 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Emergent Extreme Events in Multi-Agent Systems
Jan 28, 2026Large language model-powered multi-agent systems have emerged as powerful tools for simulating complex human-like systems. The interactions within these systems often lead to extreme events whose origins remain obscured by the black box of emergence. Interpreting these events is critical for system safety. This paper proposes the first framework for explaining emergent extreme events in multi-agent systems, aiming to answer three fundamental questions: When does the event originate? Who drives it? And what behaviors contribute to it? Specifically, we adapt the Shapley value to faithfully attribute the occurrence of extreme events to each action taken by agents at different time steps, i.e., assigning an attribution score to the action to measure its influence on the event. We then aggregate the attribution scores along the dimensions of time, agent, and behavior to quantify the risk contribution of each dimension. Finally, we design a set of metrics based on these contribution scores to characterize the features of extreme events. Experiments across diverse multi-agent system scenarios (economic, financial, and social) demonstrate the effectiveness of our framework and provide general insights into the emergence of extreme phenomena.
Grad: Guided Relation Diffusion Generation for Graph Augmentation in Graph Fraud Detection
Dec 19, 2025



Nowadays, Graph Fraud Detection (GFD) in financial scenarios has become an urgent research topic to protect online payment security. However, as organized crime groups are becoming more professional in real-world scenarios, fraudsters are employing more sophisticated camouflage strategies. Specifically, fraudsters disguise themselves by mimicking the behavioral data collected by platforms, ensuring that their key characteristics are consistent with those of benign users to a high degree, which we call Adaptive Camouflage. Consequently, this narrows the differences in behavioral traits between them and benign users within the platform's database, thereby making current GFD models lose efficiency. To address this problem, we propose a relation diffusion-based graph augmentation model Grad. In detail, Grad leverages a supervised graph contrastive learning module to enhance the fraud-benign difference and employs a guided relation diffusion generator to generate auxiliary homophilic relations from scratch. Based on these, weak fraudulent signals would be enhanced during the aggregation process, thus being obvious enough to be captured. Extensive experiments have been conducted on two real-world datasets provided by WeChat Pay, one of the largest online payment platforms with billions of users, and three public datasets. The results show that our proposed model Grad outperforms SOTA methods in both various scenarios, achieving at most 11.10% and 43.95% increases in AUC and AP, respectively. Our code is released at https://github.com/AI4Risk/antifraud and https://github.com/Muyiiiii/WWW25-Grad.
* Accepted by The Web Conference 2025 (WWW'25). 12 pages, includes implementation details. Code: https://github.com/AI4Risk/antifraud and https://github.com/Muyiiiiii/WWW25-Grad
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
Cross-Paradigm Graph Backdoor Attacks with Promptable Subgraph Triggers
Oct 26, 2025Graph Neural Networks(GNNs) are vulnerable to backdoor attacks, where adversaries implant malicious triggers to manipulate model predictions. Existing trigger generators are often simplistic in structure and overly reliant on specific features, confining them to a single graph learning paradigm, such as graph supervised learning, graph contrastive learning, or graph prompt learning. This specialized design, which aligns the trigger with one learning objective, results in poor transferability when applied to other learning paradigms. For instance, triggers generated for the graph supervised learning paradigm perform poorly when tested within graph contrastive learning or graph prompt learning environments. Furthermore, these simple generators often fail to utilize complex structural information or node diversity within the graph data. These constraints limit the attack success rates of such methods in general testing scenarios. Therefore, to address these limitations, we propose Cross-Paradigm Graph Backdoor Attacks with Promptable Subgraph Triggers(CP-GBA), a new transferable graph backdoor attack that employs graph prompt learning(GPL) to train a set of universal subgraph triggers. First, we distill a compact yet expressive trigger set from target graphs, which is structured as a queryable repository, by jointly enforcing class-awareness, feature richness, and structural fidelity. Second, we conduct the first exploration of the theoretical transferability of GPL to train these triggers under prompt-based objectives, enabling effective generalization to diverse and unseen test-time paradigms. Extensive experiments across multiple real-world datasets and defense scenarios show that CP-GBA achieves state-of-the-art attack success rates.
