 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Words: Multimodal LLM Knows When to Speak
May 20, 2025While large language model (LLM)-based chatbots have demonstrated strong capabilities in generating coherent and contextually relevant responses, they often struggle with understanding when to speak, particularly in delivering brief, timely reactions during ongoing conversations. This limitation arises largely from their reliance on text input, lacking the rich contextual cues in real-world human dialogue. In this work, we focus on real-time prediction of response types, with an emphasis on short, reactive utterances that depend on subtle, multimodal signals across vision, audio, and text. To support this, we introduce a new multimodal dataset constructed from real-world conversational videos, containing temporally aligned visual, auditory, and textual streams. This dataset enables fine-grained modeling of response timing in dyadic interactions. Building on this dataset, we propose MM-When2Speak, a multimodal LLM-based model that adaptively integrates visual, auditory, and textual context to predict when a response should occur, and what type of response is appropriate. Experiments show that MM-When2Speak significantly outperforms state-of-the-art unimodal and LLM-based baselines, achieving up to a 4x improvement in response timing accuracy over leading commercial LLMs. These results underscore the importance of multimodal inputs for producing timely, natural, and engaging conversational AI.
Toward Real-world BEV Perception: Depth Uncertainty Estimation via Gaussian Splatting
Apr 03, 2025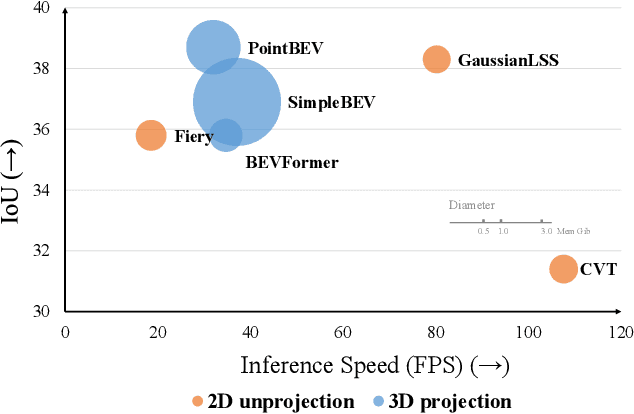



Bird's-eye view (BEV) perception has gained significant attention because it provides a unified representation to fuse multiple view images and enables a wide range of down-stream autonomous driving tasks, such as forecasting and planning. Recent state-of-the-art models utilize projection-based methods which formulate BEV perception as query learning to bypass explicit depth estimation. While we observe promising advancements in this paradigm, they still fall short of real-world applications because of the lack of uncertainty modeling and expensive computational requirement. In this work, we introduce GaussianLSS, a novel uncertainty-aware BEV perception framework that revisits unprojection-based methods, specifically the Lift-Splat-Shoot (LSS) paradigm, and enhances them with depth un-certainty modeling. GaussianLSS represents spatial dispersion by learning a soft depth mean and computing the variance of the depth distribution, which implicitly captures object extents. We then transform the depth distribution into 3D Gaussians and rasterize them to construct uncertainty-aware BEV features. We evaluate GaussianLSS on the nuScenes dataset, achieving state-of-the-art performance compared to unprojection-based methods. In particular, it provides significant advantages in speed, running 2.5x faster, and in memory efficiency, using 0.3x less memory compared to projection-based methods, while achieving competitive performance with only a 0.4% IoU difference.
uLayout: Unified Room Layout Estimation for Perspective and Panoramic Images
Mar 27, 2025We present uLayout, a unified model for estimating room layout geometries from both perspective and panoramic images, whereas traditional solutions require different model designs for each image type. The key idea of our solution is to unify both domains into the equirectangular projection, particularly, allocating perspective images into the most suitable latitude coordinate to effectively exploit both domains seamlessly. To address the Field-of-View (FoV) difference between the input domains, we design uLayout with a shared feature extractor with an extra 1D-Convolution layer to condition each domain input differently. This conditioning allows us to efficiently formulate a column-wise feature regression problem regardless of the FoV input. This simple yet effective approach achieves competitive performance with current state-of-the-art solutions and shows for the first time a single end-to-end model for both domains. Extensive experiments in the real-world datasets, LSUN, Matterport3D, PanoContext, and Stanford 2D-3D evidence the contribution of our approach. Code is available at https://github.com/JonathanLee112/uLayout.
What Changed and What Could Have Changed? State-Change Counterfactuals for Procedure-Aware Video Representation Learning
Mar 27, 2025



