 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMem-T: Densifying Rewards for Long-Horizon Memory Agents
Jan 30, 2026Memory agents, which depart from predefined memory-processing pipelines by endogenously managing the processing, storage, and retrieval of memories, have garnered increasing attention for their autonomy and adaptability. However, existing training paradigms remain constrained: agents often traverse long-horizon sequences of memory operations before receiving sparse and delayed rewards, which hinders truly end-to-end optimization of memory management policies. To address this limitation, we introduce Mem-T, an autonomous memory agent that interfaces with a lightweight hierarchical memory database to perform dynamic updates and multi-turn retrieval over streaming inputs. To effectively train long-horizon memory management capabilities, we further propose MoT-GRPO, a tree-guided reinforcement learning framework that transforms sparse terminal feedback into dense, step-wise supervision via memory operation tree backpropagation and hindsight credit assignment, thereby enabling the joint optimization of memory construction and retrieval. Extensive experiments demonstrate that Mem-T is (1) high-performing, surpassing frameworks such as A-Mem and Mem0 by up to $14.92\%$, and (2) economical, operating on a favorable accuracy-efficiency Pareto frontier and reducing inference tokens per query by $\sim24.45\%$ relative to GAM without sacrificing performance.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
Fast Track to Winning Tickets: Repowering One-Shot Pruning for Graph Neural Networks
Dec 10, 2024



Graph Neural Networks (GNNs) demonstrate superior performance in various graph learning tasks, yet their wider real-world application is hindered by the computational overhead when applied to large-scale graphs. To address the issue, the Graph Lottery Hypothesis (GLT) has been proposed, advocating the identification of subgraphs and subnetworks, \textit{i.e.}, winning tickets, without compromising performance. The effectiveness of current GLT methods largely stems from the use of iterative magnitude pruning (IMP), which offers higher stability and better performance than one-shot pruning. However, identifying GLTs is highly computationally expensive, due to the iterative pruning and retraining required by IMP. In this paper, we reevaluate the correlation between one-shot pruning and IMP: while one-shot tickets are suboptimal compared to IMP, they offer a \textit{fast track} to tickets with a stronger performance. We introduce a one-shot pruning and denoising framework to validate the efficacy of the \textit{fast track}. Compared to current IMP-based GLT methods, our framework achieves a double-win situation of graph lottery tickets with \textbf{higher sparsity} and \textbf{faster speeds}. Through extensive experiments across 4 backbones and 6 datasets, our method demonstrates $1.32\% - 45.62\%$ improvement in weight sparsity and a $7.49\% - 22.71\%$ increase in graph sparsity, along with a $1.7-44 \times$ speedup over IMP-based methods and $95.3\%-98.6\%$ MAC savings.
G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks
Oct 15, 2024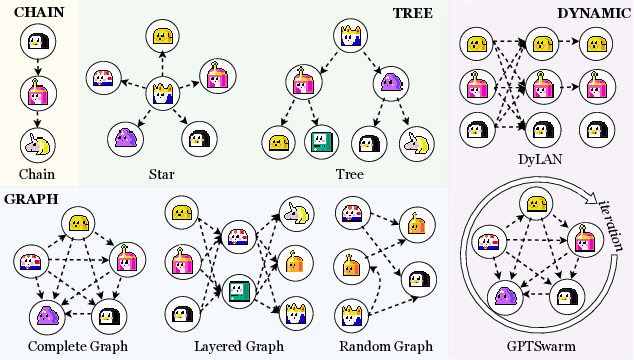
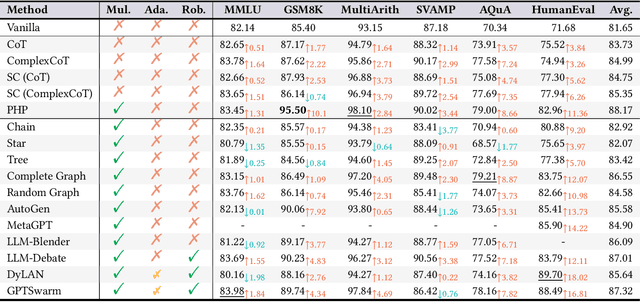
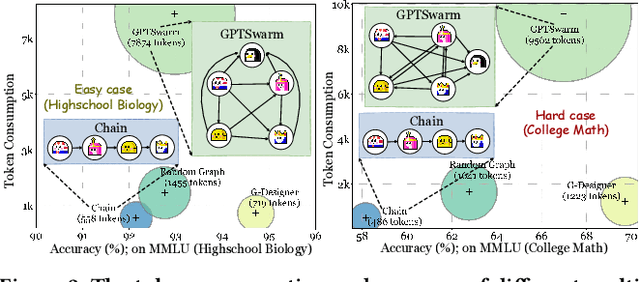
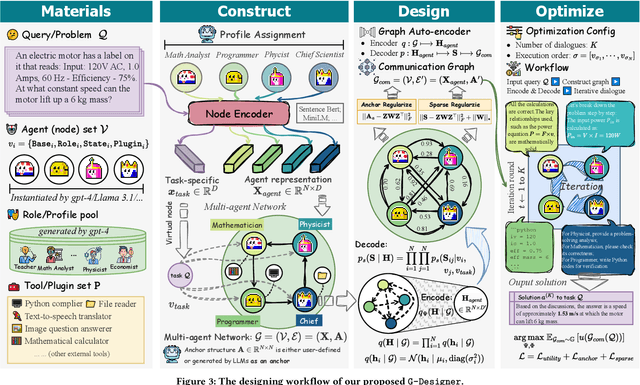
Recent advancements in large language model (LLM)-based agents have demonstrated that collective intelligence can significantly surpass the capabilities of individual agents, primarily due to well-crafted inter-agent communication topologies. Despite the diverse and high-performing designs available, practitioners often face confusion when selecting the most effective pipeline for their specific task: \textit{Which topology is the best choice for my task, avoiding unnecessary communication token overhead while ensuring high-quality solution?