 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceCam: Portrait Video Camera Control via Scale-Aware Conditioning
Mar 05, 2026We introduce FaceCam, a system that generates video under customizable camera trajectories for monocular human portrait video input. Recent camera control approaches based on large video-generation models have shown promising progress but often exhibit geometric distortions and visual artifacts on portrait videos due to scale-ambiguous camera representations or 3D reconstruction errors. To overcome these limitations, we propose a face-tailored scale-aware representation for camera transformations that provides deterministic conditioning without relying on 3D priors. We train a video generation model on both multi-view studio captures and in-the-wild monocular videos, and introduce two camera-control data generation strategies: synthetic camera motion and multi-shot stitching, to exploit stationary training cameras while generalizing to dynamic, continuous camera trajectories at inference time. Experiments on Ava-256 dataset and diverse in-the-wild videos demonstrate that FaceCam achieves superior performance in camera controllability, visual quality, identity and motion preservation.
Edit3r: Instant 3D Scene Editing from Sparse Unposed Images
Dec 31, 2025We present Edit3r, a feed-forward framework that reconstructs and edits 3D scenes in a single pass from unposed, view-inconsistent, instruction-edited images. Unlike prior methods requiring per-scene optimization, Edit3r directly predicts instruction-aligned 3D edits, enabling fast and photorealistic rendering without optimization or pose estimation. A key challenge in training such a model lies in the absence of multi-view consistent edited images for supervision. We address this with (i) a SAM2-based recoloring strategy that generates reliable, cross-view-consistent supervision, and (ii) an asymmetric input strategy that pairs a recolored reference view with raw auxiliary views, encouraging the network to fuse and align disparate observations. At inference, our model effectively handles images edited by 2D methods such as InstructPix2Pix, despite not being exposed to such edits during training. For large-scale quantitative evaluation, we introduce DL3DV-Edit-Bench, a benchmark built on the DL3DV test split, featuring 20 diverse scenes, 4 edit types and 100 edits in total. Comprehensive quantitative and qualitative results show that Edit3r achieves superior semantic alignment and enhanced 3D consistency compared to recent baselines, while operating at significantly higher inference speed, making it promising for real-time 3D editing applications.
Efficient Code LLM Training via Distribution-Consistent and Diversity-Aware Data Selection
Jul 03, 2025Recent advancements in large language models (LLMs) have significantly improved code generation and program comprehension, accelerating the evolution of software engineering. Current methods primarily enhance model performance by leveraging vast amounts of data, focusing on data quantity while often overlooking data quality, thereby reducing training efficiency. To address this, we introduce an approach that utilizes a parametric model for code data selection, aimed at improving both training efficiency and model performance. Our method optimizes the parametric model to ensure distribution consistency and diversity within the selected subset, guaranteeing high-quality data. Experimental results demonstrate that using only 10K samples, our method achieves gains of 2.4% (HumanEval) and 2.3% (MBPP) over 92K full-sampled baseline, outperforming other sampling approaches in both performance and efficiency. This underscores that our method effectively boosts model performance while significantly reducing computational costs.
HoliGS: Holistic Gaussian Splatting for Embodied View Synthesis
Jun 24, 2025We propose HoliGS, a novel deformable Gaussian splatting framework that addresses embodied view synthesis from long monocular RGB videos. Unlike prior 4D Gaussian splatting and dynamic NeRF pipelines, which struggle with training overhead in minute-long captures, our method leverages invertible Gaussian Splatting deformation networks to reconstruct large-scale, dynamic environments accurately. Specifically, we decompose each scene into a static background plus time-varying objects, each represented by learned Gaussian primitives undergoing global rigid transformations, skeleton-driven articulation, and subtle non-rigid deformations via an invertible neural flow. This hierarchical warping strategy enables robust free-viewpoint novel-view rendering from various embodied camera trajectories by attaching Gaussians to a complete canonical foreground shape (\eg, egocentric or third-person follow), which may involve substantial viewpoint changes and interactions between multiple actors. Our experiments demonstrate that \ourmethod~ achieves superior reconstruction quality on challenging datasets while significantly reducing both training and rendering time compared to state-of-the-art monocular deformable NeRFs. These results highlight a practical and scalable solution for EVS in real-world scenarios. The source code will be released.
