 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Range Filtering Approximate Nearest Neighbor Search: Containment and Overlap [Technical Report]
May 26, 2026Approximate nearest neighbor (ANN) search with range filters has recently garnered significant attention. This paper delves into a generalized form of this problem, i.e., ANN search with exact range-range (RR) predicates on a range-valued attribute, named RR filtering ANN (RRANN). Specifically, given $n$ vectors in $\mathbb{R}^d$, each vector $v_i$ is associated with a numeric range $[l_i, r_i]$, symbolizing aspects like a price range or time interval. An RRANN query $(v_q, l_q, r_q)$ aims at finding $k$ vectors closest to $v_q$ within the vectors satisfying an arbitrary RR predicate defined between the query range $[l_q, r_q]$ and the object range $[l_i, r_i]$. The RR predicate remains unspecified, enabling user-defined conditions. It may encompass containment ($[l_i, r_i] \subseteq [l_q, r_q]$ or $[l_q, r_q] \subseteq [l_i, r_i]$), overlap ($l_i \le l_q \le r_i \le r_q$ or $l_q \le l_i \le r_q \le r_i$), or a disjunction of them. RRANN has broad applications in queries related to price ranges or time intervals, and it generalizes existing variants of ANN search with range filters. However, existing dedicated approaches for these problems lack the capacity to support queries with arbitrary RR predicates. Hence, we introduce a new approach, labeled multi-segment tree graph. It efficiently handles arbitrary RR predicates by avoiding traversal through non-predicate-satisfied nodes, and keeps equivalent index size and construction time to state-of-the-art methods for RFANN. Extensive experiments on real-world data demonstrate the efficacy of our approach in RRANN queries, achieving up to 12.5x speedups with the same accuracy as the baselines. Moreover, our approach attains comparable RFANN search performance and notably superior IFANN and TSANN search performance compared to the respective state-of-the-art approaches. Our code is available at https://github.com/FanEDG/MSTG.
Beyond Linear LLM Invocation: An Efficient and Effective Semantic Filter Paradigm
Mar 05, 2026Large language models (LLMs) are increasingly used for semantic query processing over large corpora. A set of semantic operators derived from relational algebra has been proposed to provide a unified interface for expressing such queries, among which the semantic filter operator serves as a cornerstone. Given a table T with a natural language predicate e, for each tuple in the relation, the execution of a semantic filter proceeds by constructing an input prompt that combines the predicate e with its content, querying the LLM, and obtaining the binary decision. However, this tuple-by-tuple evaluation necessitates a complete linear scan of the table, incurring prohibitive latency and token costs. Although recent work has attempted to optimize semantic filtering, it still does not break the linear LLM invocation barriers. To address this, we propose Clustering-Sampling-Voting (CSV), a new framework that reduces LLM invocations to sublinear complexity while providing error guarantees. CSV embeds tuples into semantic clusters, samples a small subset for LLM evaluation, and infers cluster-level labels via two proposed voting strategies: UniVote, which aggregates labels uniformly, and SimVote, which weights votes by semantic similarity. Moreover, CSV triggers re-clustering on ambiguous clusters to ensure robustness across diverse datasets. The results conducted on real-world datasets demonstrate that CSV reduces the number of LLM calls by 1.28-355x compared to the state-of-the-art approaches, while maintaining comparable effectiveness in terms of Accuracy and F1 score.
Can LLMs Alleviate Catastrophic Forgetting in Graph Continual Learning? A Systematic Study
May 24, 2025Nowadays, real-world data, including graph-structure data, often arrives in a streaming manner, which means that learning systems need to continuously acquire new knowledge without forgetting previously learned information. Although substantial existing works attempt to address catastrophic forgetting in graph machine learning, they are all based on training from scratch with streaming data. With the rise of pretrained models, an increasing number of studies have leveraged their strong generalization ability for continual learning. Therefore, in this work, we attempt to answer whether large language models (LLMs) can mitigate catastrophic forgetting in Graph Continual Learning (GCL). We first point out that current experimental setups for GCL have significant flaws, as the evaluation stage may lead to task ID leakage. Then, we evaluate the performance of LLMs in more realistic scenarios and find that even minor modifications can lead to outstanding results. Finally, based on extensive experiments, we propose a simple-yet-effective method, Simple Graph Continual Learning (SimGCL), that surpasses the previous state-of-the-art GNN-based baseline by around 20% under the rehearsal-free constraint. To facilitate reproducibility, we have developed an easy-to-use benchmark LLM4GCL for training and evaluating existing GCL methods. The code is available at: https://github.com/ZhixunLEE/LLM4GCL.
