 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-optimality bounds for certainty equivalent policies in partially observed systems
Feb 02, 2026In this paper, we present a generalization of the certainty equivalence principle of stochastic control. One interpretation of the classical certainty equivalence principle for linear systems with output feedback and quadratic costs is as follows: the optimal action at each time is obtained by evaluating the optimal state-feedback policy of the stochastic linear system at the minimum mean square error (MMSE) estimate of the state. Motivated by this interpretation, we consider certainty equivalent policies for general (non-linear) partially observed stochastic systems that allow for any state estimate rather than restricting to MMSE estimates. In such settings, the certainty equivalent policy is not optimal. For models where the cost and the dynamics are smooth in an appropriate sense, we derive upper bounds on the sub-optimality of certainty equivalent policies. We present several examples to illustrate the results.
Divide, Weight, and Route: Difficulty-Aware Optimization with Dynamic Expert Fusion for Long-tailed Recognition
Aug 27, 2025



Long-tailed visual recognition is challenging not only due to class imbalance but also because of varying classification difficulty across categories. Simply reweighting classes by frequency often overlooks those that are intrinsically hard to learn. To address this, we propose \textbf{DQRoute}, a modular framework that combines difficulty-aware optimization with dynamic expert collaboration. DQRoute first estimates class-wise difficulty based on prediction uncertainty and historical performance, and uses this signal to guide training with adaptive loss weighting. On the architectural side, DQRoute employs a mixture-of-experts design, where each expert specializes in a different region of the class distribution. At inference time, expert predictions are weighted by confidence scores derived from expert-specific OOD detectors, enabling input-adaptive routing without the need for a centralized router. All components are trained jointly in an end-to-end manner. Experiments on standard long-tailed benchmarks demonstrate that DQRoute significantly improves performance, particularly on rare and difficult classes, highlighting the benefit of integrating difficulty modeling with decentralized expert routing.
Beyond Words: Multimodal LLM Knows When to Speak
May 20, 2025While large language model (LLM)-based chatbots have demonstrated strong capabilities in generating coherent and contextually relevant responses, they often struggle with understanding when to speak, particularly in delivering brief, timely reactions during ongoing conversations. This limitation arises largely from their reliance on text input, lacking the rich contextual cues in real-world human dialogue. In this work, we focus on real-time prediction of response types, with an emphasis on short, reactive utterances that depend on subtle, multimodal signals across vision, audio, and text. To support this, we introduce a new multimodal dataset constructed from real-world conversational videos, containing temporally aligned visual, auditory, and textual streams. This dataset enables fine-grained modeling of response timing in dyadic interactions. Building on this dataset, we propose MM-When2Speak, a multimodal LLM-based model that adaptively integrates visual, auditory, and textual context to predict when a response should occur, and what type of response is appropriate. Experiments show that MM-When2Speak significantly outperforms state-of-the-art unimodal and LLM-based baselines, achieving up to a 4x improvement in response timing accuracy over leading commercial LLMs. These results underscore the importance of multimodal inputs for producing timely, natural, and engaging conversational AI.
Semi-supervised Credit Card Fraud Detection via Attribute-Driven Graph Representation
Dec 24, 2024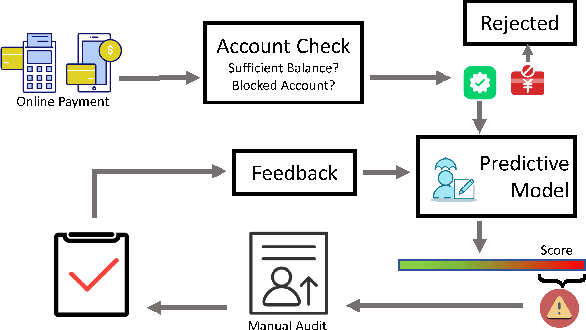
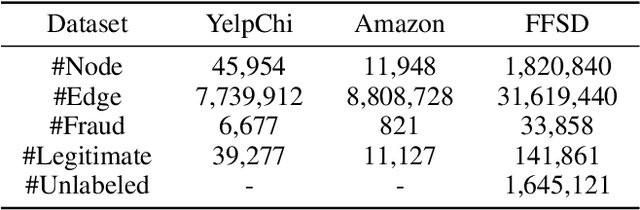
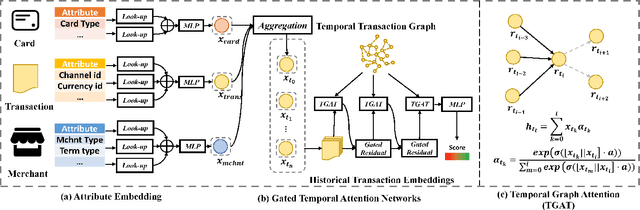
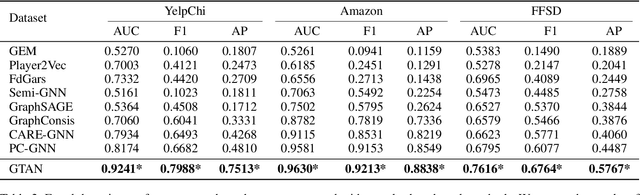
Credit card fraud incurs a considerable cost for both cardholders and issuing banks. Contemporary methods apply machine learning-based classifiers to detect fraudulent behavior from labeled transaction records. But labeled data are usually a small proportion of billions of real transactions due to expensive labeling costs, which implies that they do not well exploit many natural features from unlabeled data. Therefore, we propose a semi-supervised graph neural network for fraud detection. Specifically, we leverage transaction records to construct a temporal transaction graph, which is composed of temporal transactions (nodes) and interactions (edges) among them. Then we pass messages among the nodes through a Gated Temporal Attention Network (GTAN) to learn the transaction representation. We further model the fraud patterns through risk propagation among transactions. The extensive experiments are conducted on a real-world transaction dataset and two publicly available fraud detection datasets. The result shows that our proposed method, namely GTAN, outperforms other state-of-the-art baselines on three fraud detection datasets. Semi-supervised experiments demonstrate the excellent fraud detection performance of our model with only a tiny proportion of labeled data.
