 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-based Scene Layout Generation from Human Motion
May 21, 2024



Creating scenes for captured motions that achieve realistic human-scene interaction is crucial for 3D animation in movies or video games. As character motion is often captured in a blue-screened studio without real furniture or objects in place, there may be a discrepancy between the planned motion and the captured one. This gives rise to the need for automatic scene layout generation to relieve the burdens of selecting and positioning furniture and objects. Previous approaches cannot avoid artifacts like penetration and floating due to the lack of physical constraints. Furthermore, some heavily rely on specific data to learn the contact affordances, restricting the generalization ability to different motions. In this work, we present a physics-based approach that simultaneously optimizes a scene layout generator and simulates a moving human in a physics simulator. To attain plausible and realistic interaction motions, our method explicitly introduces physical constraints. To automatically recover and generate the scene layout, we minimize the motion tracking errors to identify the objects that can afford interaction. We use reinforcement learning to perform a dual-optimization of both the character motion imitation controller and the scene layout generator. To facilitate the optimization, we reshape the tracking rewards and devise pose prior guidance obtained from our estimated pseudo-contact labels. We evaluate our method using motions from SAMP and PROX, and demonstrate physically plausible scene layout reconstruction compared with the previous kinematics-based method.
An Efficient Model-Based Approach on Learning Agile Motor Skills without Reinforcement
Mar 04, 2024
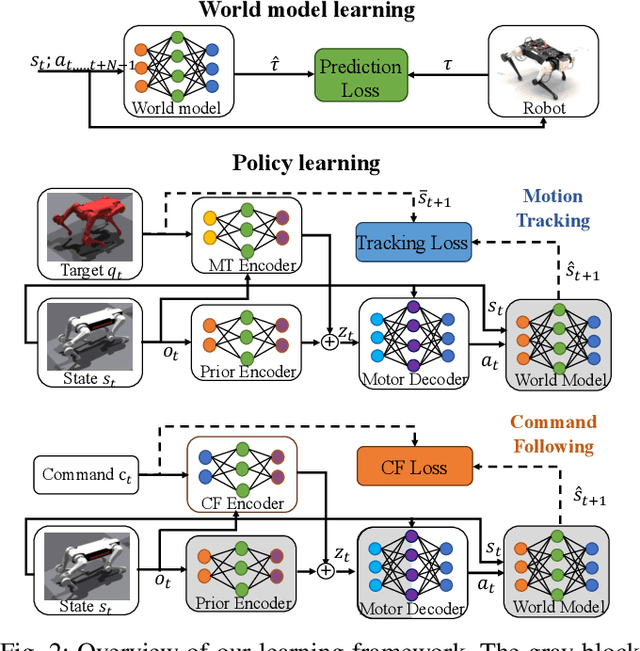
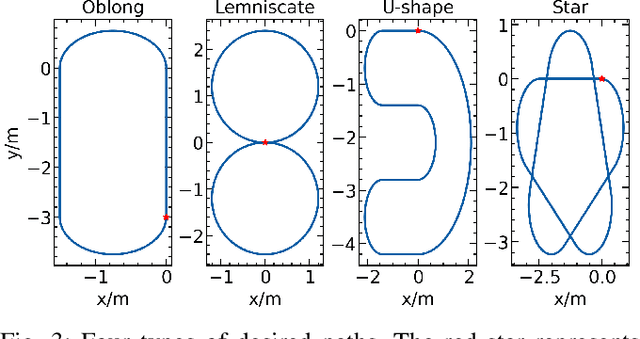
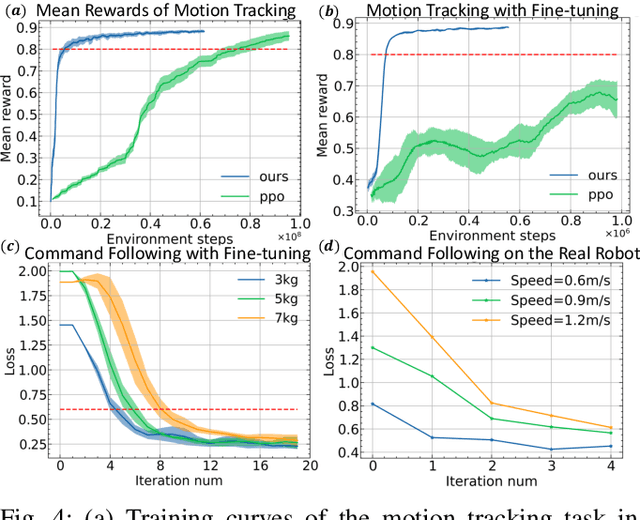
Learning-based methods have improved locomotion skills of quadruped robots through deep reinforcement learning. However, the sim-to-real gap and low sample efficiency still limit the skill transfer. To address this issue, we propose an efficient model-based learning framework that combines a world model with a policy network. We train a differentiable world model to predict future states and use it to directly supervise a Variational Autoencoder (VAE)-based policy network to imitate real animal behaviors. This significantly reduces the need for real interaction data and allows for rapid policy updates. We also develop a high-level network to track diverse commands and trajectories. Our simulated results show a tenfold sample efficiency increase compared to reinforcement learning methods such as PPO. In real-world testing, our policy achieves proficient command-following performance with only a two-minute data collection period and generalizes well to new speeds and paths.
