 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemDiff: Generating Natural Unrestricted Adversarial Examples via Semantic Attributes Optimization in Diffusion Models
Apr 16, 2025Unrestricted adversarial examples (UAEs), allow the attacker to create non-constrained adversarial examples without given clean samples, posing a severe threat to the safety of deep learning models. Recent works utilize diffusion models to generate UAEs. However, these UAEs often lack naturalness and imperceptibility due to simply optimizing in intermediate latent noises. In light of this, we propose SemDiff, a novel unrestricted adversarial attack that explores the semantic latent space of diffusion models for meaningful attributes, and devises a multi-attributes optimization approach to ensure attack success while maintaining the naturalness and imperceptibility of generated UAEs. We perform extensive experiments on four tasks on three high-resolution datasets, including CelebA-HQ, AFHQ and ImageNet. The results demonstrate that SemDiff outperforms state-of-the-art methods in terms of attack success rate and imperceptibility. The generated UAEs are natural and exhibit semantically meaningful changes, in accord with the attributes' weights. In addition, SemDiff is found capable of evading different defenses, which further validates its effectiveness and threatening.
Octopus Inspired Optimization Algorithm: Multi-Level Structures and Parallel Computing Strategies
Oct 10, 2024



This paper introduces a novel bionic intelligent optimisation algorithm, Octopus Inspired Optimization (OIO) algorithm, which is inspired by the neural structure of octopus, especially its hierarchical and decentralised interaction properties. By simulating the sensory, decision-making, and executive abilities of octopuses, the OIO algorithm adopts a multi-level hierarchical strategy, including tentacles, suckers, individuals and groups, to achieve an effective combination of global and local search. This hierarchical design not only enhances the flexibility and efficiency of the algorithm, but also significantly improves its search efficiency and adaptability. In performance evaluations, including comparisons with existing mainstream intelligent optimisation algorithms, OIO shows faster convergence and higher accuracy, especially when dealing with multimodal functions and high-dimensional optimisation problems. This advantage is even more pronounced as the required minimum accuracy is higher, with the OIO algorithm showing an average speedup of 2.27 times that of conventional particle swarm optimisation (PSO) and 9.63 times that of differential evolution (DE) on multimodal functions. In particular, when dealing with high-dimensional optimisation problems, OIO achieves an average speed of 10.39 times that of DE, demonstrating its superior computational efficiency. In addition, the OIO algorithm also shows a reduction of about $5\%$ in CPU usage efficiency compared to PSO, which is reflected in the efficiency of CPU resource usage also shows its efficiency. These features make the OIO algorithm show great potential in complex optimisation problems, and it is especially suitable for application scenarios that require fast, efficient and robust optimisation methods, such as robot path planning, supply chain management optimisation, and energy system management.
