 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniWheg: An Omnidirectional Wheel-Leg Transformable Robot
Mar 04, 2022
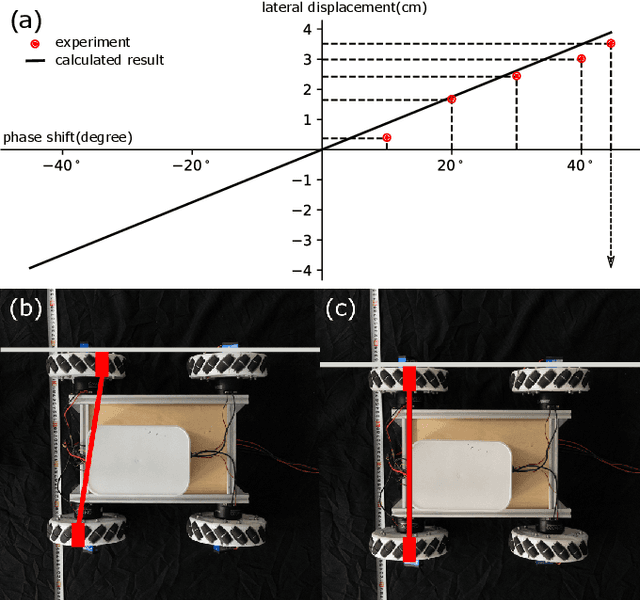
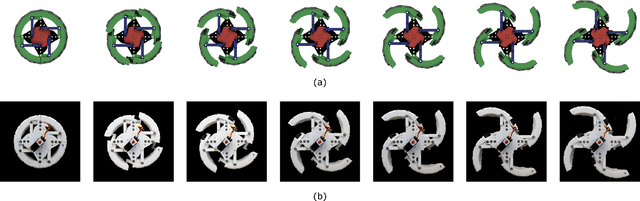
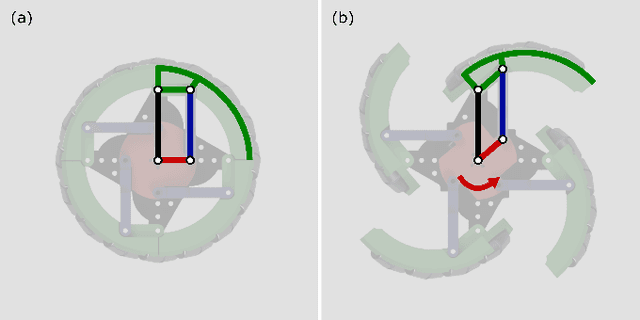
This paper presents the design, analysis, and performance evaluation of an omnidirectional transformable wheel-leg robot called OmniWheg. We design a novel mechanism consisting of a separable Omni-wheel and 4-bar linkages, allowing the robot to transform between Omni-wheeled and legged modes smoothly. On wheeled mode, the robot can move in all directions and efficiently adjust the relative position of its wheels, while it can overcome common obstacles in legged mode, such as stairs and steps. Unlike other articles studying whegs, this implementation with omnidirectional wheels allows the correction of misalignments between right and left wheels before traversing obstacles, which effectively improves the success rate and simplifies the preparation process before the wheel-leg transformation. We describe the design concept, mechanism, and the dynamic characteristic of the wheel-leg structure. We then evaluate its performance in various scenarios, including passing obstacles, climbing steps of different heights, and turning/moving omnidirectionally. Our results confirm that this mobile platform can overcome common indoor obstacles and move flexibly on the flat ground with the new transformable wheel-leg mechanism, while keeping a high degree of stability.
Multi-Modal Legged Locomotion Framework with Automated Residual Reinforcement Learning
Feb 24, 2022

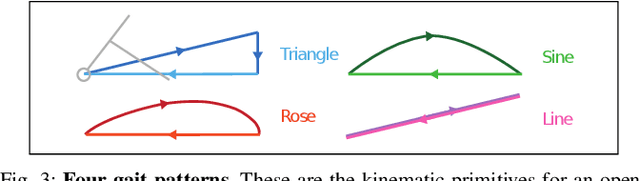

While quadruped robots usually have good stability and load capacity, bipedal robots offer a higher level of flexibility / adaptability to different tasks and environments. A multi-modal legged robot can take the best of both worlds. In this paper, we propose a multi-modal locomotion framework that is composed of a hand-crafted transition motion and a learning-based bipedal controller -- learnt by a novel algorithm called Automated Residual Reinforcement Learning. This framework aims to endow arbitrary quadruped robots with the ability to walk bipedally. In particular, we 1) design an additional supporting structure for a quadruped robot and a sequential multi-modal transition strategy; 2) propose a novel class of Reinforcement Learning algorithms for bipedal control and evaluate their performances in both simulation and the real world. Experimental results show that our proposed algorithms have the best performance in simulation and maintain a good performance in a real-world robot. Overall, our multi-modal robot could successfully switch between biped and quadruped, and walk in both modes. Experiment videos and code are available at https://chenaah.github.io/multimodal/.