InstaInpaint: Instant 3D-Scene Inpainting with Masked Large Reconstruction Model
Jun 12, 2025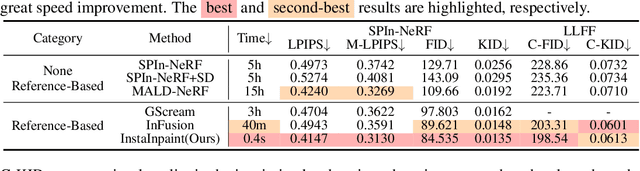


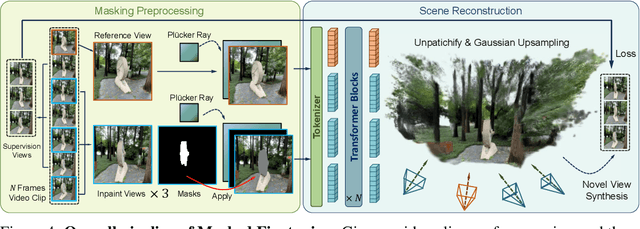
Recent advances in 3D scene reconstruction enable real-time viewing in virtual and augmented reality. To support interactive operations for better immersiveness, such as moving or editing objects, 3D scene inpainting methods are proposed to repair or complete the altered geometry. However, current approaches rely on lengthy and computationally intensive optimization, making them impractical for real-time or online applications. We propose InstaInpaint, a reference-based feed-forward framework that produces 3D-scene inpainting from a 2D inpainting proposal within 0.4 seconds. We develop a self-supervised masked-finetuning strategy to enable training of our custom large reconstruction model (LRM) on the large-scale dataset. Through extensive experiments, we analyze and identify several key designs that improve generalization, textural consistency, and geometric correctness. InstaInpaint achieves a 1000x speed-up from prior methods while maintaining a state-of-the-art performance across two standard benchmarks. Moreover, we show that InstaInpaint generalizes well to flexible downstream applications such as object insertion and multi-region inpainting. More video results are available at our project page: https://dhmbb2.github.io/InstaInpaint_page/.
FaceLift: Single Image to 3D Head with View Generation and GS-LRM
Dec 23, 2024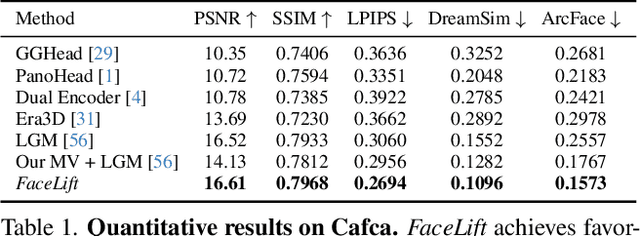

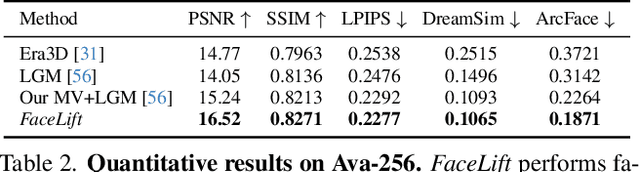
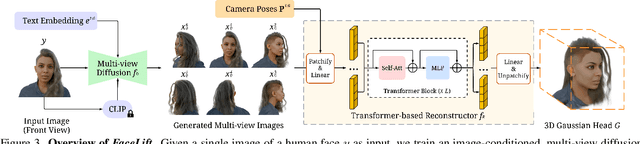
We present FaceLift, a feed-forward approach for rapid, high-quality, 360-degree head reconstruction from a single image. Our pipeline begins by employing a multi-view latent diffusion model that generates consistent side and back views of the head from a single facial input. These generated views then serve as input to a GS-LRM reconstructor, which produces a comprehensive 3D representation using Gaussian splats. To train our system, we develop a dataset of multi-view renderings using synthetic 3D human head as-sets. The diffusion-based multi-view generator is trained exclusively on synthetic head images, while the GS-LRM reconstructor undergoes initial training on Objaverse followed by fine-tuning on synthetic head data. FaceLift excels at preserving identity and maintaining view consistency across views. Despite being trained solely on synthetic data, FaceLift demonstrates remarkable generalization to real-world images. Through extensive qualitative and quantitative evaluations, we show that FaceLift outperforms state-of-the-art methods in 3D head reconstruction, highlighting its practical applicability and robust performance on real-world images. In addition to single image reconstruction, FaceLift supports video inputs for 4D novel view synthesis and seamlessly integrates with 2D reanimation techniques to enable 3D facial animation. Project page: https://weijielyu.github.io/FaceLift.
Gaga: Group Any Gaussians via 3D-aware Memory Bank
Apr 11, 2024



We introduce Gaga, a framework that reconstructs and segments open-world 3D scenes by leveraging inconsistent 2D masks predicted by zero-shot segmentation models. Contrasted to prior 3D scene segmentation approaches that heavily rely on video object tracking, Gaga utilizes spatial information and effectively associates object masks across diverse camera poses. By eliminating the assumption of continuous view changes in training images, Gaga demonstrates robustness to variations in camera poses, particularly beneficial for sparsely sampled images, ensuring precise mask label consistency. Furthermore, Gaga accommodates 2D segmentation masks from diverse sources and demonstrates robust performance with different open-world zero-shot segmentation models, enhancing its versatility. Extensive qualitative and quantitative evaluations demonstrate that Gaga performs favorably against state-of-the-art methods, emphasizing its potential for real-world applications such as scene understanding and manipulation.
