 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReason3D: Searching and Reasoning 3D Segmentation via Large Language Model
May 27, 2024Recent advancements in multimodal large language models (LLMs) have shown their potential in various domains, especially concept reasoning. Despite these developments, applications in understanding 3D environments remain limited. This paper introduces Reason3D, a novel LLM designed for comprehensive 3D understanding. Reason3D takes point cloud data and text prompts as input to produce textual responses and segmentation masks, facilitating advanced tasks like 3D reasoning segmentation, hierarchical searching, express referring, and question answering with detailed mask outputs. Specifically, we propose a hierarchical mask decoder to locate small objects within expansive scenes. This decoder initially generates a coarse location estimate covering the object's general area. This foundational estimation facilitates a detailed, coarse-to-fine segmentation strategy that significantly enhances the precision of object identification and segmentation. Experiments validate that Reason3D achieves remarkable results on large-scale ScanNet and Matterport3D datasets for 3D express referring, 3D question answering, and 3D reasoning segmentation tasks. Code and models are available at: https://github.com/KuanchihHuang/Reason3D.
PTT: Point-Trajectory Transformer for Efficient Temporal 3D Object Detection
Dec 13, 2023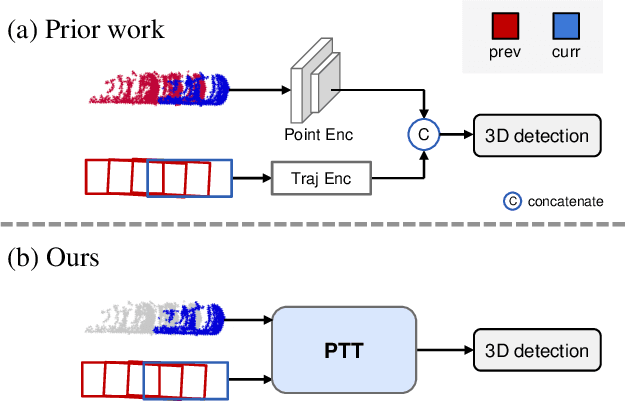
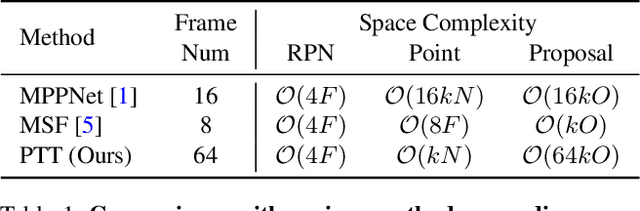
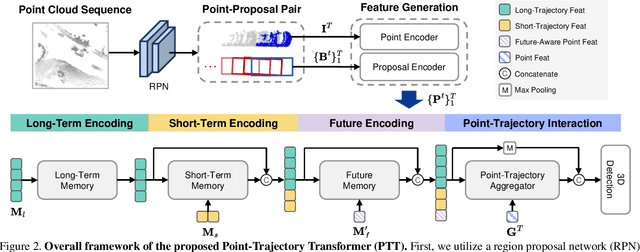
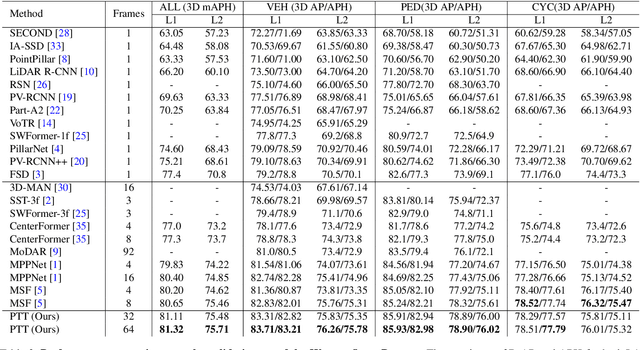
Recent temporal LiDAR-based 3D object detectors achieve promising performance based on the two-stage proposal-based approach. They generate 3D box candidates from the first-stage dense detector, followed by different temporal aggregation methods. However, these approaches require per-frame objects or whole point clouds, posing challenges related to memory bank utilization. Moreover, point clouds and trajectory features are combined solely based on concatenation, which may neglect effective interactions between them. In this paper, we propose a point-trajectory transformer with long short-term memory for efficient temporal 3D object detection. To this end, we only utilize point clouds of current-frame objects and their historical trajectories as input to minimize the memory bank storage requirement. Furthermore, we introduce modules to encode trajectory features, focusing on long short-term and future-aware perspectives, and then effectively aggregate them with point cloud features. We conduct extensive experiments on the large-scale Waymo dataset to demonstrate that our approach performs well against state-of-the-art methods. Code and models will be made publicly available at https://github.com/kuanchihhuang/PTT.