Learning Highly Dynamic Behaviors for Quadrupedal Robots
Feb 21, 2024Learning highly dynamic behaviors for robots has been a longstanding challenge. Traditional approaches have demonstrated robust locomotion, but the exhibited behaviors lack diversity and agility. They employ approximate models, which lead to compromises in performance. Data-driven approaches have been shown to reproduce agile behaviors of animals, but typically have not been able to learn highly dynamic behaviors. In this paper, we propose a learning-based approach to enable robots to learn highly dynamic behaviors from animal motion data. The learned controller is deployed on a quadrupedal robot and the results show that the controller is able to reproduce highly dynamic behaviors including sprinting, jumping and sharp turning. Various behaviors can be activated through human interaction using a stick with markers attached to it. Based on the motion pattern of the stick, the robot exhibits walking, running, sitting and jumping, much like the way humans interact with a pet.
Terrain-Aware Quadrupedal Locomotion via Reinforcement Learning
Oct 11, 2023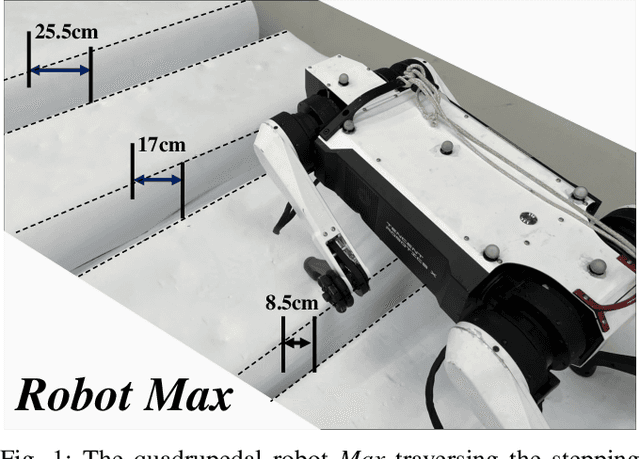
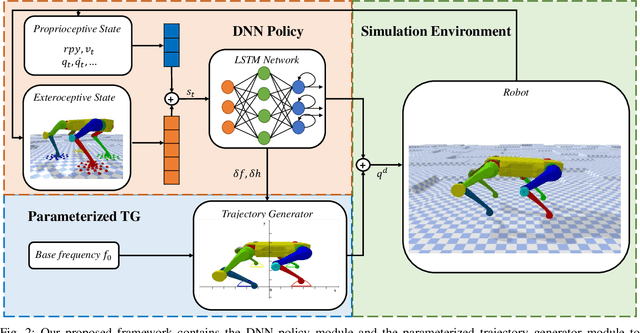
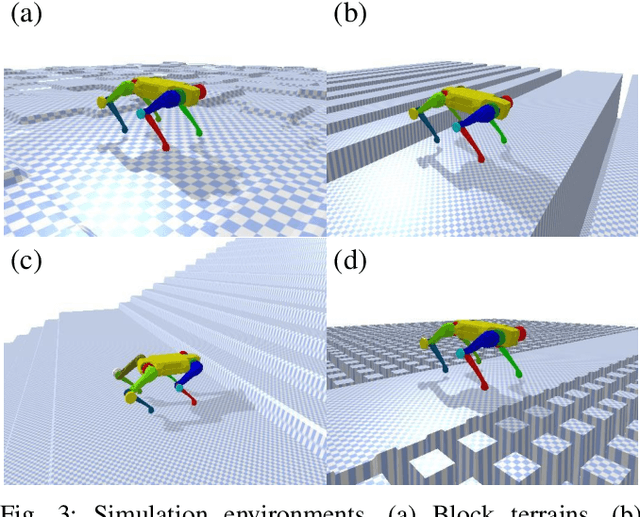
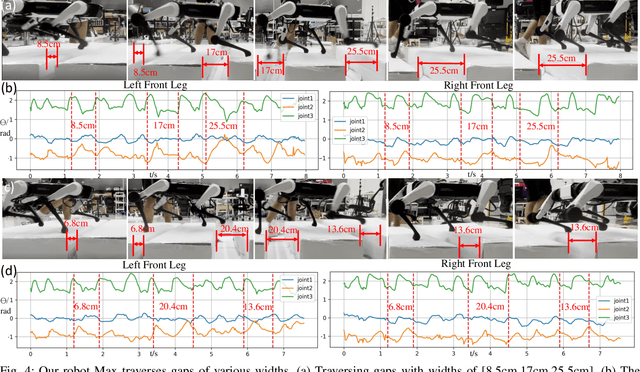
In nature, legged animals have developed the ability to adapt to challenging terrains through perception, allowing them to plan safe body and foot trajectories in advance, which leads to safe and energy-efficient locomotion. Inspired by this observation, we present a novel approach to train a Deep Neural Network (DNN) policy that integrates proprioceptive and exteroceptive states with a parameterized trajectory generator for quadruped robots to traverse rough terrains. Our key idea is to use a DNN policy that can modify the parameters of the trajectory generator, such as foot height and frequency, to adapt to different terrains. To encourage the robot to step on safe regions and save energy consumption, we propose foot terrain reward and lifting foot height reward, respectively. By incorporating these rewards, our method can learn a safer and more efficient terrain-aware locomotion policy that can move a quadruped robot flexibly in any direction. To evaluate the effectiveness of our approach, we