Rearranging the Environment to Maximize Energy with a Robotic Circuit Drawing
Nov 15, 2021
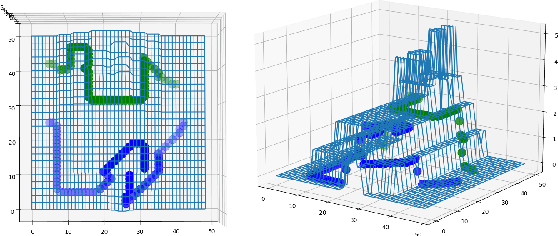

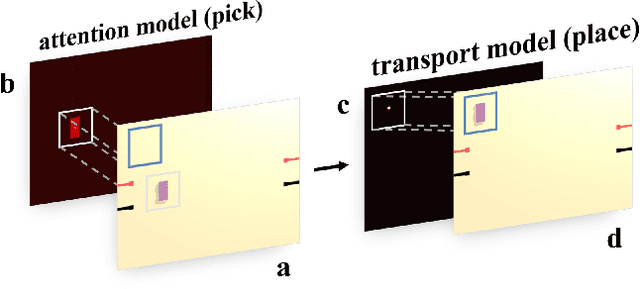
Robots with the ability to actively acquire power from surroundings will be greatly beneficial for long-term autonomy and to survive in uncertain environments. In this work, we present a robot capable of drawing circuits with conductive ink while also rearranging the visual world to receive maximum energy from a power source. A range of circuit drawing tasks is designed to simulate real-world scenarios, including avoiding physical obstacles and regions that would discontinue drawn circuits. We adopt the state-of-the-art Transporter networks for pick-and-place manipulation from visual observation. We conduct experiments in both simulation and real-world settings, and our results show that, with a small number of demonstrations, the robot learns to rearrange the placement of objects (removing obstacles and bridging areas unsuitable for drawing) and to connect a power source with a minimum amount of conductive ink. As autonomous robots become more present, in our houses and other planets, our proposed method brings a novel way for machines to keep themselves functional by rearranging their surroundings to create their own electric circuits.
Scaffolded Gait Learning of a Quadruped Robot with Bayesian Optimization
Jan 25, 2021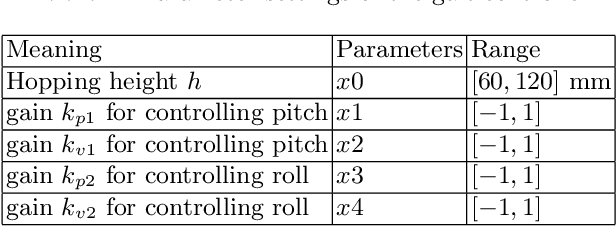
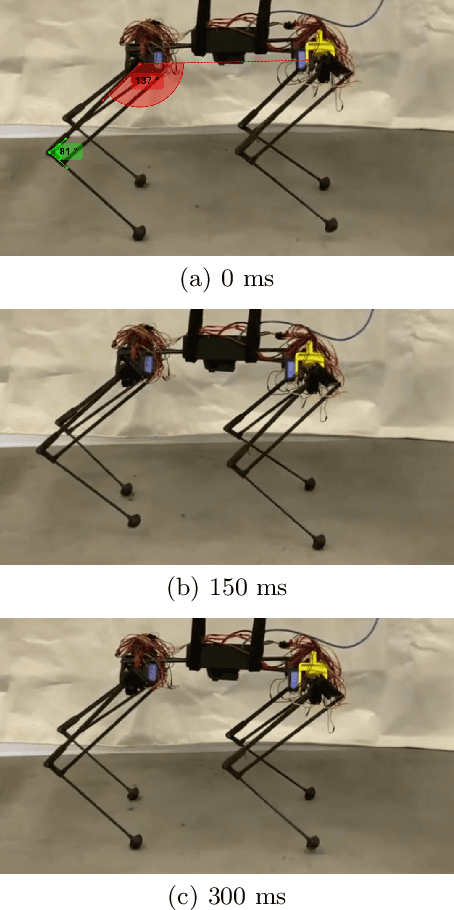
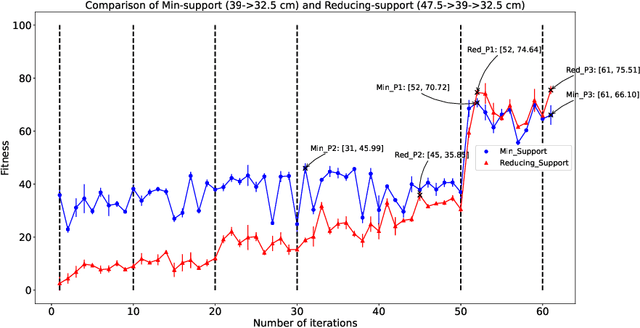

During learning trials, systems are exposed to different failure conditions which may break robotic parts before a safe behavior is discovered. Humans contour this problem by grounding their learning to a safer structure/control first and gradually increasing its difficulty. This paper presents the impact of a similar supports in the learning of a stable gait on a quadruped robot. Based