Materials Generation in the Era of Artificial Intelligence: A Comprehensive Survey
May 22, 2025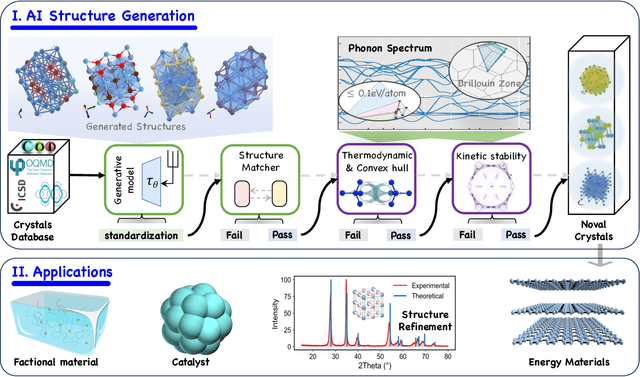

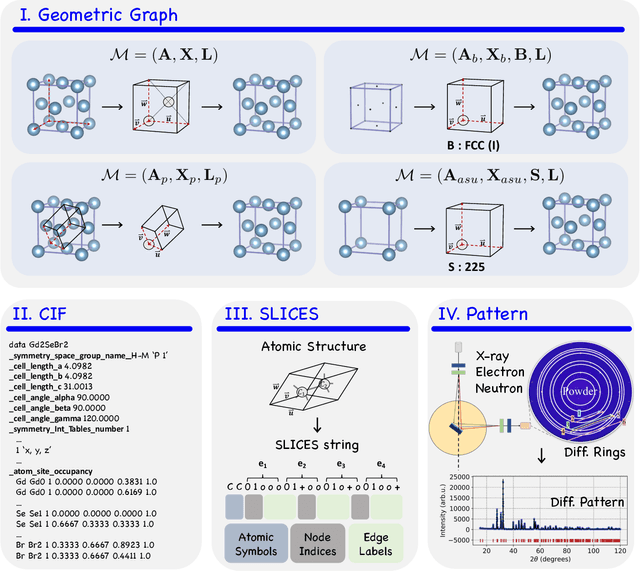
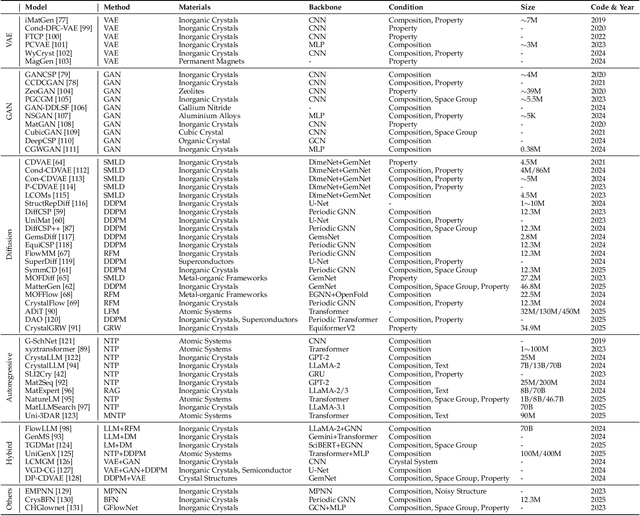
Materials are the foundation of modern society, underpinning advancements in energy, electronics, healthcare, transportation, and infrastructure. The ability to discover and design new materials with tailored properties is critical to solving some of the most pressing global challenges. In recent years, the growing availability of high-quality materials data combined with rapid advances in Artificial Intelligence (AI) has opened new opportunities for accelerating materials discovery. Data-driven generative models provide a powerful tool for materials design by directly create novel materials that satisfy predefined property requirements. Despite the proliferation of related work, there remains a notable lack of up-to-date and systematic surveys in this area. To fill this gap, this paper provides a comprehensive overview of recent progress in AI-driven materials generation. We first organize various types of materials and illustrate multiple representations of crystalline materials. We then provide a detailed summary and taxonomy of current AI-driven materials generation approaches. Furthermore, we discuss the common evaluation metrics and summarize open-source codes and benchmark datasets. Finally, we conclude with potential future directions and challenges in this fast-growing field. The related sources can be found at https://github.com/ZhixunLEE/Awesome-AI-for-Materials-Generation.