Weakly Supervised 3D Object Detection via Multi-Level Visual Guidance
Dec 12, 2023Weakly supervised 3D object detection aims to learn a 3D detector with lower annotation cost, e.g., 2D labels. Unlike prior work which still relies on few accurate 3D annotations, we propose a framework to study how to leverage constraints between 2D and 3D domains without requiring any 3D labels. Specifically, we employ visual data from three perspectives to establish connections between 2D and 3D domains. First, we design a feature-level constraint to align LiDAR and image features based on object-aware regions. Second, the output-level constraint is developed to enforce the overlap between 2D and projected 3D box estimations. Finally, the training-level constraint is utilized by producing accurate and consistent 3D pseudo-labels that align with the visual data. We conduct extensive experiments on the KITTI dataset to validate the effectiveness of the proposed three constraints. Without using any 3D labels, our method achieves favorable performance against state-of-the-art approaches and is competitive with the method that uses 500-frame 3D annotations. Code and models will be made publicly available at https://github.com/kuanchihhuang/VG-W3D.
Delving into Motion-Aware Matching for Monocular 3D Object Tracking
Aug 22, 2023Recent advances of monocular 3D object detection facilitate the 3D multi-object tracking task based on low-cost camera sensors. In this paper, we find that the motion cue of objects along different time frames is critical in 3D multi-object tracking, which is less explored in existing monocular-based approaches. In this paper, we propose a motion-aware framework for monocular 3D MOT. To this end, we propose MoMA-M3T, a framework that mainly consists of three motion-aware components. First, we represent the possible movement of an object related to all object tracklets in the feature space as its motion features. Then, we further model the historical object tracklet along the time frame in a spatial-temporal perspective via a motion transformer. Finally, we propose a motion-aware matching module to associate historical object tracklets and current observations as final tracking results. We conduct extensive experiments on the nuScenes and KITTI datasets to demonstrate that our MoMA-M3T achieves competitive performance against state-of-the-art methods. Moreover, the proposed tracker is flexible and can be easily plugged into existing image-based 3D object detectors without re-training. Code and models are available at https://github.com/kuanchihhuang/MoMA-M3T.
