 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Label Cleaning for Reliable Detection of Electron Dense Deposits in Transmission Electron Microscopy Images
Feb 05, 2026Automated detection of electron dense deposits (EDD) in glomerular disease is hindered by the scarcity of high-quality labeled data. While crowdsourcing reduces annotation cost, it introduces label noise. We propose an active label cleaning method to efficiently denoise crowdsourced datasets. Our approach uses active learning to select the most valuable noisy samples for expert re-annotation, building high-accuracy cleaning models. A Label Selection Module leverages discrepancies between crowdsourced labels and model predictions for both sample selection and instance-level noise grading. Experiments show our method achieves 67.18% AP\textsubscript{50} on a private dataset, an 18.83% improvement over training on noisy labels. This performance reaches 95.79% of that with full expert annotation while reducing annotation cost by 73.30%. The method provides a practical, cost-effective solution for developing reliable medical AI with limited expert resources.
LatentMem: Customizing Latent Memory for Multi-Agent Systems
Feb 03, 2026Large language model (LLM)-powered multi-agent systems (MAS) demonstrate remarkable collective intelligence, wherein multi-agent memory serves as a pivotal mechanism for continual adaptation. However, existing multi-agent memory designs remain constrained by two fundamental bottlenecks: (i) memory homogenization arising from the absence of role-aware customization, and (ii) information overload induced by excessively fine-grained memory entries. To address these limitations, we propose LatentMem, a learnable multi-agent memory framework designed to customize agent-specific memories in a token-efficient manner. Specifically, LatentMem comprises an experience bank that stores raw interaction trajectories in a lightweight form, and a memory composer that synthesizes compact latent memories conditioned on retrieved experience and agent-specific contexts. Further, we introduce Latent Memory Policy Optimization (LMPO), which propagates task-level optimization signals through latent memories to the composer, encouraging it to produce compact and high-utility representations. Extensive experiments across diverse benchmarks and mainstream MAS frameworks show that LatentMem achieves a performance gain of up to $19.36$% over vanilla settings and consistently outperforms existing memory architectures, without requiring any modifications to the underlying frameworks.
A-MapReduce: Executing Wide Search via Agentic MapReduce
Feb 01, 2026Contemporary large language model (LLM)-based multi-agent systems exhibit systematic advantages in deep research tasks, which emphasize iterative, vertically structured information seeking. However, when confronted with wide search tasks characterized by large-scale, breadth-oriented retrieval, existing agentic frameworks, primarily designed around sequential, vertically structured reasoning, remain stuck in expansive search objectives and inefficient long-horizon execution. To bridge this gap, we propose A-MapReduce, a MapReduce paradigm-inspired multi-agent execution framework that recasts wide search as a horizontally structured retrieval problem. Concretely, A-MapReduce implements parallel processing of massive retrieval targets through task-adaptive decomposition and structured result aggregation. Meanwhile, it leverages experiential memory to drive the continual evolution of query-conditioned task allocation and recomposition, enabling progressive improvement in large-scale wide-search regimes. Extensive experiments on five agentic benchmarks demonstrate that A-MapReduce is (i) high-performing, achieving state-of-the-art performance on WideSearch and DeepWideSearch, and delivering 5.11% - 17.50% average Item F1 improvements compared with strong baselines with OpenAI o3 or Gemini 2.5 Pro backbones; (ii) cost-effective and efficient, delivering superior cost-performance trade-offs and reducing running time by 45.8\% compared to representative multi-agent baselines. The code is available at https://github.com/mingju-c/AMapReduce.
Mem-T: Densifying Rewards for Long-Horizon Memory Agents
Jan 30, 2026Memory agents, which depart from predefined memory-processing pipelines by endogenously managing the processing, storage, and retrieval of memories, have garnered increasing attention for their autonomy and adaptability. However, existing training paradigms remain constrained: agents often traverse long-horizon sequences of memory operations before receiving sparse and delayed rewards, which hinders truly end-to-end optimization of memory management policies. To address this limitation, we introduce Mem-T, an autonomous memory agent that interfaces with a lightweight hierarchical memory database to perform dynamic updates and multi-turn retrieval over streaming inputs. To effectively train long-horizon memory management capabilities, we further propose MoT-GRPO, a tree-guided reinforcement learning framework that transforms sparse terminal feedback into dense, step-wise supervision via memory operation tree backpropagation and hindsight credit assignment, thereby enabling the joint optimization of memory construction and retrieval. Extensive experiments demonstrate that Mem-T is (1) high-performing, surpassing frameworks such as A-Mem and Mem0 by up to $14.92\%$, and (2) economical, operating on a favorable accuracy-efficiency Pareto frontier and reducing inference tokens per query by $\sim24.45\%$ relative to GAM without sacrificing performance.
ToolTok: Tool Tokenization for Efficient and Generalizable GUI Agents
Jan 30, 2026Existing GUI agent models relying on coordinate-based one-step visual grounding struggle with generalizing to varying input resolutions and aspect ratios. Alternatives introduce coordinate-free strategies yet suffer from learning under severe data scarcity. To address the limitations, we propose ToolTok, a novel paradigm of multi-step pathfinding for GUI agents, where operations are modeled as a sequence of progressive tool usage. Specifically, we devise tools aligned with human interaction habits and represent each tool using learnable token embeddings. To enable efficient embedding learning under limited supervision, ToolTok introduces a semantic anchoring mechanism that grounds each tool with semantically related concepts as natural inductive bias. To further enable a pre-trained large language model to progressively acquire tool semantics, we construct an easy-to-hard curriculum consisting of three tasks: token definition question-answering, pure text-guided tool selection, and simplified visual pathfinding. Extensive experiments on multiple benchmarks show that ToolTok achieves superior performance among models of comparable scale (4B) and remains competitive with a substantially larger model (235B). Notably, these results are obtained using less than 1% of the training data required by other post-training approaches. In addition, ToolTok demonstrates strong generalization across unseen scenarios. Our training & inference code is open-source at https://github.com/ZephinueCode/ToolTok.