IceBerg: Debiased Self-Training for Class-Imbalanced Node Classification
Feb 10, 2025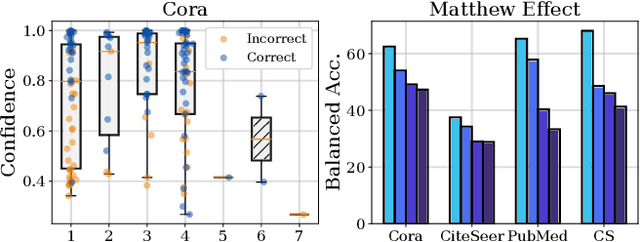
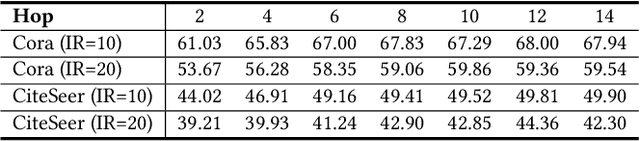
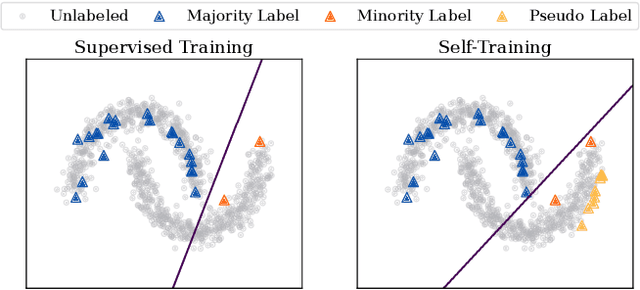
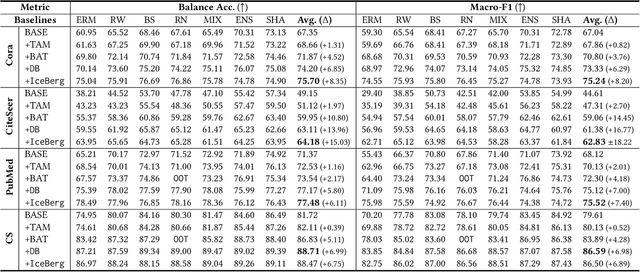
Graph Neural Networks (GNNs) have achieved great success in dealing with non-Euclidean graph-structured data and have been widely deployed in many real-world applications. However, their effectiveness is often jeopardized under class-imbalanced training sets. Most existing studies have analyzed class-imbalanced node classification from a supervised learning perspective, but they do not fully utilize the large number of unlabeled nodes in semi-supervised scenarios. We claim that the supervised signal is just the tip of the iceberg and a large number of unlabeled nodes have not yet been effectively utilized. In this work, we propose IceBerg, a debiased self-training framework to address the class-imbalanced and few-shot challenges for GNNs at the same time. Specifically, to figure out the Matthew effect and label distribution shift in self-training, we propose Double Balancing, which can largely improve the performance of existing baselines with just a few lines of code as a simple plug-and-play module. Secondly, to enhance the long-range propagation capability of GNNs, we disentangle the propagation and transformation operations of GNNs. Therefore, the weak supervision signals can propagate more effectively to address the few-shot issue. In summary, we find that leveraging unlabeled nodes can significantly enhance the performance of GNNs in class-imbalanced and few-shot scenarios, and even small, surgical modifications can lead to substantial performance improvements. Systematic experiments on benchmark datasets show that our method can deliver considerable performance gain over existing class-imbalanced node classification baselines. Additionally, due to IceBerg's outstanding ability to leverage unsupervised signals, it also achieves state-of-the-art results in few-shot node classification scenarios. The code of IceBerg is available at: https://github.com/ZhixunLEE/IceBerg.
