 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Policy Optimization Smoothed Algorithm
Dec 04, 2020


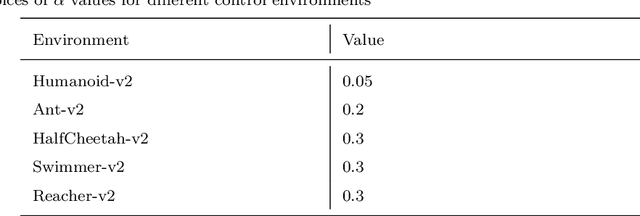
Proximal policy optimization (PPO) has yielded state-of-the-art results in policy search, a subfield of reinforcement learning, with one of its key points being the use of a surrogate objective function to restrict the step size at each policy update. Although such restriction is helpful, the algorithm still suffers from performance instability and optimization inefficiency from the sudden flattening of the curve. To address this issue we present a PPO variant, named Proximal Policy Optimization Smooth Algorithm (PPOS), and its critical improvement is the use of a functional clipping method instead of a flat clipping method. We compare our method with PPO and PPORB, which adopts a rollback clipping method, and prove that our method can conduct more accurate updates at each time step than other PPO methods. Moreover, we show that it outperforms the latest PPO variants on both performance and stability in challenging continuous control tasks.