shown its promising capabilities to learn optimal policies directly from trial and error. However, learning can be hindered if the goal of the learning, defined by the reward function, is "not optimal". We demonstrate that by setting the goal/target of competition in a counter-intuitive but intelligent way, instead of heuristically trying solutions through many hours the DRL simulation can quickly converge into a winning strategy. The ICRA-DJI RoboMaster AI Challenge is a game of cooperation and competition between robots in a partially observable environment, quite similar to the Counter-Strike game. Unlike the traditional approach to games, where the reward is given at winning the match or hitting the enemy, our DRL algorithm rewards our robots when in a geometric-strategic advantage, which implicitly increases the winning chances. Furthermore, we use Deep Q Learning (DQL) to generate multi-agent paths for moving, which improves the cooperation between two robots by avoiding the collision. Finally, we implement a variant A* algorithm with the same implicit geometric goal as DQL and compare results. We conclude that a well-set goal can put in question the need for learning algorithms, with geometric-based searches outperforming DQL in many orders of magnitude.