} In response to this dilemma, we introduce G-Designer, an adaptive, efficient, and robust solution for multi-agent deployment, which dynamically designs task-aware, customized communication topologies. Specifically, G-Designer models the multi-agent system as a multi-agent network, leveraging a variational graph auto-encoder to encode both the nodes (agents) and a task-specific virtual node, and decodes a task-adaptive and high-performing communication topology. Extensive experiments on six benchmarks showcase that G-Designer is: \textbf{(1) high-performing}, achieving superior results on MMLU with accuracy at $84.50\%$ and on HumanEval with pass@1 at $89.90\%$; \textbf{(2) task-adaptive}, architecting communication protocols tailored to task difficulty, reducing token consumption by up to $95.33\%$ on HumanEval; and \textbf{(3) adversarially robust}, defending against agent adversarial attacks with merely $0.3\%$ accuracy drop.
Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems
Oct 03, 2024



Recent advancements in large language model (LLM)-powered agents have shown that collective intelligence can significantly outperform individual capabilities, largely attributed to the meticulously designed inter-agent communication topologies. Though impressive in performance, existing multi-agent pipelines inherently introduce substantial token overhead, as well as increased economic costs, which pose challenges for their large-scale deployments. In response to this challenge, we propose an economical, simple, and robust multi-agent communication framework, termed $\texttt{AgentPrune}$, which can seamlessly integrate into mainstream multi-agent systems and prunes redundant or even malicious communication messages. Technically, $\texttt{AgentPrune}$ is the first to identify and formally define the \textit{communication redundancy} issue present in current LLM-based multi-agent pipelines, and efficiently performs one-shot pruning on the spatial-temporal message-passing graph, yielding a token-economic and high-performing communication topology. Extensive experiments across six benchmarks demonstrate that $\texttt{AgentPrune}$ \textbf{(I)} achieves comparable results as state-of-the-art topologies at merely $\$5.6$ cost compared to their $\$43.7$, \textbf{(II)} integrates seamlessly into existing multi-agent frameworks with $28.1\%\sim72.8\%\downarrow$ token reduction, and \textbf{(III)} successfully defend against two types of agent-based adversarial attacks with $3.5\%\sim10.8\%\uparrow$ performance boost.
Graph Sparsification via Mixture of Graphs
May 23, 2024



Graph Neural Networks (GNNs) have demonstrated superior performance across various graph learning tasks but face significant computational challenges when applied to large-scale graphs. One effective approach to mitigate these challenges is graph sparsification, which involves removing non-essential edges to reduce computational overhead. However, previous graph sparsification methods often rely on a single global sparsity setting and uniform pruning criteria, failing to provide customized sparsification schemes for each node's complex local context. In this paper, we introduce Mixture-of-Graphs (MoG), leveraging the concept of Mixture-of-Experts (MoE), to dynamically select tailored pruning solutions for each node. Specifically, MoG incorporates multiple sparsifier experts, each characterized by unique sparsity levels and pruning criteria, and selects the appropriate experts for each node. Subsequently, MoG performs a mixture of the sparse graphs produced by different experts on the Grassmann manifold to derive an optimal sparse graph. One notable property of MoG is its entirely local nature, as it depends on the specific circumstances of each individual node. Extensive experiments on four large-scale OGB datasets and two superpixel datasets, equipped with five GNN backbones, demonstrate that MoG (I) identifies subgraphs at higher sparsity levels ($8.67\%\sim 50.85\%$), with performance equal to or better than the dense graph, (II) achieves $1.47-2.62\times$ speedup in GNN inference with negligible performance drop, and (III) boosts ``top-student'' GNN performance ($1.02\%\uparrow$ on RevGNN+\textsc{ogbn-proteins} and $1.74\%\uparrow$ on DeeperGCN+\textsc{ogbg-ppa}).
