 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRANE: Constrained Reasoning Injection for Code Agents via Nullspace Editing
May 13, 2026Code agents must both reason over long-horizon repository state and obey strict tool-use protocols. In paired Instruct/Thinking checkpoints, these capabilities are complementary but misaligned. The Instruct model is concise and tool-disciplined, whereas the Thinking model offers stronger planning and recovery behavior but often over-deliberates and degrades agent performance. We present CRANE (Constrained Reasoning Injection for Code Agents via Nullspace Editing), a training-free parameter-editing method that treats the Thinking-Instruct delta as a directional pool of candidate reasoning edits for the Instruct backbone. CRANE combines magnitude thresholding to denoise the delta, a Conservative Taylor Gate to retain edits that are jointly beneficial for reasoning transfer and tool-use preservation, and Graduated Sigmoidal Projection to suppress format-critical update directions. By merging paired Instruct and Thinking checkpoints, CRANE delivers strong gains over either individual model while preserving Instruct-level efficiency: on Roo-Eval it achieves pass1 of 66.2% (+19.5%) for Qwen3-30B-A3B and 81.5% (+8.7%) for Qwen3-Next-80B-A3B; on SWE-bench-Verified it resolves up to 14 additional instances at both scales (122/500 and 180/500); and on Terminal-Bench v2 it improves pass1/pass5 by up to 2.3%/7.8%, reaching 7.6%/17.9% and 14.8%/30.3%, respectively, consistently outperforming alternative merging strategies across all three benchmarks.
Multi-task Code LLMs: Data Mix or Model Merge?
Jan 28, 2026Recent research advocates deploying smaller, specialized code LLMs in agentic frameworks alongside frontier models, sparking interest in efficient strategies for multi-task learning that balance performance, constraints, and costs. We compare two approaches for creating small, multi-task code LLMs: data mixing versus model merging. We conduct extensive experiments across two model families (Qwen Coder and DeepSeek Coder) at two scales (2B and 7B parameters), fine-tuning them for code generation and code summarization tasks. Our evaluation on HumanEval, MBPP, and CodeXGlue benchmarks reveals that model merging achieves the best overall performance at larger scale across model families, retaining 96% of specialized model performance on code generation tasks while maintaining summarization capabilities. Notably, merged models can even surpass individually fine-tuned models, with our best configuration of Qwen Coder 2.5 7B model achieving 92.7% Pass@1 on HumanEval compared to 90.9% for its task-specific fine-tuned equivalent. At a smaller scale we find instead data mixing to be a preferred strategy. We further introduce a weight analysis technique to understand how different tasks affect model parameters and their implications for merging strategies. The results suggest that careful merging and mixing strategies can effectively combine task-specific capabilities without significant performance degradation, making them ideal for resource-constrained deployment scenarios.
Semi-supervised Credit Card Fraud Detection via Attribute-Driven Graph Representation
Dec 24, 2024
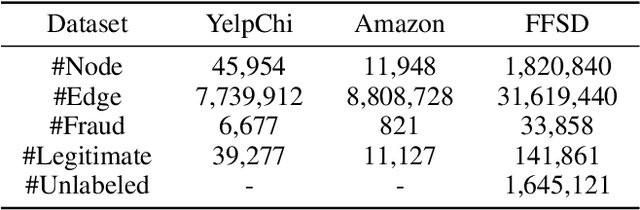
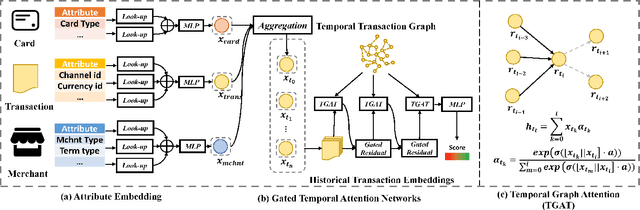
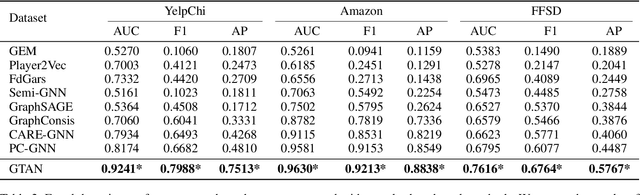
Credit card fraud incurs a considerable cost for both cardholders and issuing banks. Contemporary methods apply machine learning-based classifiers to detect fraudulent behavior from labeled transaction records. But labeled data are usually a small proportion of billions of real transactions due to expensive labeling costs, which implies that they do not well exploit many natural features from unlabeled data. Therefore, we propose a semi-supervised graph neural network for fraud detection. Specifically, we leverage transaction records to construct a temporal transaction graph, which is composed of temporal transactions (nodes) and interactions (edges) among them. Then we pass messages among the nodes through a Gated Temporal Attention Network (GTAN) to learn the transaction representation. We further model the fraud patterns through risk propagation among transactions. The extensive experiments are conducted on a real-world transaction dataset and two publicly available fraud detection datasets. The result shows that our proposed method, namely GTAN, outperforms other state-of-the-art baselines on three fraud detection datasets. Semi-supervised experiments demonstrate the excellent fraud detection performance of our model with only a tiny proportion of labeled data.
