 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Credit Card Fraud Detection via Attribute-Driven Graph Representation
Dec 24, 2024
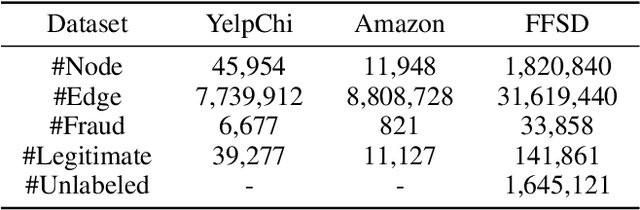
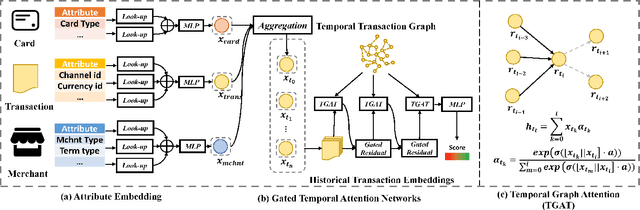
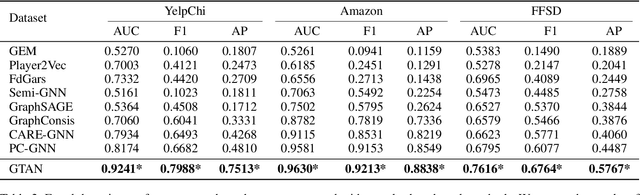
Credit card fraud incurs a considerable cost for both cardholders and issuing banks. Contemporary methods apply machine learning-based classifiers to detect fraudulent behavior from labeled transaction records. But labeled data are usually a small proportion of billions of real transactions due to expensive labeling costs, which implies that they do not well exploit many natural features from unlabeled data. Therefore, we propose a semi-supervised graph neural network for fraud detection. Specifically, we leverage transaction records to construct a temporal transaction graph, which is composed of temporal transactions (nodes) and interactions (edges) among them. Then we pass messages among the nodes through a Gated Temporal Attention Network (GTAN) to learn the transaction representation. We further model the fraud patterns through risk propagation among transactions. The extensive experiments are conducted on a real-world transaction dataset and two publicly available fraud detection datasets. The result shows that our proposed method, namely GTAN, outperforms other state-of-the-art baselines on three fraud detection datasets. Semi-supervised experiments demonstrate the excellent fraud detection performance of our model with only a tiny proportion of labeled data.
* 9 pages, 5 figures, AAAI 2023, code: https://github.com/AI4Risk/antifraud
LiDAttack: Robust Black-box Attack on LiDAR-based Object Detection
Nov 04, 2024Since DNN is vulnerable to carefully crafted adversarial examples, adversarial attack on LiDAR sensors have been extensively studied. We introduce a robust black-box attack dubbed LiDAttack. It utilizes a genetic algorithm with a simulated annealing strategy to strictly limit the location and number of perturbation points, achieving a stealthy and effective attack. And it simulates scanning deviations, allowing it to adapt to dynamic changes in real world scenario variations. Extensive experiments are conducted on 3 datasets (i.e., KITTI, nuScenes, and self-constructed data) with 3 dominant object detection models (i.e., PointRCNN, PointPillar, and PV-RCNN++). The results reveal the efficiency of the LiDAttack when targeting a wide range of object detection models, with an attack success rate (ASR) up to 90%.
Robust Knowledge Distillation Based on Feature Variance Against Backdoored Teacher Model
Jun 01, 2024



Benefiting from well-trained deep neural networks (DNNs), model compression have captured special attention for computing resource limited equipment, especially edge devices. Knowledge distillation (KD) is one of the widely used compression techniques for edge deployment, by obtaining a lightweight student model from a well-trained teacher model released on public platforms. However, it has been empirically noticed that the backdoor in the teacher model will be transferred to the student model during the process of KD. Although numerous KD methods have been proposed, most of them focus on the distillation of a high-performing student model without robustness consideration. Besides, some research adopts KD techniques as effective backdoor mitigation tools, but they fail to perform model compression at the same time. Consequently, it is still an open problem to well achieve two objectives of robust KD, i.e., student model's performance and backdoor mitigation. To address these issues, we propose RobustKD, a robust knowledge distillation that compresses the model while mitigating backdoor based on feature variance. Specifically, RobustKD distinguishes the previous works in three key aspects: (1) effectiveness: by distilling the feature map of the teacher model after detoxification, the main task performance of the student model is comparable to that of the teacher model; (2) robustness: by reducing the characteristic variance between the teacher model and the student model, it mitigates the backdoor of the student model under backdoored teacher model scenario; (3) generic: RobustKD still has good performance in the face of multiple data models (e.g., WRN 28-4, Pyramid-200) and diverse DNNs (e.g., ResNet50, MobileNet).
Temporal and Heterogeneous Graph Neural Network for Financial Time Series Prediction
May 09, 2023
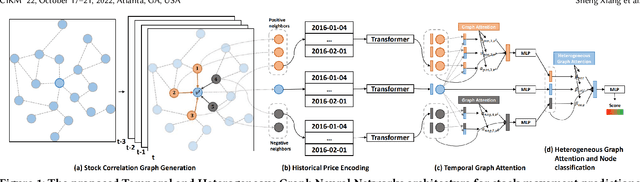


The price movement prediction of stock market has been a classical yet challenging problem, with the attention of both economists and computer scientists. In recent years, graph neural network has significantly improved the prediction performance by employing deep learning on company relations. However, existing relation graphs are usually constructed by handcraft human labeling or nature language processing, which are suffering from heavy resource requirement and low accuracy. Besides, they cannot effectively response to the dynamic changes in relation graphs. Therefore, in this paper, we propose a temporal and heterogeneous graph neural network-based (THGNN) approach to learn the dynamic relations among price movements in financial time series. In particular, we first generate the company relation graph for each trading day according to their historic price. Then we leverage a transformer encoder to encode the price movement information into temporal representations. Afterward, we propose a heterogeneous graph attention network to jointly optimize the embeddings of the financial time series data by transformer encoder and infer the probability of target movements. Finally, we conduct extensive experiments on the stock market in the United States and China. The results demonstrate the effectiveness and superior performance of our proposed methods compared with state-of-the-art baselines. Moreover, we also deploy the proposed THGNN in a real-world quantitative algorithm trading system, the accumulated portfolio return obtained by our method significantly outperforms other baselines.