PTT: Point-Trajectory Transformer for Efficient Temporal 3D Object Detection
Dec 13, 2023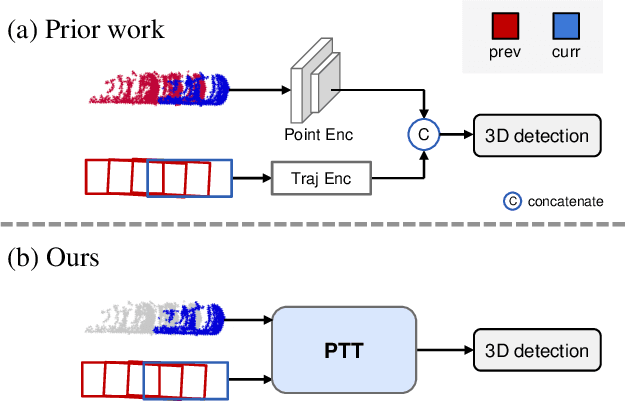
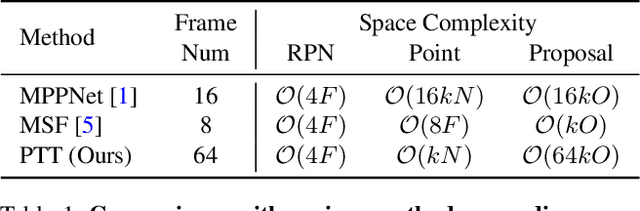
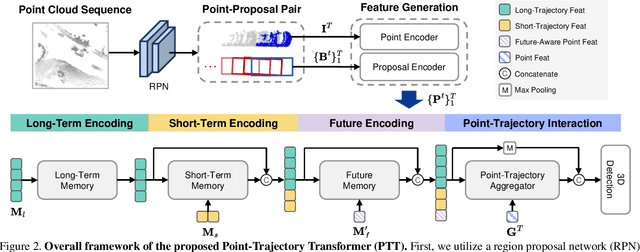
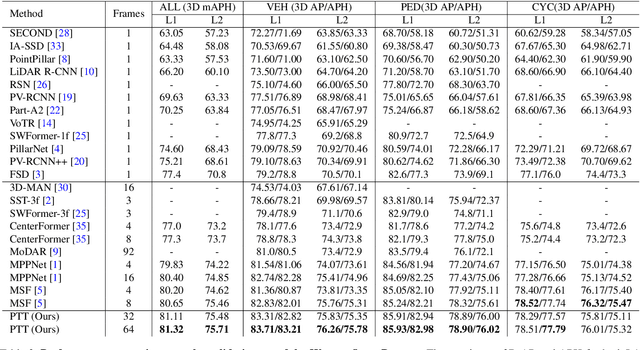
Recent temporal LiDAR-based 3D object detectors achieve promising performance based on the two-stage proposal-based approach. They generate 3D box candidates from the first-stage dense detector, followed by different temporal aggregation methods. However, these approaches require per-frame objects or whole point clouds, posing challenges related to memory bank utilization. Moreover, point clouds and trajectory features are combined solely based on concatenation, which may neglect effective interactions between them. In this paper, we propose a point-trajectory transformer with long short-term memory for efficient temporal 3D object detection. To this end, we only utilize point clouds of current-frame objects and their historical trajectories as input to minimize the memory bank storage requirement. Furthermore, we introduce modules to encode trajectory features, focusing on long short-term and future-aware perspectives, and then effectively aggregate them with point cloud features. We conduct extensive experiments on the large-scale Waymo dataset to demonstrate that our approach performs well against state-of-the-art methods. Code and models will be made publicly available at https://github.com/kuanchihhuang/PTT.
Continual Learning in Open-vocabulary Classification with Complementary Memory Systems
Jul 04, 2023We introduce a method for flexible continual learning in open-vocabulary image classification, drawing inspiration from the complementary learning systems observed in human cognition. We propose a "tree probe" method, an adaption of lazy learning principles, which enables fast learning from new examples with competitive accuracy to batch-trained linear models. Further, we propose a method to combine predictions from a CLIP zero-shot model and the exemplar-based model, using the zero-shot estimated probability that a sample's class is within any of the exemplar classes. We test in data incremental, class incremental, and task incremental settings, as well as ability to perform flexible inference on varying subsets of zero-shot and learned categories. Our proposed method achieves a good balance of learning speed, target task effectiveness, and zero-shot effectiveness.
Consistent Multimodal Generation via A Unified GAN Framework
Jul 04, 2023We investigate how to generate multimodal image outputs, such as RGB, depth, and surface normals, with a single generative model. The challenge is to produce outputs that are realistic, and also consistent with each other. Our solution builds on the StyleGAN3 architecture, with a shared backbone and modality-specific branches in the last layers of the synthesis network, and we propose per-modality fidelity discriminators and a cross-modality consistency discriminator. In experiments on the Stanford2D3D dataset, we demonstrate realistic and consistent generation of RGB, depth, and normal images. We also show a training recipe to easily extend our pretrained model on a new domain, even with a few pairwise data. We further evaluate the use of synthetically generated RGB and depth pairs for training or fine-tuning depth estimators. Code will be available at https://github.com/jessemelpolio/MultimodalGAN.