on the psychological theory of instructional scaffolding, we provide different support settings to our robot, evaluated with strain gauges, and use Bayesian Optimization to conduct a parametric search towards a stable Raibert controller. We perform several experiments to measure the relation between constant supports and gradually reduced supports during gait learning, and our results show that a gradually reduced support is capable of creating a more stable gait than a support at a fixed height. Although gaps between simulation and reality can lead robots to catastrophic failures, our proposed method combines speed and safety when learning a new behavior.
Proximal Policy Optimization Smoothed Algorithm
Dec 04, 2020


Proximal policy optimization (PPO) has yielded state-of-the-art results in policy search, a subfield of reinforcement learning, with one of its key points being the use of a surrogate objective function to restrict the step size at each policy update. Although such restriction is helpful, the algorithm still suffers from performance instability and optimization inefficiency from the sudden flattening of the curve. To address this issue we present a PPO variant, named Proximal Policy Optimization Smooth Algorithm (PPOS), and its critical improvement is the use of a functional clipping method instead of a flat clipping method. We compare our method with PPO and PPORB, which adopts a rollback clipping method, and prove that our method can conduct more accurate updates at each time step than other PPO methods. Moreover, we show that it outperforms the latest PPO variants on both performance and stability in challenging continuous control tasks.
CircuitBot: Learning to Survive with Robotic Circuit Drawing
Nov 10, 2020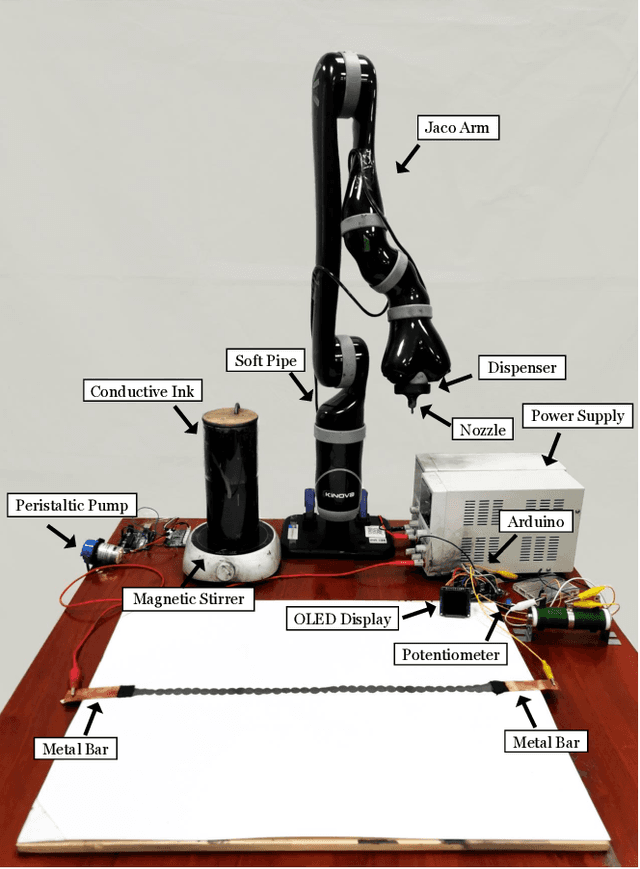

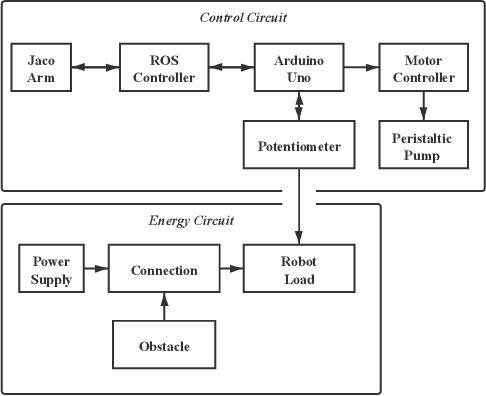
