 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy and World Modeling Co-Training for Language Agents
Jun 01, 2026Reinforcement learning (RL) improves large language model (LLM) agents by teaching them which actions lead to high rewards, but provides little supervision on what those actions do to the environment. World modeling (WM) can fill this gap, yet existing approaches often require separate simulators, extra training stages, or additional inference-time computation. We observe that on-policy RL rollouts already contain the needed signal: each transition pairs an action with its resulting next observation. Based on this observation, we propose PaW, a Policy and World modeling co-training framework that adds auxiliary WM supervision to the same policy during RL, without changing the inference paradigm. To make auxiliary WM supervision informative and stable, PaW introduces three components: action-entropy-based WM data selection, noise-tolerant WM loss, and reward-adaptive loss balancing. Experiments on three agentic task benchmarks show consistent improvements over strong RL baselines across models and RL algorithms. These results suggest that standard RL rollouts are a practical source of WM supervision for language-agent training.
Neural QAOA$^{2}$: Differentiable Joint Graph Partitioning and Parameter Initialization for Quantum Combinatorial Optimization
May 13, 2026The quantum approximate optimization algorithm (QAOA) holds promise for combinatorial optimization but is constrained by limited qubits. While divide-and-conquer frameworks like QAOA$^{2}$ address scalability by partitioning graphs into subgraphs, existing methods suffer from two fundamental limitations: i) misalignment between heuristic partitioning metrics and quantum optimization goals, and ii) topology-blind parameter initialization that leads to optimization cold starts. To bridge these gaps, we propose Neural QAOA$^{2}$, an end-to-end differentiable framework that jointly generates graph partitions and initial parameters. By integrating a generative evaluative network (GEN), our method utilizes a differentiable quantum evaluator as a high-fidelity performance surrogate to provide direct gradient guidance, enabling the joint generator to learn the intrinsic mapping from graph topology to high-quality partition and parameter configurations. Extensive experiments on 183 QUBO, Ising, and MaxCut instances (21 to 1000 variables) demonstrate that our gradient-driven approach broadly outperforms heuristic baselines, ranking first on 101 instances. It exhibits zero-shot generalization across out-of-distribution graph topologies and scales.
ClipGStream: Clip-Stream Gaussian Splatting for Any Length and Any Motion Multi-View Dynamic Scene Reconstruction
Apr 15, 2026Dynamic 3D scene reconstruction is essential for immersive media such as VR, MR, and XR, yet remains challenging for long multi-view sequences with large-scale motion. Existing dynamic Gaussian approaches are either Frame-Stream, offering scalability but poor temporal stability, or Clip, achieving local consistency at the cost of high memory and limited sequence length. We propose ClipGStream, a hybrid reconstruction framework that performs stream optimization at the clip level rather than the frame level. The sequence is divided into short clips, where dynamic motion is modeled using clip-independent spatio-temporal fields and residual anchor compensation to capture local variations efficiently, while inter-clip inherited anchors and decoders maintain structural consistency across clips. This Clip-Stream design enables scalable, flicker-free reconstruction of long dynamic videos with high temporal coherence and reduced memory overhead. Extensive experiments demonstrate that ClipGStream achieves state-of-the-art reconstruction quality and efficiency. The project page is available at: https://liangjie1999.github.io/ClipGStreamWeb/
Train at Moving Edge: Online-Verified Prompt Selection for Efficient RL Training of Large Reasoning Model
Mar 26, 2026Reinforcement learning (RL) has become essential for post-training large language models (LLMs) in reasoning tasks. While scaling rollouts can stabilize training and enhance performance, the computational overhead is a critical issue. In algorithms like GRPO, multiple rollouts per prompt incur prohibitive costs, as a large portion of prompts provide negligible gradients and are thus of low utility. To address this problem, we investigate how to select high-utility prompts before the rollout phase. Our experimental analysis reveals that sample utility is non-uniform and evolving: the strongest learning signals concentrate at the ``learning edge", the intersection of intermediate difficulty and high uncertainty, which shifts as training proceeds. Motivated by this, we propose HIVE (History-Informed and online-VErified prompt selection), a dual-stage framework for data-efficient RL. HIVE utilizes historical reward trajectories for coarse selection and employs prompt entropy as a real-time proxy to prune instances with stale utility. By evaluating HIVE across multiple math reasoning benchmarks and models, we show that HIVE yields significant rollout efficiency without compromising performance.