CFBenchmark-MM: Chinese Financial Assistant Benchmark for Multimodal Large Language Model
Jun 16, 2025Multimodal Large Language Models (MLLMs) have rapidly evolved with the growth of Large Language Models (LLMs) and are now applied in various fields. In finance, the integration of diverse modalities such as text, charts, and tables is crucial for accurate and efficient decision-making. Therefore, an effective evaluation system that incorporates these data types is essential for advancing financial application. In this paper, we introduce CFBenchmark-MM, a Chinese multimodal financial benchmark with over 9,000 image-question pairs featuring tables, histogram charts, line charts, pie charts, and structural diagrams. Additionally, we develop a staged evaluation system to assess MLLMs in handling multimodal information by providing different visual content step by step. Despite MLLMs having inherent financial knowledge, experimental results still show limited efficiency and robustness in handling multimodal financial context. Further analysis on incorrect responses reveals the misinterpretation of visual content and the misunderstanding of financial concepts are the primary issues. Our research validates the significant, yet underexploited, potential of MLLMs in financial analysis, highlighting the need for further development and domain-specific optimization to encourage the enhanced use in financial domain.
FinLMM-R1: Enhancing Financial Reasoning in LMM through Scalable Data and Reward Design
Jun 16, 2025Large Multimodal Models (LMMs) demonstrate significant cross-modal reasoning capabilities. However, financial applications face challenges due to the lack of high-quality multimodal reasoning datasets and the inefficiency of existing training paradigms for reasoning enhancement. To address these issues, we propose an integrated framework, FinLMM-R1, combining an automated and scalable pipeline for data construction with enhanced training strategies to improve the multimodal reasoning of LMM. The Automated and Scalable Pipeline (ASP) resolves textual-visual misalignment in financial reports through a separate paradigm of question-answer generation and image-question alignment, ensuring data integrity and extraction efficiency. Through ASP, we collect 89,378 aligned image-question pairs from 23,397 financial reports, covering tasks such as arithmetic reasoning, statistics reasoning, financial explanation, and financial knowledge. Moreover, we introduce the Thinking with Adversarial Reward in LMM (TAR-LMM), extending the prior two-stage training framework [1] with additional reward mechanisms. In the first stage, we focus on text-only tasks with format and accuracy rewards to guide the model in generating well-structured thinking contents. In the second stage, we construct multi-image contrastive samples with additional reward components including image selection, thinking content length, and adversarial reward to jointly optimize the LMM across visual perception, reasoning efficiency, and logical coherence. Extensive experiments on 7 benchmarks show ASP-derived dataset and training framework significantly improve answer accuracy and reasoning depth over existing reasoning LMMs in both general and financial multimodal contexts.
Language Model-Enhanced Message Passing for Heterophilic Graph Learning
May 26, 2025
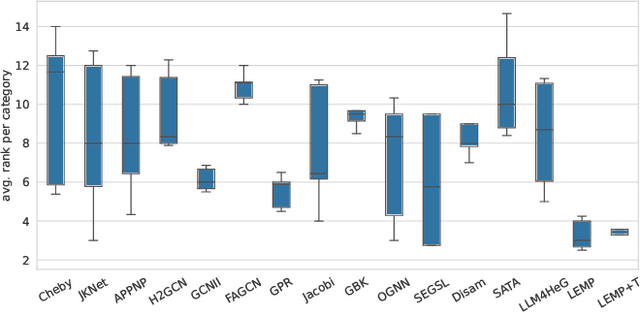


Traditional graph neural networks (GNNs), which rely on homophily-driven message passing, struggle with heterophilic graphs where connected nodes exhibit dissimilar features and different labels. While existing methods address heterophily through graph structure refinement or adaptation of neighbor aggregation functions, they often overlook the semantic potential of node text, rely on suboptimal message representation for propagation and compromise performance on homophilic graphs. To address these limitations, we propose a novel language model (LM)-enhanced message passing approach for heterophilic graph leaning (LEMP4HG). Specifically, in the context of text-attributed graph, we provide paired node texts for LM to generate their connection analysis, which are encoded and then fused with paired node textual embeddings through a gating mechanism. The synthesized messages are semantically enriched and adaptively balanced with both nodes' information, which mitigates contradictory signals when neighbor aggregation in heterophilic regions. Furthermore, we introduce an active learning strategy guided by our heuristic MVRD (Modulated Variation of Reliable Distance), selectively enhancing node pairs suffer most from message passing, reducing the cost of analysis generation and side effects on homophilic regions. Extensive experiments validate that our approach excels on heterophilic graphs and performs robustly on homophilic ones, with a graph convolutional network (GCN) backbone and a practical budget.