MonoDTR: Monocular 3D Object Detection with Depth-Aware Transformer
Mar 28, 2022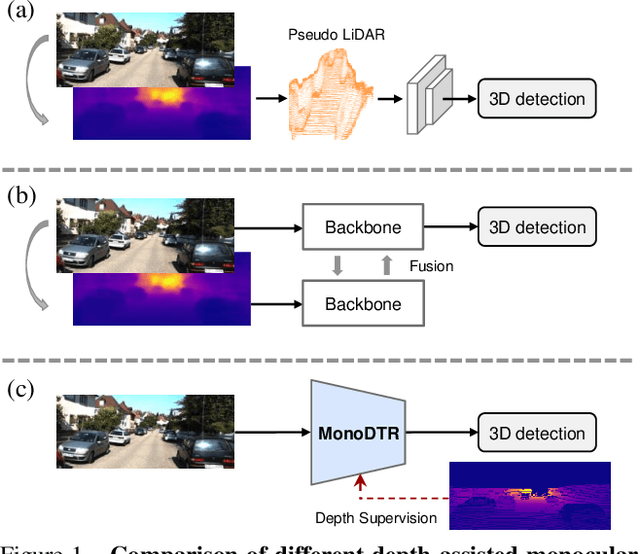
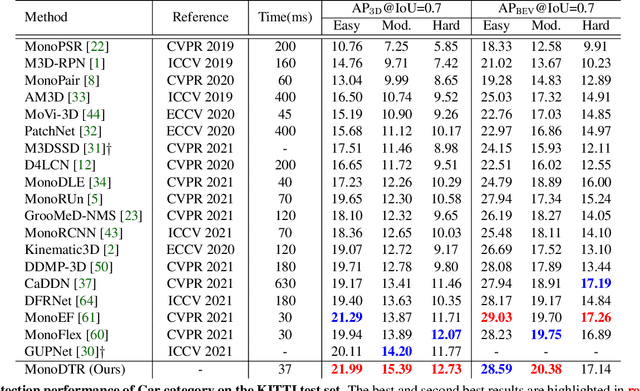
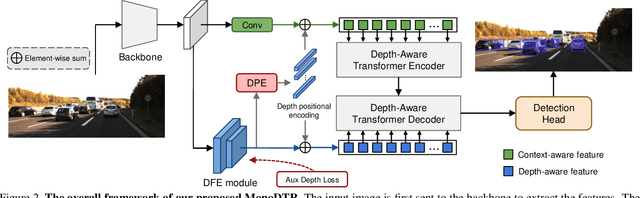
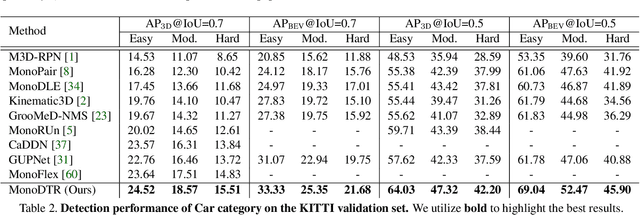
Monocular 3D object detection is an important yet challenging task in autonomous driving. Some existing methods leverage depth information from an off-the-shelf depth estimator to assist 3D detection, but suffer from the additional computational burden and achieve limited performance caused by inaccurate depth priors. To alleviate this, we propose MonoDTR, a novel end-to-end depth-aware transformer network for monocular 3D object detection. It mainly consists of two components: (1) the Depth-Aware Feature Enhancement (DFE) module that implicitly learns depth-aware features with auxiliary supervision without requiring extra computation, and (2) the Depth-Aware Transformer (DTR) module that globally integrates context- and depth-aware features. Moreover, different from conventional pixel-wise positional encodings, we introduce a novel depth positional encoding (DPE) to inject depth positional hints into transformers. Our proposed depth-aware modules can be easily plugged into existing image-only monocular 3D object detectors to improve the performance. Extensive experiments on the KITTI dataset demonstrate that our approach outperforms previous state-of-the-art monocular-based methods and achieves real-time detection. Code is available at https://github.com/kuanchihhuang/MonoDTR
3rd Place Solution for NeurIPS 2021 Shifts Challenge: Vehicle Motion Prediction
Dec 02, 2021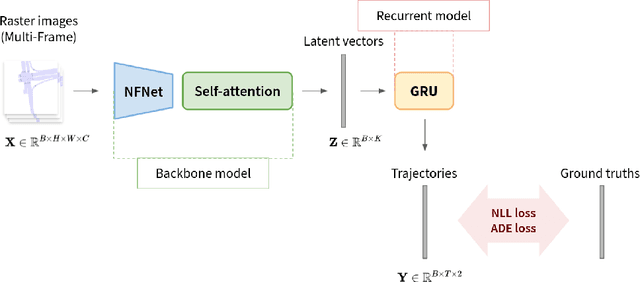
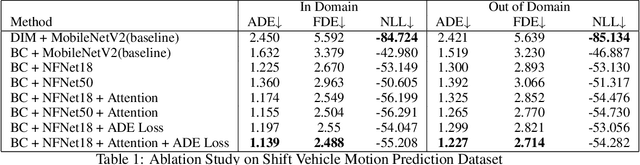
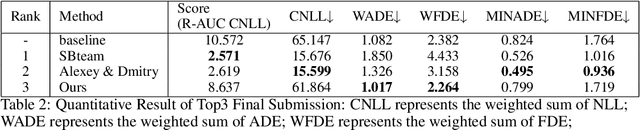
Shifts Challenge: Robustness and Uncertainty under Real-World Distributional Shift is a competition held by NeurIPS 2021. The objective of this competition is to search for methods to solve the motion prediction problem in cross-domain. In the real world dataset, It exists variance between input data distribution and ground-true data distribution, which is called the domain shift problem. In this report, we propose a new architecture inspired by state of the art papers. The main contribution is the backbone architecture with self-attention mechanism and predominant loss function. Subsequently, we won 3rd place as shown on the leaderboard.