Understanding a procedural activity requires modeling both how action steps transform the scene, and how evolving scene transformations can influence the sequence of action steps, even those that are accidental or erroneous. Existing work has studied procedure-aware video representations by proposing novel approaches such as modeling the temporal order of actions and has not explicitly learned the state changes (scene transformations). In this work, we study procedure-aware video representation learning by incorporating state-change descriptions generated by Large Language Models (LLMs) as supervision signals for video encoders. Moreover, we generate state-change counterfactuals that simulate hypothesized failure outcomes, allowing models to learn by imagining the unseen ``What if'' scenarios. This counterfactual reasoning facilitates the model's ability to understand the cause and effect of each step in an activity. To verify the procedure awareness of our model, we conduct extensive experiments on procedure-aware tasks, including temporal action segmentation and error detection. Our results demonstrate the effectiveness of the proposed state-change descriptions and their counterfactuals and achieve significant improvements on multiple tasks. We will make our source code and data publicly available soon.
Exemplar Masking for Multimodal Incremental Learning
Dec 12, 2024Multimodal incremental learning needs to digest the information from multiple modalities while concurrently learning new knowledge without forgetting the previously learned information. There are numerous challenges for this task, mainly including the larger storage size of multimodal data in exemplar-based methods and the computational requirement of finetuning on huge multimodal models. In this paper, we leverage the parameter-efficient tuning scheme to reduce the burden of fine-tuning and propose the exemplar masking framework to efficiently replay old knowledge. Specifically, the non-important tokens are masked based on the attention weights and the correlation across different modalities, significantly reducing the storage size of an exemplar and consequently saving more exemplars under the same memory buffer. Moreover, we design a multimodal data augmentation technique to diversify exemplars for replaying prior knowledge. In experiments, we not only evaluate our method in existing multimodal datasets but also extend the ImageNet-R dataset to a multimodal dataset as a real-world application, where captions are generated by querying multimodal large language models (e.g., InstructBLIP). Extensive experiments show that our exemplar masking framework is more efficient and robust to catastrophic forgetting under the same limited memory buffer. Code is available at https://github.com/YiLunLee/Exemplar_Masking_MCIL.
Delve into Visual Contrastive Decoding for Hallucination Mitigation of Large Vision-Language Models
Dec 09, 2024While large vision-language models (LVLMs) have shown impressive capabilities in generating plausible responses correlated with input visual contents, they still suffer from hallucinations, where the generated text inaccurately reflects visual contents. To address this, recent approaches apply contrastive decoding to calibrate the model's response via contrasting output distributions with original and visually distorted samples, demonstrating promising hallucination mitigation in a training-free manner. However, the potential of changing information in visual inputs is not well-explored, so a deeper investigation into the behaviors of visual contrastive decoding is of great interest. In this paper, we first explore various methods for contrastive decoding to change visual contents, including image downsampling and editing. Downsampling images reduces the detailed textual information while editing yields new contents in images, providing new aspects as visual contrastive samples. To further study benefits by using different contrastive samples, we analyze probability-level metrics, including entropy and distribution distance. Interestingly, the effect of these samples in mitigating hallucinations varies a lot across LVLMs and benchmarks. Based on our analysis, we propose a simple yet effective method to combine contrastive samples, offering a practical solution for applying contrastive decoding across various scenarios. Extensive experiments are conducted to validate the proposed fusion method among different benchmarks.
Ranking-aware adapter for text-driven image ordering with CLIP
Dec 09, 2024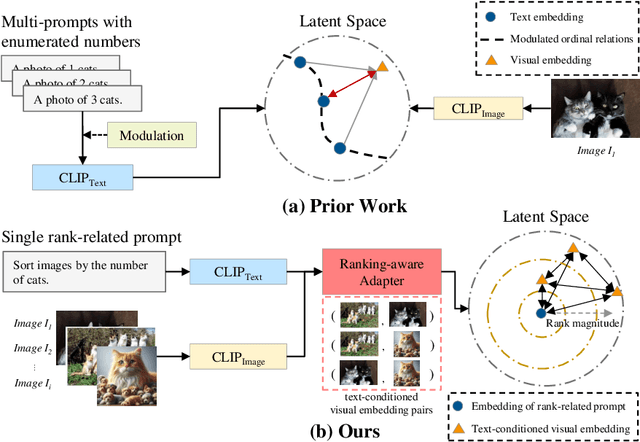
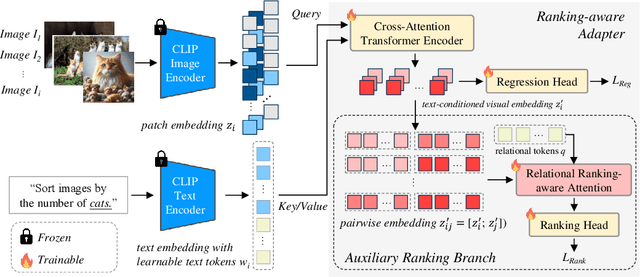
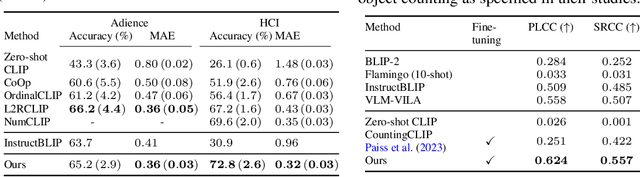
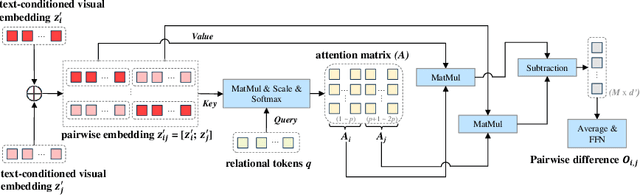
Recent advances in vision-language models (VLMs) have made significant progress in downstream tasks that require quantitative concepts such as facial age estimation and image quality assessment, enabling VLMs to explore applications like image ranking and retrieval. However, existing studies typically focus on the reasoning based on a single image and heavily depend on text prompting, limiting their ability to learn comprehensive understanding from multiple images. To address this, we propose an effective yet efficient approach that reframes the CLIP model into a learning-to-rank task and introduces a lightweight adapter to augment CLIP for text-guided image ranking. Specifically, our approach incorporates learnable prompts to adapt to new instructions for ranking purposes and an auxiliary branch with ranking-aware attention, leveraging text-conditioned visual differences for additional supervision in image ranking. Our ranking-aware adapter consistently outperforms fine-tuned CLIPs on various tasks and achieves competitive results compared to state-of-the-art models designed for specific tasks like facial age estimation and image quality assessment. Overall, our approach primarily focuses on ranking images with a single instruction, which provides a natural and generalized way of learning from visual differences across images, bypassing the need for extensive text prompts tailored to individual tasks. Code is available: https://github.com/uynaes/RankingAwareCLIP.
Learning Frame-Wise Emotion Intensity for Audio-Driven Talking-Head Generation
Sep 29, 2024