* 9 pages, 5 figures, AAAI 2023, code: https://github.com/AI4Risk/antifraud
Evolving to be Your Soulmate: Personalized Dialogue Agents with Dynamically Adapted Personas
Jun 20, 2024
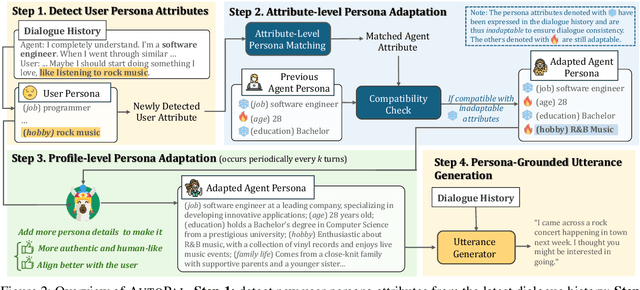
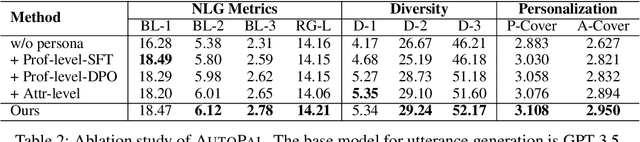
Previous research on persona-based dialogue agents typically preset the agent's persona before deployment, which remains static thereafter. In this paper, we take a step further and explore a new paradigm called Self-evolving Personalized Dialogue Agents (SPDA), where the agent continuously evolves during the conversation to better align with the user's anticipation by dynamically adapting its persona. This paradigm could enable better personalization for each user, but also introduce unique challenges, which mainly lie in the process of persona adaptation. Two key issues include how to achieve persona alignment with the user and how to ensure smooth transition in the adaptation process. To address them, we propose a novel framework that refines the persona at hierarchical levels to progressively align better with the user in a controllable way. Experiments show that integrating the personas adapted by our framework consistently enhances personalization and overall dialogue performance across various base systems.
COOL: Comprehensive Knowledge Enhanced Prompt Learning for Domain Adaptive Few-shot Fake News Detection
Jun 16, 2024Most Fake News Detection (FND) methods often struggle with data scarcity for emerging news domain. Recently, prompt learning based on Pre-trained Language Models (PLM) has emerged as a promising approach in domain adaptive few-shot learning, since it greatly reduces the need for labeled data by bridging the gap between pre-training and downstream task. Furthermore, external knowledge is also helpful in verifying emerging news, as emerging news often involves timely knowledge that may not be contained in the PLM's outdated prior knowledge. To this end, we propose COOL, a Comprehensive knOwledge enhanced prOmpt Learning method for domain adaptive few-shot FND. Specifically, we propose a comprehensive knowledge extraction module to extract both structured and unstructured knowledge that are positively or negatively correlated with news from external sources, and adopt an adversarial contrastive enhanced hybrid prompt learning strategy to model the domain-invariant news-knowledge interaction pattern for FND. Experimental results demonstrate the superiority of COOL over various state-of-the-arts.
Generation is better than Modification: Combating High Class Homophily Variance in Graph Anomaly Detection
Mar 15, 2024



Graph-based anomaly detection is currently an important research topic in the field of graph neural networks (GNNs). We find that in graph anomaly detection, the homophily distribution differences between different classes are significantly greater than those in homophilic and heterophilic graphs. For the first time, we introduce a new metric called Class Homophily Variance, which quantitatively describes this phenomenon. To mitigate its impact, we propose a novel GNN model named Homophily Edge Generation Graph Neural Network (HedGe). Previous works typically focused on pruning, selecting or connecting on original relationships, and we refer to these methods as modifications. Different from these works, our method emphasizes generating new relationships with low class homophily variance, using the original relationships as an auxiliary. HedGe samples homophily adjacency matrices from scratch using a self-attention mechanism, and leverages nodes that are relevant in the feature space but not directly connected in the original graph. Additionally, we modify the loss function to punish the generation of unnecessary heterophilic edges by the model. Extensive comparison experiments demonstrate that HedGe achieved the best performance across multiple benchmark datasets, including anomaly detection and edgeless node classification. The proposed model also improves the robustness under the novel Heterophily Attack with increased class homophily variance on other graph classification tasks.