Robots with the ability to actively acquire power from surroundings will be greatly beneficial for long-term autonomy, and to survive in dynamic, uncertain environments. In this work, a scenario is presented where a robot has limited energy, and the only way to survive is to access the energy from a power source. With no cables or wires available, the robot learns to construct an electrical path and avoid potential obstacles during the connection. We present this robot, capable of drawing connected circuit patterns with graphene-based conductive ink. A state-of-the-art Mix-Variable Bayesian Optimization is adopted to optimize the placement of conductive shapes to maximize the power this robot receives. Our results show that, within a small number of trials, the robot learns to build parallel circuits to maximize the voltage received and avoid obstacles which steal energy from the robot.
Deep vs. Deep Bayesian: Reinforcement Learning on a Multi-Robot Competitive Experiment
Jul 21, 2020
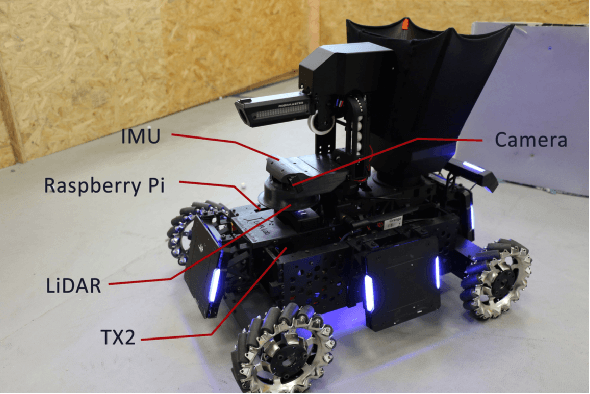
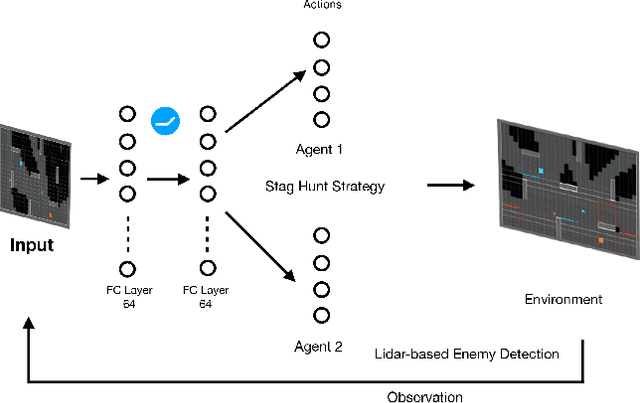
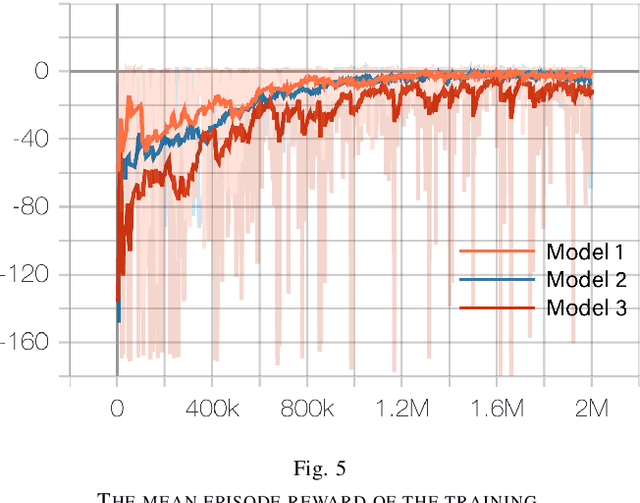
Deep Reinforcement Learning (RL) experiments are commonly performed in simulated environment, due to the tremendous training sample demand from deep neural networks. However, model-based Deep Bayesian RL, such as Deep PILCO, allows a robot to learn good policies within few trials in the real world. Although Deep PILCO has been applied on many single-robot tasks, in here we propose, for the first time, an application of Deep PILCO on a multi-robot confrontation game, and compare the algorithm with a model-free Deep RL algorithm, Deep Q-Learning. Our experiments show that Deep PILCO significantly outperforms Deep Q-Learning in learning efficiency and scalability. We conclude that sample-efficient Deep Bayesian learning algorithms have great prospects on competitive games where the agent aims to win the opponents in the real world, as opposed to simulated applications.