Two Heads Are Better Than One: Boosting Graph Sparse Training via Semantic and Topological Awareness
Feb 02, 2024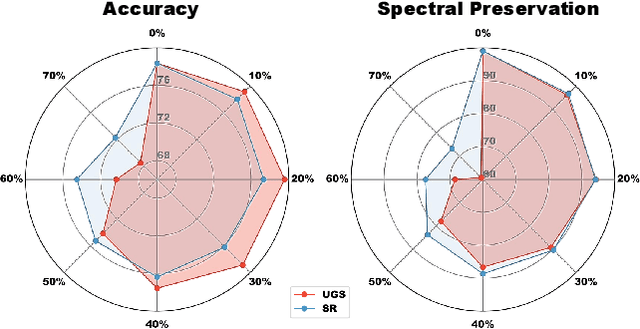
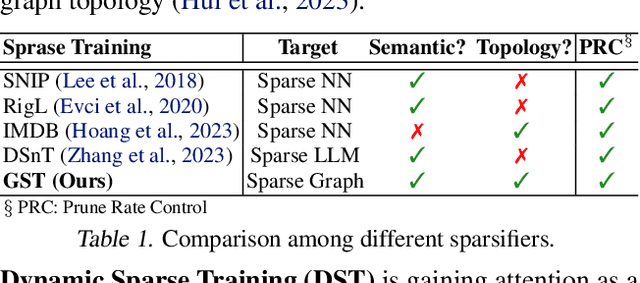
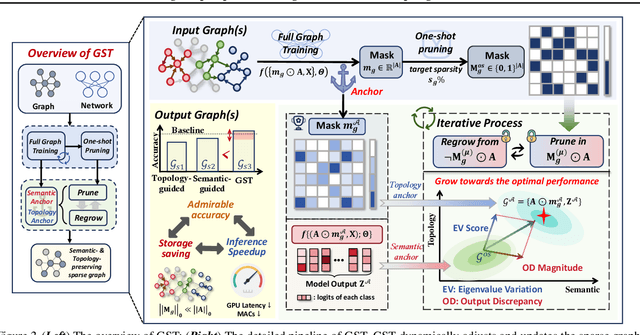
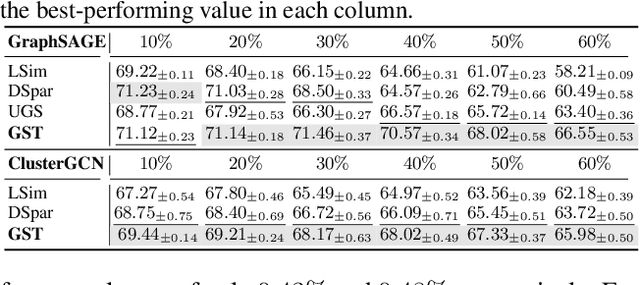
Graph Neural Networks (GNNs) excel in various graph learning tasks but face computational challenges when applied to large-scale graphs. A promising solution is to remove non-essential edges to reduce the computational overheads in GNN. Previous literature generally falls into two categories: topology-guided and semantic-guided. The former maintains certain graph topological properties yet often underperforms on GNNs due to low integration with neural network training. The latter performs well at lower sparsity on GNNs but faces performance collapse at higher sparsity levels. With this in mind, we take the first step to propose a new research line and concept termed Graph Sparse Training (GST), which dynamically manipulates sparsity at the data level. Specifically, GST initially constructs a topology & semantic anchor at a low training cost, followed by performing dynamic sparse training to align the sparse graph with the anchor. We introduce the Equilibria Sparsification Principle to guide this process, effectively balancing the preservation of both topological and semantic information. Ultimately, GST produces a sparse graph with maximum topological integrity and no performance degradation. Extensive experiments on 6 datasets and 5 backbones showcase that GST (I) identifies subgraphs at higher graph sparsity levels (1.67%~15.85% $\uparrow$) than state-of-the-art sparsification methods, (II) preserves more key spectral properties, (III) achieves 1.27-3.42$\times$ speedup in GNN inference and (IV) successfully helps graph adversarial defense and graph lottery tickets.