Can LLMs Alleviate Catastrophic Forgetting in Graph Continual Learning? A Systematic Study
May 24, 2025Nowadays, real-world data, including graph-structure data, often arrives in a streaming manner, which means that learning systems need to continuously acquire new knowledge without forgetting previously learned information. Although substantial existing works attempt to address catastrophic forgetting in graph machine learning, they are all based on training from scratch with streaming data. With the rise of pretrained models, an increasing number of studies have leveraged their strong generalization ability for continual learning. Therefore, in this work, we attempt to answer whether large language models (LLMs) can mitigate catastrophic forgetting in Graph Continual Learning (GCL). We first point out that current experimental setups for GCL have significant flaws, as the evaluation stage may lead to task ID leakage. Then, we evaluate the performance of LLMs in more realistic scenarios and find that even minor modifications can lead to outstanding results. Finally, based on extensive experiments, we propose a simple-yet-effective method, Simple Graph Continual Learning (SimGCL), that surpasses the previous state-of-the-art GNN-based baseline by around 20% under the rehearsal-free constraint. To facilitate reproducibility, we have developed an easy-to-use benchmark LLM4GCL for training and evaluating existing GCL methods. The code is available at: https://github.com/ZhixunLEE/LLM4GCL.
Effective High-order Graph Representation Learning for Credit Card Fraud Detection
Mar 03, 2025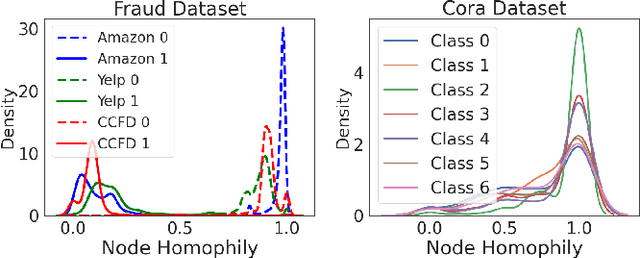
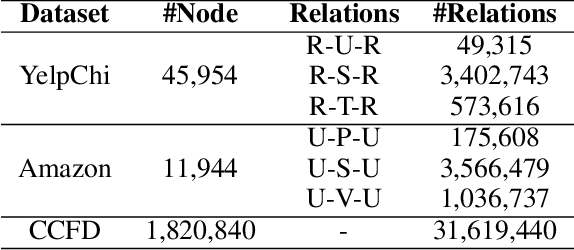
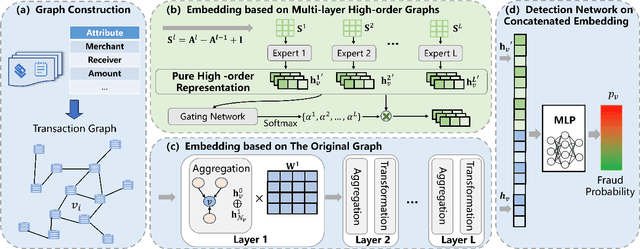
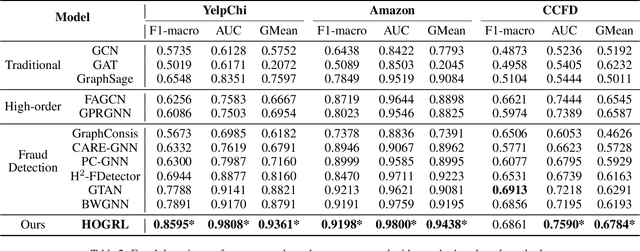
Credit card fraud imposes significant costs on both cardholders and issuing banks. Fraudsters often disguise their crimes, such as using legitimate transactions through several benign users to bypass anti-fraud detection. Existing graph neural network (GNN) models struggle with learning features of camouflaged, indirect multi-hop transactions due to their inherent over-smoothing issues in deep multi-layer aggregation, presenting a major challenge in detecting disguised relationships. Therefore, in this paper, we propose a novel High-order Graph Representation Learning model (HOGRL) to avoid incorporating excessive noise during the multi-layer aggregation process. In particular, HOGRL learns different orders of \emph{pure} representations directly from high-order transaction graphs. We realize this goal by effectively constructing high-order transaction graphs first and then learning the \emph{pure} representations of each order so that the model could identify fraudsters' multi-hop indirect transactions via multi-layer \emph{pure} feature learning. In addition, we introduce a mixture-of-expert attention mechanism to automatically determine the importance of different orders for jointly optimizing fraud detection performance. We conduct extensive experiments in both the open source and real-world datasets, the result demonstrates the significant improvements of our proposed HOGRL compared with state-of-the-art fraud detection baselines. HOGRL's superior performance also proves its effectiveness in addressing high-order fraud camouflage criminals.