Model approximation in MDPs with unbounded per-step cost
Feb 13, 2024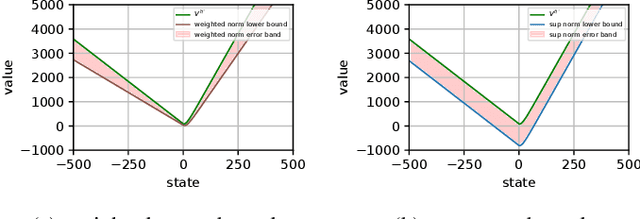
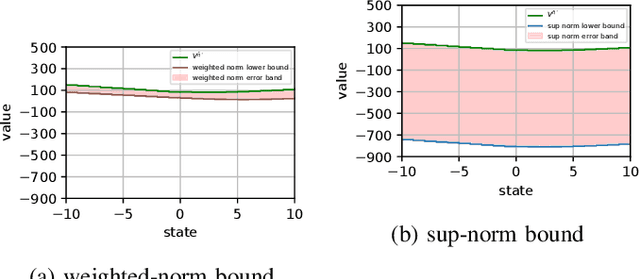

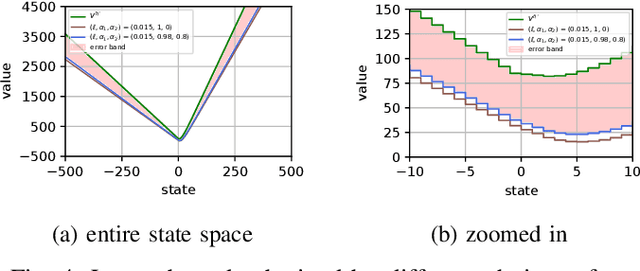
We consider the problem of designing a control policy for an infinite-horizon discounted cost Markov decision process $\mathcal{M}$ when we only have access to an approximate model $\hat{\mathcal{M}}$. How well does an optimal policy $\hat{\pi}^{\star}$ of the approximate model perform when used in the original model $\mathcal{M}$? We answer this question by bounding a weighted norm of the difference between the value function of $\hat{\pi}^\star $ when used in $\mathcal{M}$ and the optimal value function of $\mathcal{M}$. We then extend our results and obtain potentially tighter upper bounds by considering affine transformations of the per-step cost. We further provide upper bounds that explicitly depend on the weighted distance between cost functions and weighted distance between transition kernels of the original and approximate models. We present examples to illustrate our results.
COOPER: Coordinating Specialized Agents towards a Complex Dialogue Goal
Dec 19, 2023



In recent years, there has been a growing interest in exploring dialogues with more complex goals, such as negotiation, persuasion, and emotional support, which go beyond traditional service-focused dialogue systems. Apart from the requirement for much more sophisticated strategic reasoning and communication skills, a significant challenge of these tasks lies in the difficulty of objectively measuring the achievement of their goals in a quantifiable way, making it difficult for existing research to directly optimize the dialogue procedure towards them. In our work, we emphasize the multifaceted nature of complex dialogue goals and argue that it is more feasible to accomplish them by comprehensively considering and jointly promoting their different aspects. To this end, we propose a novel dialogue framework, Cooper, which coordinates multiple specialized agents, each dedicated to a specific dialogue goal aspect separately, to approach the complex objective. Through this divide-and-conquer manner, we make complex dialogue goals more approachable and elicit greater intelligence via the collaboration of individual agents. Experiments on persuasion and emotional support dialogues demonstrate the superiority of our method over a set of competitive baselines.
Grasping Core Rules of Time Series through Pure Models
Aug 15, 2022Time series underwent the transition from statistics to deep learning, as did many other machine learning fields. Although it appears that the accuracy has been increasing as the model is updated in a number of publicly available datasets, it typically only increases the scale by several times in exchange for a slight difference in accuracy. Through this experiment, we point out a different line of thinking, time series, especially long-term forecasting, may differ from other fields. It is not necessary to use extensive and complex models to grasp all aspects of time series, but to use pure models to grasp the core rules of time series changes. With this simple but effective idea, we created PureTS, a network with three pure linear layers that achieved state-of-the-art in 80% of the long sequence prediction tasks while being nearly the lightest model and having the fastest running speed. On this basis, we discuss the potential of pure linear layers in both phenomena and essence. The ability to understand the core law contributes to the high precision of long-distance prediction, and reasonable fluctuation prevents it from distorting the curve in multi-step prediction like mainstream deep learning models, which is summarized as a pure linear neural network that avoids over-fluctuating. Finally, we suggest the fundamental design standards for lightweight long-step time series tasks: input and output should try to have the same dimension, and the structure avoids fragmentation and complex operations.