Multi-Stream Attention Learning for Monocular Vehicle Velocity and Inter-Vehicle Distance Estimation
Oct 22, 2021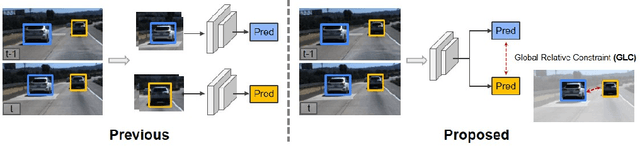
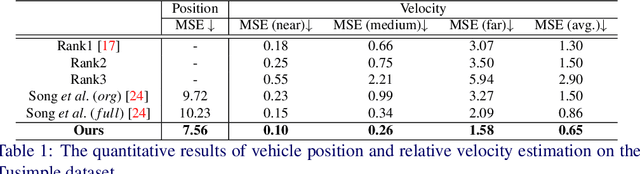
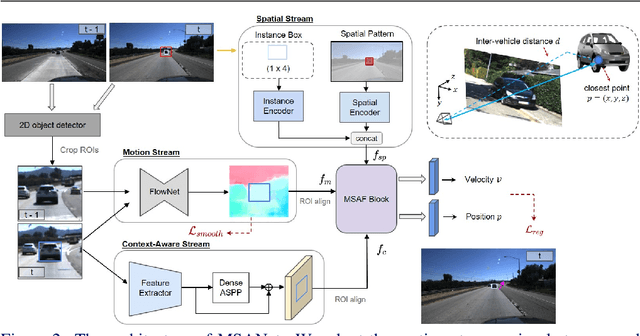

Vehicle velocity and inter-vehicle distance estimation are essential for ADAS (Advanced driver-assistance systems) and autonomous vehicles. To save the cost of expensive ranging sensors, recent studies focus on using a low-cost monocular camera to perceive the environment around the vehicle in a data-driven fashion. Existing approaches treat each vehicle independently for perception and cause inconsistent estimation. Furthermore, important information like context and spatial relation in 2D object detection is often neglected in the velocity estimation pipeline. In this paper, we explore the relationship between vehicles of the same frame with a global-relative-constraint (GLC) loss to encourage consistent estimation. A novel multi-stream attention network (MSANet) is proposed to extract different aspects of features, e.g., spatial and contextual features, for joint vehicle velocity and inter-vehicle distance estimation. Experiments show the effectiveness and robustness of our proposed approach. MSANet outperforms state-of-the-art algorithms on both the KITTI dataset and TuSimple velocity dataset.
LAFFNet: A Lightweight Adaptive Feature Fusion Network for Underwater Image Enhancement
May 05, 2021
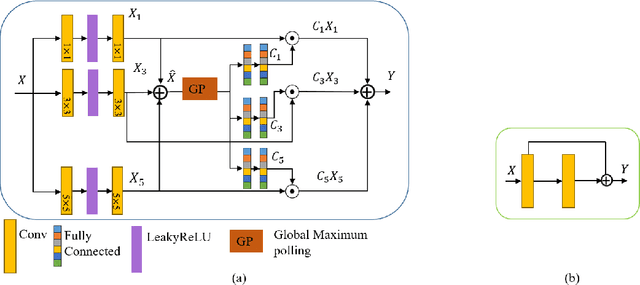
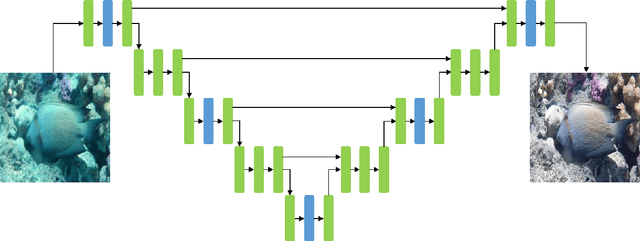

Underwater image enhancement is an important low-level computer vision task for autonomous underwater vehicles and remotely operated vehicles to explore and understand the underwater environments. Recently, deep convolutional neural networks (CNNs) have been successfully used in many computer vision problems, and so does underwater image enhancement. There are many deep-learning-based methods with impressive performance for underwater image enhancement, but their memory and model parameter costs are hindrances in practical application. To address this issue, we propose a lightweight adaptive feature fusion network (LAFFNet). The model is the encoder-decoder model with multiple adaptive feature fusion (AAF) modules. AAF subsumes multiple branches with different kernel sizes to generate multi-scale feature maps. Furthermore, channel attention is used to merge these feature maps adaptively. Our method reduces the number of parameters from 2.5M to 0.15M (around 94% reduction) but outperforms state-of-the-art algorithms by extensive experiments. Furthermore, we demonstrate our LAFFNet effectively improves high-level vision tasks like salience object detection and single image depth estimation.