CardOOD: Robust Query-driven Cardinality Estimation under Out-of-Distribution
Dec 08, 2024Query-driven learned estimators are accurate, flexible, and lightweight alternatives to traditional estimators in query optimization. However, existing query-driven approaches struggle with the Out-of-distribution (OOD) problem, where the test workload distribution differs from the training workload, leading to performancedegradation. In this paper, we present CardOOD, a general learning framework designed to construct robust query-driven cardinality estimators that are resilient against the OOD problem. Our framework focuses on offline training algorithms that develop one-off models from a static workload, suitable for model initialization and periodic retraining. In CardOOD, we extend classical transfer/robust learning techniques to train query-driven cardinalityestimators, and the algorithms fall into three categories: representation learning, data manipulation, and new learning strategies. As these learning techniques are originally evaluated in computervision tasks, we also propose a new learning algorithm that exploits the property of cardinality estimation. This algorithm, lying in the category of new learning strategy, models the partial order constraint of cardinalities by a self-supervised learning task. Comprehensive experimental studies demonstrate the efficacy of the algorithms of CardOOD in mitigating the OOD problem to varying extents. We further integrate CardOOD into PostgreSQL, showcasing its practical utility in query optimization.
Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems
Oct 03, 2024



Recent advancements in large language model (LLM)-powered agents have shown that collective intelligence can significantly outperform individual capabilities, largely attributed to the meticulously designed inter-agent communication topologies. Though impressive in performance, existing multi-agent pipelines inherently introduce substantial token overhead, as well as increased economic costs, which pose challenges for their large-scale deployments. In response to this challenge, we propose an economical, simple, and robust multi-agent communication framework, termed $\texttt{AgentPrune}$, which can seamlessly integrate into mainstream multi-agent systems and prunes redundant or even malicious communication messages. Technically, $\texttt{AgentPrune}$ is the first to identify and formally define the \textit{communication redundancy} issue present in current LLM-based multi-agent pipelines, and efficiently performs one-shot pruning on the spatial-temporal message-passing graph, yielding a token-economic and high-performing communication topology. Extensive experiments across six benchmarks demonstrate that $\texttt{AgentPrune}$ \textbf{(I)} achieves comparable results as state-of-the-art topologies at merely $\$5.6$ cost compared to their $\$43.7$, \textbf{(II)} integrates seamlessly into existing multi-agent frameworks with $28.1\%\sim72.8\%\downarrow$ token reduction, and \textbf{(III)} successfully defend against two types of agent-based adversarial attacks with $3.5\%\sim10.8\%\uparrow$ performance boost.
Beyond Efficiency: Molecular Data Pruning for Enhanced Generalization
Sep 02, 2024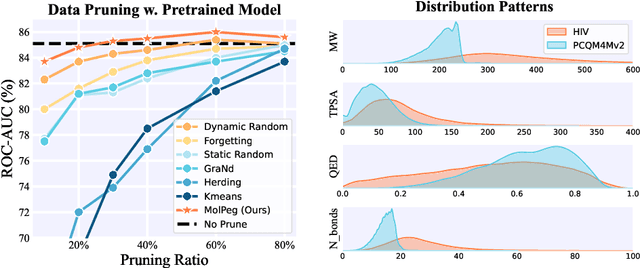
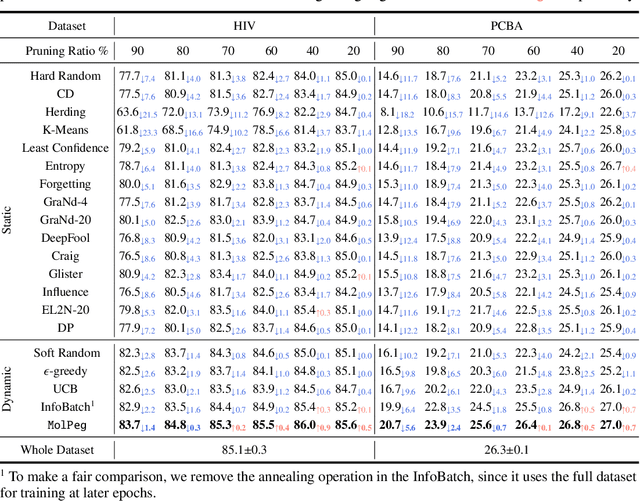
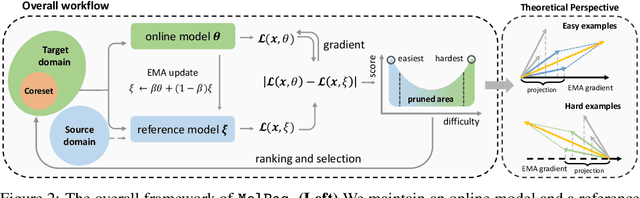

With the emergence of various molecular tasks and massive datasets, how to perform efficient training has become an urgent yet under-explored issue in the area. Data pruning (DP), as an oft-stated approach to saving training burdens, filters out less influential samples to form a coreset for training. However, the increasing reliance on pretrained models for molecular tasks renders traditional in-domain DP methods incompatible. Therefore, we propose a Molecular data Pruning framework for enhanced Generalization (MolPeg), which focuses on the source-free data pruning scenario, where data pruning is applied with