Intrinsic Geometry-Appearance Consistency Optimization for Sparse-View Gaussian Splatting
Mar 03, 20263D human reconstruction from a single image is a challenging problem and has been exclusively studied in the literature. Recently, some methods have resorted to diffusion models for guidance, optimizing a 3D representation via Score Distillation Sampling(SDS) or generating a back-view image for facilitating reconstruction. However, these methods tend to produce unsatisfactory artifacts (\textit{e.g.} flattened human structure or over-smoothing results caused by inconsistent priors from multiple views) and struggle with real-world generalization in the wild. In this work, we present \emph{MVD-HuGaS}, enabling free-view 3D human rendering from a single image via a multi-view human diffusion model. We first generate multi-view images from the single reference image with an enhanced multi-view diffusion model, which is well fine-tuned on high-quality 3D human datasets to incorporate 3D geometry priors and human structure priors. To infer accurate camera poses from the sparse generated multi-view images for reconstruction, an alignment module is introduced to facilitate joint optimization of 3D Gaussians and camera poses. Furthermore, we propose a depth-based Facial Distortion Mitigation module to refine the generated facial regions, thereby improving the overall fidelity of the reconstruction. Finally, leveraging the refined multi-view images, along with their accurate camera poses, MVD-HuGaS optimizes the 3D Gaussians of the target human for high-fidelity free-view renderings. Extensive experiments on Thuman2.0 and 2K2K datasets show that the proposed MVD-HuGaS achieves state-of-the-art performance on single-view 3D human rendering.
Principled Synthetic Data Enables the First Scaling Laws for LLMs in Recommendation
Feb 07, 2026Large Language Models (LLMs) represent a promising frontier for recommender systems, yet their development has been impeded by the absence of predictable scaling laws, which are crucial for guiding research and optimizing resource allocation. We hypothesize that this may be attributed to the inherent noise, bias, and incompleteness of raw user interaction data in prior continual pre-training (CPT) efforts. This paper introduces a novel, layered framework for generating high-quality synthetic data that circumvents such issues by creating a curated, pedagogical curriculum for the LLM. We provide powerful, direct evidence for the utility of our curriculum by showing that standard sequential models trained on our principled synthetic data significantly outperform ($+130\%$ on recall@100 for SasRec) models trained on real data in downstream ranking tasks, demonstrating its superiority for learning generalizable user preference patterns. Building on this, we empirically demonstrate, for the first time, robust power-law scaling for an LLM that is continually pre-trained on our high-quality, recommendation-specific data. Our experiments reveal consistent and predictable perplexity reduction across multiple synthetic data modalities. These findings establish a foundational methodology for reliable scaling LLM capabilities in the recommendation domain, thereby shifting the research focus from mitigating data deficiencies to leveraging high-quality, structured information.
PEAR: Pixel-aligned Expressive humAn mesh Recovery
Jan 30, 2026Reconstructing detailed 3D human meshes from a single in-the-wild image remains a fundamental challenge in computer vision. Existing SMPLX-based methods often suffer from slow inference, produce only coarse body poses, and exhibit misalignments or unnatural artifacts in fine-grained regions such as the face and hands. These issues make current approaches difficult to apply to downstream tasks. To address these challenges, we propose PEAR-a fast and robust framework for pixel-aligned expressive human mesh recovery. PEAR explicitly tackles three major limitations of existing methods: slow inference, inaccurate localization of fine-grained human pose details, and insufficient facial expression capture. Specifically, to enable real-time SMPLX parameter inference, we depart from prior designs that rely on high resolution inputs or multi-branch architectures. Instead, we adopt a clean and unified ViT-based model capable of recovering coarse 3D human geometry. To compensate for the loss of fine-grained details caused by this simplified architecture, we introduce pixel-level supervision to optimize the geometry, significantly improving the reconstruction accuracy of fine-grained human details. To make this approach practical, we further propose a modular data annotation strategy that enriches the training data and enhances the robustness of the model. Overall, PEAR is a preprocessing-free framework that can simultaneously infer EHM-s (SMPLX and scaled-FLAME) parameters at over 100 FPS. Extensive experiments on multiple benchmark datasets demonstrate that our method achieves substantial improvements in pose estimation accuracy compared to previous SMPLX-based approaches. Project page: https://wujh2001.github.io/PEAR
MANGO:Natural Multi-speaker 3D Talking Head Generation via 2D-Lifted Enhancement
Jan 05, 2026Current audio-driven 3D head generation methods mainly focus on single-speaker scenarios, lacking natural, bidirectional listen-and-speak interaction. Achieving seamless conversational behavior, where speaking and listening states transition fluidly remains a key challenge. Existing 3D conversational avatar approaches rely on error-prone pseudo-3D labels that fail to capture fine-grained facial dynamics. To address these limitations, we introduce a novel two-stage framework MANGO, which leveraging pure image-level supervision by alternately training to mitigate the noise introduced by pseudo-3D labels, thereby achieving better alignment with real-world conversational behaviors. Specifically, in the first stage, a diffusion-based transformer with a dual-audio interaction module models natural 3D motion from multi-speaker audio. In the second stage, we use a fast 3D Gaussian Renderer to generate high-fidelity images and provide 2D-level photometric supervision for the 3D motions through alternate training. Additionally, we introduce MANGO-Dialog, a high-quality dataset with over 50 hours of aligned 2D-3D conversational data across 500+ identities. Extensive experiments demonstrate that our method achieves exceptional accuracy and realism in modeling two-person 3D dialogue motion, significantly advancing the fidelity and controllability of audio-driven talking heads.