EvoRoute: Experience-Driven Self-Routing LLM Agent Systems
Jan 06, 2026Complex agentic AI systems, powered by a coordinated ensemble of Large Language Models (LLMs), tool and memory modules, have demonstrated remarkable capabilities on intricate, multi-turn tasks. However, this success is shadowed by prohibitive economic costs and severe latency, exposing a critical, yet underexplored, trade-off. We formalize this challenge as the \textbf{Agent System Trilemma}: the inherent tension among achieving state-of-the-art performance, minimizing monetary cost, and ensuring rapid task completion. To dismantle this trilemma, we introduce EvoRoute, a self-evolving model routing paradigm that transcends static, pre-defined model assignments. Leveraging an ever-expanding knowledge base of prior experience, EvoRoute dynamically selects Pareto-optimal LLM backbones at each step, balancing accuracy, efficiency, and resource use, while continually refining its own selection policy through environment feedback. Experiments on challenging agentic benchmarks such as GAIA and BrowseComp+ demonstrate that EvoRoute, when integrated into off-the-shelf agentic systems, not only sustains or enhances system performance but also reduces execution cost by up to $80\%$ and latency by over $70\%$.
MemEvolve: Meta-Evolution of Agent Memory Systems
Dec 21, 2025Self-evolving memory systems are unprecedentedly reshaping the evolutionary paradigm of large language model (LLM)-based agents. Prior work has predominantly relied on manually engineered memory architectures to store trajectories, distill experience, and synthesize reusable tools, enabling agents to evolve on the fly within environment interactions. However, this paradigm is fundamentally constrained by the staticity of the memory system itself: while memory facilitates agent-level evolving, the underlying memory architecture cannot be meta-adapted to diverse task contexts. To address this gap, we propose MemEvolve, a meta-evolutionary framework that jointly evolves agents' experiential knowledge and their memory architecture, allowing agent systems not only to accumulate experience but also to progressively refine how they learn from it. To ground MemEvolve in prior research and foster openness in future self-evolving systems, we introduce EvolveLab, a unified self-evolving memory codebase that distills twelve representative memory systems into a modular design space (encode, store, retrieve, manage), providing both a standardized implementation substrate and a fair experimental arena. Extensive evaluations on four challenging agentic benchmarks demonstrate that MemEvolve achieves (I) substantial performance gains, improving frameworks such as SmolAgent and Flash-Searcher by up to $17.06\%$; and (II) strong cross-task and cross-LLM generalization, designing memory architectures that transfer effectively across diverse benchmarks and backbone models.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
Nov 14, 2025Despite the remarkable success of Vision-Language Models (VLMs), their performance on a range of complex visual tasks is often hindered by a "visual processing bottleneck": a propensity to lose grounding in visual evidence and exhibit a deficit in contextualized visual experience during prolonged generation. Drawing inspiration from human cognitive memory theory, which distinguishes short-term visually-dominant memory and long-term semantically-dominant memory, we propose VisMem, a cognitively-aligned framework that equips VLMs with dynamic latent vision memories, a short-term module for fine-grained perceptual retention and a long-term module for abstract semantic consolidation. These memories are seamlessly invoked during inference, allowing VLMs to maintain both perceptual fidelity and semantic consistency across thinking and generation. Extensive experiments across diverse visual benchmarks for understanding, reasoning, and generation reveal that VisMem delivers a significant average performance boost of 11.8% relative to the vanilla model and outperforms all counterparts, establishing a new paradigm for latent-space memory enhancement. The code will be available: https://github.com/YU-deep/VisMem.git.
Glocal Information Bottleneck for Time Series Imputation
Oct 06, 2025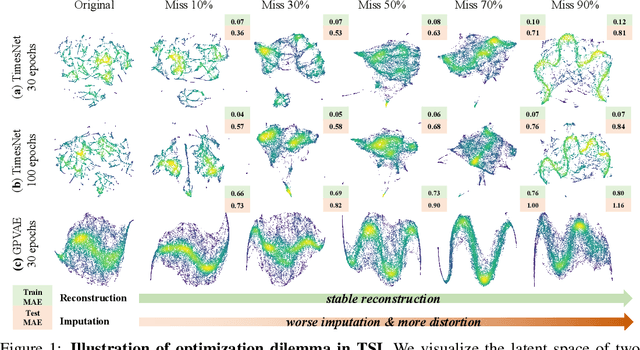



Time Series Imputation (TSI), which aims to recover missing values in temporal data, remains a fundamental challenge due to the complex and often high-rate missingness in real-world scenarios. Existing models typically optimize the point-wise reconstruction loss, focusing on recovering numerical values (local information). However, we observe that under high missing rates, these models still perform well in the training phase yet produce poor imputations and distorted latent representation distributions (global information) in the inference phase. This reveals a critical optimization dilemma: current objectives lack global guidance, leading models to overfit local noise and fail to capture global information of the data. To address this issue, we propose a new training paradigm, Glocal Information Bottleneck (Glocal-IB). Glocal-IB is model-agnostic and extends the standard IB framework by introducing a Global Alignment loss, derived from a tractable mutual information approximation. This loss aligns the latent representations of masked inputs with those of their originally observed counterparts. It helps the model retain global structure and local details while suppressing noise caused by missing values, giving rise to better generalization under high missingness. Extensive experiments on nine datasets confirm that Glocal-IB leads to consistently improved performance and aligned latent representations under missingness. Our code implementation is available in https://github.com/Muyiiiii/NeurIPS-25-Glocal-IB.