conduct simulation experiments on challenging terrains, including stairs, stepping stones, and poles. The simulation results demonstrate that our approach can successfully direct the robot to traverse such tough terrains in any direction. Furthermore, we validate our method on a real legged robot, which learns to traverse stepping stones with gaps over 25.5cm.
Lifelike Agility and Play on Quadrupedal Robots using Reinforcement Learning and Generative Pre-trained Models
Aug 29, 2023Summarizing knowledge from animals and human beings inspires robotic innovations. In this work, we propose a framework for driving legged robots act like real animals with lifelike agility and strategy in complex environments. Inspired by large pre-trained models witnessed with impressive performance in language and image understanding, we introduce the power of advanced deep generative models to produce motor control signals stimulating legged robots to act like real animals. Unlike conventional controllers and end-to-end RL methods that are task-specific, we propose to pre-train generative models over animal motion datasets to preserve expressive knowledge of animal behavior. The pre-trained model holds sufficient primitive-level knowledge yet is environment-agnostic. It is then reused for a successive stage of learning to align with the environments by traversing a number of challenging obstacles that are rarely considered in previous approaches, including creeping through narrow spaces, jumping over hurdles, freerunning over scattered blocks, etc. Finally, a task-specific controller is trained to solve complex downstream tasks by reusing the knowledge from previous stages. Enriching the knowledge regarding each stage does not affect the usage of other levels of knowledge. This flexible framework offers the possibility of continual knowledge accumulation at different levels. We successfully apply the trained multi-level controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles, and play in a designed challenging multi-agent Chase Tag Game, where lifelike agility and strategy emerge on the robots. The present research pushes the frontier of robot control with new insights on reusing multi-level pre-trained knowledge and solving highly complex downstream tasks in the real world.