pretrained models. By maintaining two models with different updating paces during training, we introduce a novel scoring function to measure the informativeness of samples based on the loss discrepancy. As a plug-and-play framework, MolPeg realizes the perception of both source and target domain and consistently outperforms existing DP methods across four downstream tasks. Remarkably, it can surpass the performance obtained from full-dataset training, even when pruning up to 60-70% of the data on HIV and PCBA dataset. Our work suggests that the discovery of effective data-pruning metrics could provide a viable path to both enhanced efficiency and superior generalization in transfer learning.
Rethinking Fair Graph Neural Networks from Re-balancing
Jul 16, 2024



Driven by the powerful representation ability of Graph Neural Networks (GNNs), plentiful GNN models have been widely deployed in many real-world applications. Nevertheless, due to distribution disparities between different demographic groups, fairness in high-stake decision-making systems is receiving increasing attention. Although lots of recent works devoted to improving the fairness of GNNs and achieved considerable success, they all require significant architectural changes or additional loss functions requiring more hyper-parameter tuning. Surprisingly, we find that simple re-balancing methods can easily match or surpass existing fair GNN methods. We claim that the imbalance across different demographic groups is a significant source of unfairness, resulting in imbalanced contributions from each group to the parameters updating. However, these simple re-balancing methods have their own shortcomings during training. In this paper, we propose FairGB, Fair Graph Neural Network via re-Balancing, which mitigates the unfairness of GNNs by group balancing. Technically, FairGB consists of two modules: counterfactual node mixup and contribution alignment loss. Firstly, we select counterfactual pairs across inter-domain and inter-class, and interpolate the ego-networks to generate new samples. Guided by analysis, we can reveal the debiasing mechanism of our model by the causal view and prove that our strategy can make sensitive attributes statistically independent from target labels. Secondly, we reweigh the contribution of each group according to gradients. By combining these two modules, they can mutually promote each other. Experimental results on benchmark datasets show that our method can achieve state-of-the-art results concerning both utility and fairness metrics. Code is available at https://github.com/ZhixunLEE/FairGB.
All-in-One: Heterogeneous Interaction Modeling for Cold-Start Rating Prediction
Mar 28, 2024



Cold-start rating prediction is a fundamental problem in recommender systems that has been extensively studied. Many methods have been proposed that exploit explicit relations among existing data, such as collaborative filtering, social recommendations and heterogeneous information network, to alleviate the data insufficiency issue for cold-start users and items. However, the explicit relations constructed based on data between different roles may be unreliable and irrelevant, which limits the performance ceiling of the specific recommendation task. Motivated by this, in this paper, we propose a flexible framework dubbed heterogeneous interaction rating network (HIRE). HIRE dose not solely rely on the pre-defined interaction pattern or the manually constructed heterogeneous information network. Instead, we devise a Heterogeneous Interaction Module (HIM) to jointly model the heterogeneous interactions and directly infer the important interactions via the observed data. In the experiments, we evaluate our model under three cold-start settings on three real-world datasets. The experimental results show that HIRE outperforms other baselines by a large margin. Furthermore, we visualize the inferred interactions of HIRE to confirm the contribution of our model.