Tactical Reward Shaping: Bypassing Reinforcement Learning with Strategy-Based Goals
Oct 08, 2019

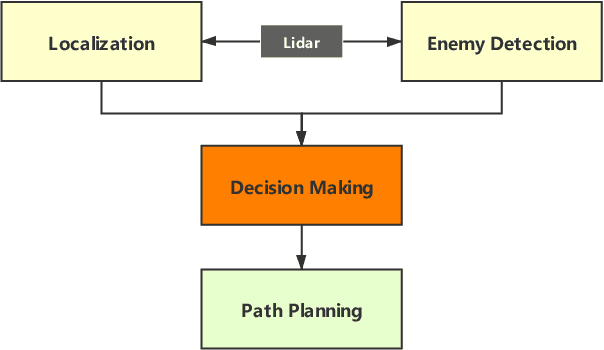
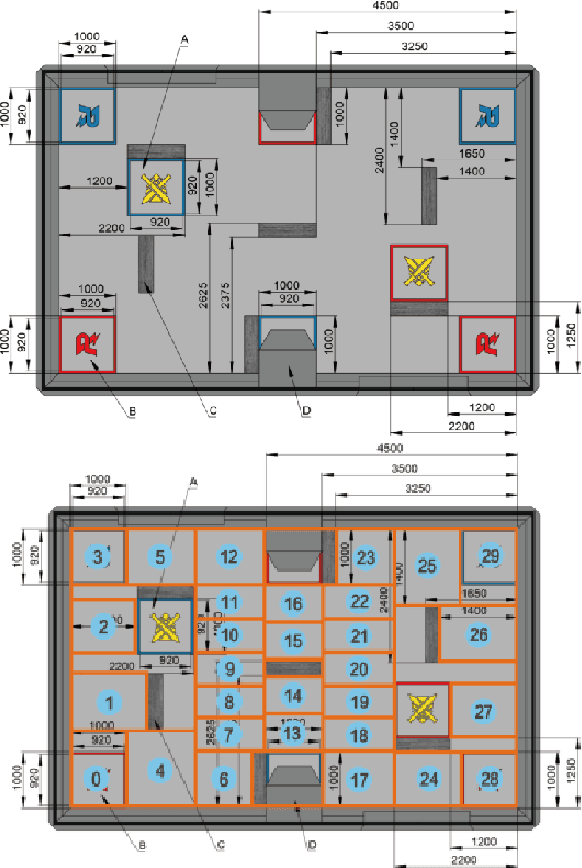
Deep Reinforcement Learning (DRL) has shown its promising capabilities to learn optimal policies directly from trial and error. However, learning can be hindered if the goal of the learning, defined by the reward function, is "not optimal". We demonstrate that by setting the goal/target of competition in a counter-intuitive but intelligent way, instead of heuristically trying solutions through many hours the DRL simulation can quickly converge into a winning strategy. The ICRA-DJI RoboMaster AI Challenge is a game of cooperation and competition between robots in a partially observable environment, quite similar to the Counter-Strike game. Unlike the traditional approach to games, where the reward is given at winning the match or hitting the enemy, our DRL algorithm rewards our robots when in a geometric-strategic advantage, which implicitly increases the winning chances. Furthermore, we use Deep Q Learning (DQL) to generate multi-agent paths for moving, which improves the cooperation between two robots by avoiding the collision. Finally, we implement a variant A* algorithm with the same implicit geometric goal as DQL and compare results. We conclude that a well-set goal can put in question the need for learning algorithms, with geometric-based searches outperforming DQL in many orders of magnitude.