A Neuro-Symbolic Framework for Reasoning under Perceptual Uncertainty: Bridging Continuous Perception and Discrete Symbolic Planning
Nov 18, 2025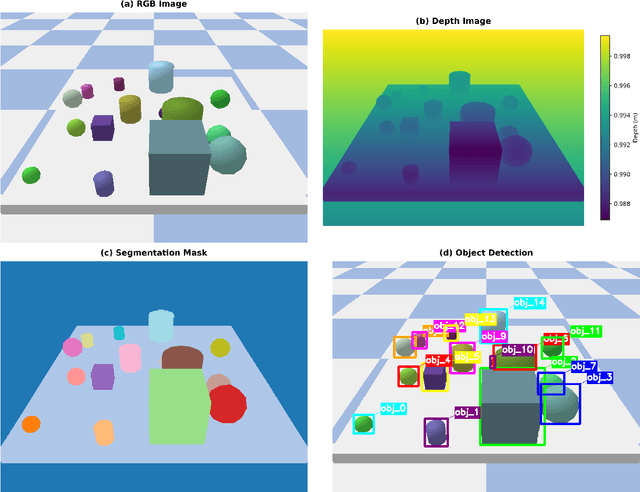
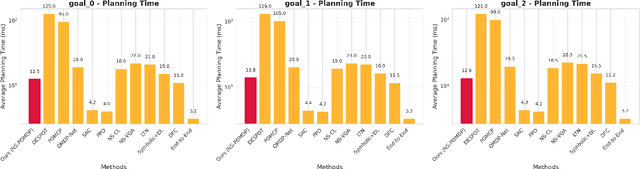
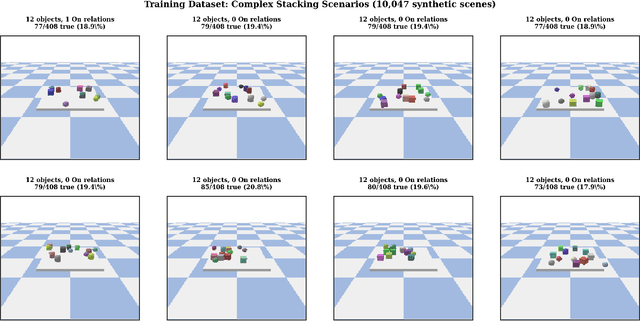

Bridging continuous perceptual signals and discrete symbolic reasoning is a fundamental challenge in AI systems that must operate under uncertainty. We present a neuro-symbolic framework that explicitly models and propagates uncertainty from perception to planning, providing a principled connection between these two abstraction levels. Our approach couples a transformer-based perceptual front-end with graph neural network (GNN) relational reasoning to extract probabilistic symbolic states from visual observations, and an uncertainty-aware symbolic planner that actively gathers information when confidence is low. We demonstrate the framework's effectiveness on tabletop robotic manipulation as a concrete application: the translator processes 10,047 PyBullet-generated scenes (3--10 objects) and outputs probabilistic predicates with calibrated confidences (overall F1=0.68). When embedded in the planner, the system achieves 94\%/90\%/88\% success on Simple Stack, Deep Stack, and Clear+Stack benchmarks (90.7\% average), exceeding the strongest POMDP baseline by 10--14 points while planning within 15\,ms. A probabilistic graphical-model analysis establishes a quantitative link between calibrated uncertainty and planning convergence, providing theoretical guarantees that are validated empirically. The framework is general-purpose and can be applied to any domain requiring uncertainty-aware reasoning from perceptual input to symbolic planning.
Personalized Treatment Outcome Prediction from Scarce Data via Dual-Channel Knowledge Distillation and Adaptive Fusion
Oct 30, 2025Personalized treatment outcome prediction based on trial data for small-sample and rare patient groups is critical in precision medicine. However, the costly trial data limit the prediction performance. To address this issue, we propose a cross-fidelity knowledge distillation and adaptive fusion network (CFKD-AFN), which leverages abundant but low-fidelity simulation data to enhance predictions on scarce but high-fidelity trial data. CFKD-AFN incorporates a dual-channel knowledge distillation module to extract complementary knowledge from the low-fidelity model, along with an attention-guided fusion module to dynamically integrate multi-source information. Experiments on treatment outcome prediction for the chronic obstructive pulmonary disease demonstrates significant improvements of CFKD-AFN over state-of-the-art methods in prediction accuracy, ranging from 6.67\% to 74.55\%, and strong robustness to varying high-fidelity dataset sizes. Furthermore, we extend CFKD-AFN to an interpretable variant, enabling the exploration of latent medical semantics to support clinical decision-making.