Human emotional expression is inherently dynamic, complex, and fluid, characterized by smooth transitions in intensity throughout verbal communication. However, the modeling of such intensity fluctuations has been largely overlooked by previous audio-driven talking-head generation methods, which often results in static emotional outputs. In this paper, we explore how emotion intensity fluctuates during speech, proposing a method for capturing and generating these subtle shifts for talking-head generation. Specifically, we develop a talking-head framework that is capable of generating a variety of emotions with precise control over intensity levels. This is achieved by learning a continuous emotion latent space, where emotion types are encoded within latent orientations and emotion intensity is reflected in latent norms. In addition, to capture the dynamic intensity fluctuations, we adopt an audio-to-intensity predictor by considering the speaking tone that reflects the intensity. The training signals for this predictor are obtained through our emotion-agnostic intensity pseudo-labeling method without the need of frame-wise intensity labeling. Extensive experiments and analyses validate the effectiveness of our proposed method in accurately capturing and reproducing emotion intensity fluctuations in talking-head generation, thereby significantly enhancing the expressiveness and realism of the generated outputs.
Self-training Room Layout Estimation via Geometry-aware Ray-casting
Jul 21, 2024



In this paper, we introduce a novel geometry-aware self-training framework for room layout estimation models on unseen scenes with unlabeled data. Our approach utilizes a ray-casting formulation to aggregate multiple estimates from different viewing positions, enabling the computation of reliable pseudo-labels for self-training. In particular, our ray-casting approach enforces multi-view consistency along all ray directions and prioritizes spatial proximity to the camera view for geometry reasoning. As a result, our geometry-aware pseudo-labels effectively handle complex room geometries and occluded walls without relying on assumptions such as Manhattan World or planar room walls. Evaluation on publicly available datasets, including synthetic and real-world scenarios, demonstrates significant improvements in current state-of-the-art layout models without using any human annotation.
Chat-Edit-3D: Interactive 3D Scene Editing via Text Prompts
Jul 10, 2024



Recent work on image content manipulation based on vision-language pre-training models has been effectively extended to text-driven 3D scene editing. However, existing schemes for 3D scene editing still exhibit certain shortcomings, hindering their further interactive design. Such schemes typically adhere to fixed input patterns, limiting users' flexibility in text input. Moreover, their editing capabilities are constrained by a single or a few 2D visual models and require intricate pipeline design to integrate these models into 3D reconstruction processes. To address the aforementioned issues, we propose a dialogue-based 3D scene editing approach, termed CE3D, which is centered around a large language model that allows for arbitrary textual input from users and interprets their intentions, subsequently facilitating the autonomous invocation of the corresponding visual expert models. Furthermore, we design a scheme utilizing Hash-Atlas to represent 3D scene views, which transfers the editing of 3D scenes onto 2D atlas images. This design achieves complete decoupling between the 2D editing and 3D reconstruction processes, enabling CE3D to flexibly integrate a wide range of existing 2D or 3D visual models without necessitating intricate fusion designs. Experimental results demonstrate that CE3D effectively integrates multiple visual models to achieve diverse editing visual effects, possessing strong scene comprehension and multi-round dialog capabilities. The code is available at https://sk-fun.fun/CE3D.