* 9 pages, 5 figures, AAAI 2023, code: https://github.com/AI4Risk/antifraud
Model Cascading for Code: Reducing Inference Costs with Model Cascading for LLM Based Code Generation
May 24, 2024The rapid development of large language models (LLMs) has led to significant advancements in code completion tasks. While larger models have higher accuracy, they also cost much more to run. Meanwhile, model cascading has been proven effective to conserve computational resources while enhancing accuracy in LLMs on natural language generation tasks. It generates output with the smallest model in a set, and only queries the larger models when it fails to meet predefined quality criteria. However, this strategy has not been used in code completion tasks, primarily because assessing the quality of code completions differs substantially from assessing natural language, where the former relies heavily on the functional correctness. To address this, we propose letting each model generate and execute a set of test cases for their solutions, and use the test results as the cascading threshold. We show that our model cascading strategy reduces computational costs while increases accuracy compared to generating the output with a single model. We also introduce a heuristics to determine the optimal combination of the number of solutions, test cases, and test lines each model should generate, based on the budget. Compared to speculative decoding, our method works on black-box models, having the same level of cost-accuracy trade-off, yet providing much more choices based on the server's budget. Ours is the first work to optimize cost-accuracy trade-off for LLM code generation with model cascading.
Scene Summarization: Clustering Scene Videos into Spatially Diverse Frames
Nov 28, 2023We propose scene summarization as a new video-based scene understanding task. It aims to summarize a long video walkthrough of a scene into a small set of frames that are spatially diverse in the scene, which has many impotant applications, such as in surveillance, real estate, and robotics. It stems from video summarization but focuses on long and continuous videos from moving cameras, instead of user-edited fragmented video clips that are more commonly studied in existing video summarization works. Our solution to this task is a two-stage self-supervised pipeline named SceneSum. Its first stage uses clustering to segment the video sequence. Our key idea is to combine visual place recognition (VPR) into this clustering process to promote spatial diversity. Its second stage needs to select a representative keyframe from each cluster as the summary while respecting resource constraints such as memory and disk space limits. Additionally, if the ground truth image trajectory is available, our method can be easily augmented with a supervised loss to enhance the clustering and keyframe selection. Extensive experiments on both real-world and simulated datasets show our method outperforms common video summarization baselines by 50%
Real-Time Text Detection and Recognition
Oct 31, 2020Inrecentyears,ConvolutionalNeuralNet-work(CNN) is quite a popular topic, as it is a powerful andintelligent technique that can be applied in various fields.The YOLO is a technique that uses the algorithms for real-time text detection tasks. However, issues like, photometricdistortion and geometric distortion, could affect the systemYOLO accuracy and cause system failure. Therefore, thereare improvements that can make the system work better. Inthis paper, we are going to present our solution - a potentialsolution of a fast and accurate real-time text direction andrecognition system. The paper covers the topic of Real-TimeText detection and recognition in three major areas: 1. videoand image preprocess, 2. Text detection, 3. Text recognition. Asa mature technique, there are many existing methods that canpotentially improve the solution. We will go through some ofthose existing methods in the literature review session. In thisway, we are presenting an industrial strength, high-accuracy,Real-Time Text Detection and recognition tool.