* 9 pages, 5 figures, accepted at IJCAI 2024
FinTSB: A Comprehensive and Practical Benchmark for Financial Time Series Forecasting
Feb 26, 2025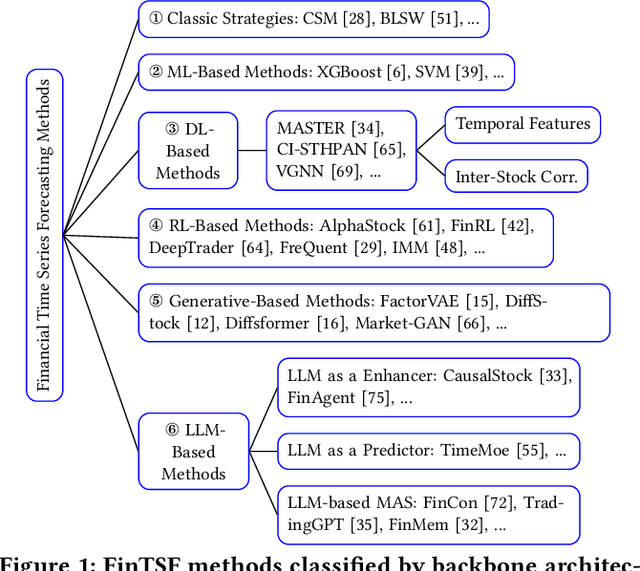



Financial time series (FinTS) record the behavior of human-brain-augmented decision-making, capturing valuable historical information that can be leveraged for profitable investment strategies. Not surprisingly, this area has attracted considerable attention from researchers, who have proposed a wide range of methods based on various backbones. However, the evaluation of the area often exhibits three systemic limitations: 1. Failure to account for the full spectrum of stock movement patterns observed in dynamic financial markets. (Diversity Gap), 2. The absence of unified assessment protocols undermines the validity of cross-study performance comparisons. (Standardization Deficit), and 3. Neglect of critical market structure factors, resulting in inflated performance metrics that lack practical applicability. (Real-World Mismatch). Addressing these limitations, we propose FinTSB, a comprehensive and practical benchmark for financial time series forecasting (FinTSF). To increase the variety, we categorize movement patterns into four specific parts, tokenize and pre-process the data, and assess the data quality based on some sequence characteristics. To eliminate biases due to different evaluation settings, we standardize the metrics across three dimensions and build a user-friendly, lightweight pipeline incorporating methods from various backbones. To accurately simulate real-world trading scenarios and facilitate practical implementation, we extensively model various regulatory constraints, including transaction fees, among others. Finally, we conduct extensive experiments on FinTSB, highlighting key insights to guide model selection under varying market conditions. Overall, FinTSB provides researchers with a novel and comprehensive platform for improving and evaluating FinTSF methods. The code is available at https://github.com/TongjiFinLab/FinTSBenchmark.