Neural Categorical Priors for Physics-Based Character Control
Aug 14, 2023Recent advances in learning reusable motion priors have demonstrated their effectiveness in generating naturalistic behaviors. In this paper, we propose a new learning framework in this paradigm for controlling physics-based characters with significantly improved motion quality and diversity over existing state-of-the-art methods. The proposed method uses reinforcement learning (RL) to initially track and imitate life-like movements from unstructured motion clips using the discrete information bottleneck, as adopted in the Vector Quantized Variational AutoEncoder (VQ-VAE). This structure compresses the most relevant information from the motion clips into a compact yet informative latent space, i.e., a discrete space over vector quantized codes. By sampling codes in the space from a trained categorical prior distribution, high-quality life-like behaviors can be generated, similar to the usage of VQ-VAE in computer vision. Although this prior distribution can be trained with the supervision of the encoder's output, it follows the original motion clip distribution in the dataset and could lead to imbalanced behaviors in our setting. To address the issue, we further propose a technique named prior shifting to adjust the prior distribution using curiosity-driven RL. The outcome distribution is demonstrated to offer sufficient behavioral diversity and significantly facilitates upper-level policy learning for downstream tasks. We conduct comprehensive experiments using humanoid characters on two challenging downstream tasks, sword-shield striking and two-player boxing game. Our results demonstrate that the proposed framework is capable of controlling the character to perform considerably high-quality movements in terms of behavioral strategies, diversity, and realism. Videos, codes, and data are available at https://tencent-roboticsx.github.io/NCP/.
Learning Terrain-Adaptive Locomotion with Agile Behaviors by Imitating Animals
Aug 07, 2023
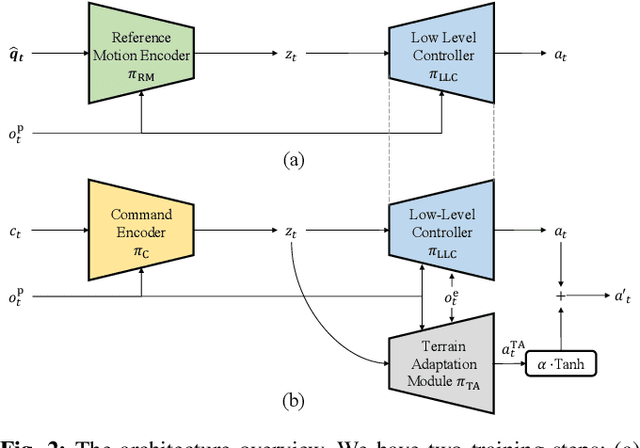
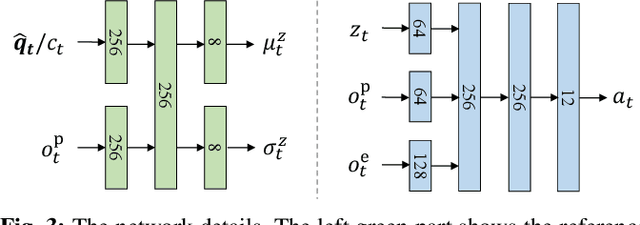
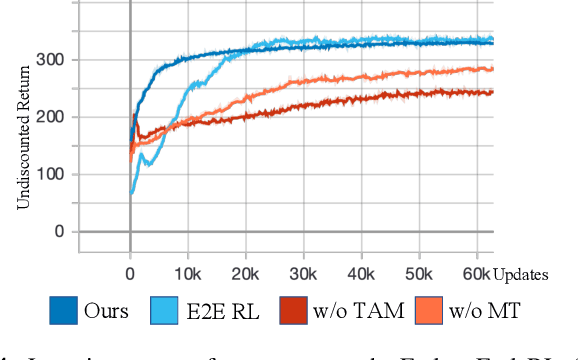
In this paper, we present a general learning framework for controlling a quadruped robot that can mimic the behavior of real animals and traverse challenging terrains. Our method consists of two steps: an imitation learning step to learn from motions of real animals, and a terrain adaptation step to enable generalization to unseen terrains. We capture motions from a Labrador on various terrains to facilitate terrain adaptive locomotion. Our experiments demonstrate that our policy can traverse various terrains and produce a natural-looking behavior. We deployed our method on the real quadruped robot Max via zero-shot simulation-to-reality transfer, achieving a speed of 1.1 m/s on stairs climbing.