Trajectory Planning for Autonomous Driving in Unstructured Scenarios Based on Graph Neural Network and Numerical Optimization
Jun 13, 2024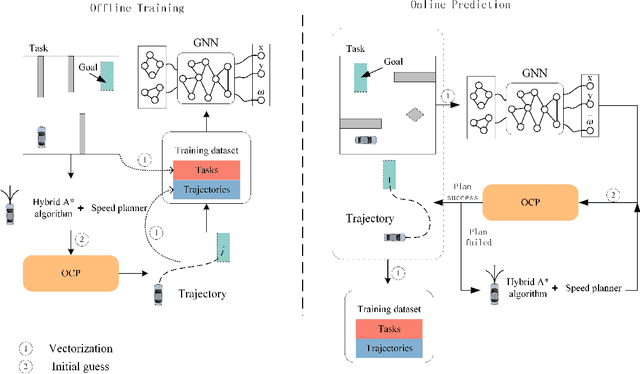
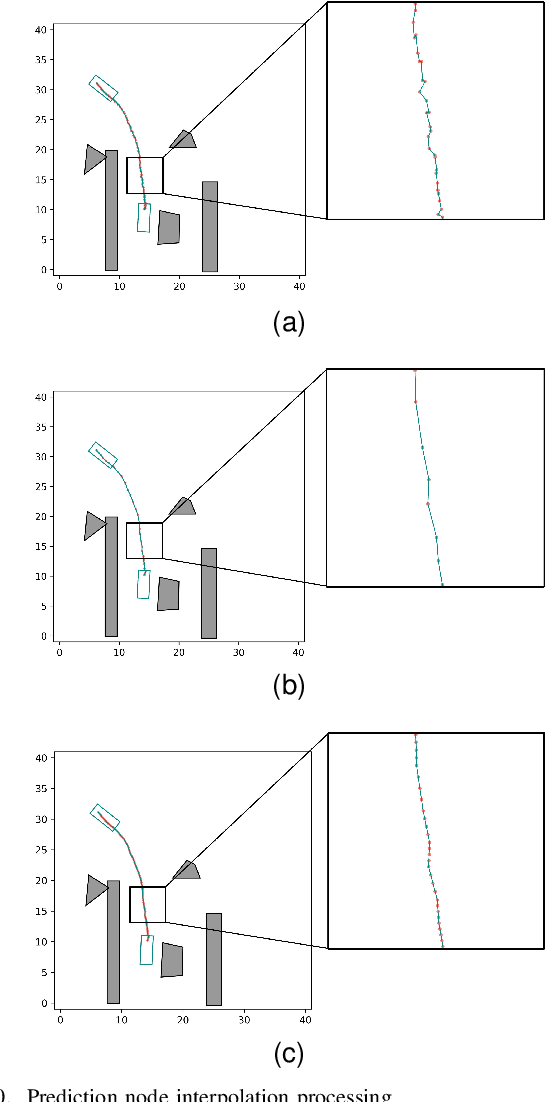
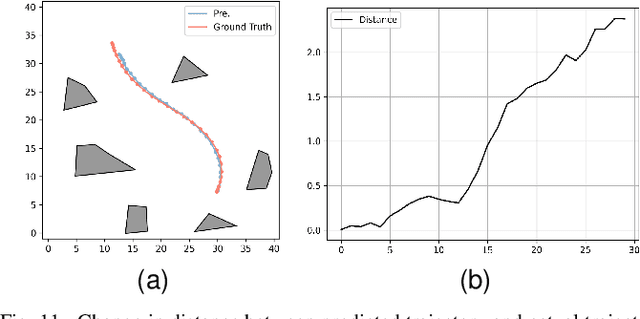
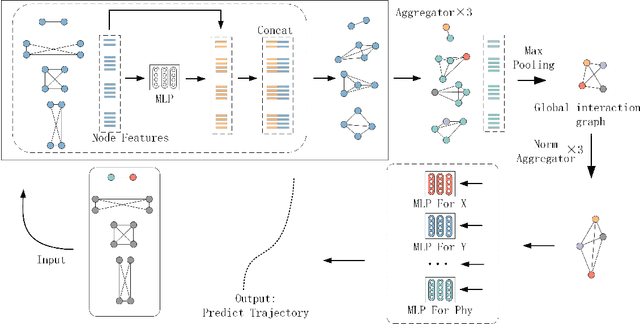
In unstructured environments, obstacles are diverse and lack lane markings, making trajectory planning for intelligent vehicles a challenging task. Traditional trajectory planning methods typically involve multiple stages, including path planning, speed planning, and trajectory optimization. These methods require the manual design of numerous parameters for each stage, resulting in significant workload and computational burden. While end-to-end trajectory planning methods are simple and efficient, they often fail to ensure that the trajectory meets vehicle dynamics and obstacle avoidance constraints in unstructured scenarios. Therefore, this paper proposes a novel trajectory planning method based on Graph Neural Networks (GNN) and numerical optimization. The proposed method consists of two stages: (1) initial trajectory prediction using the GNN, (2) trajectory optimization using numerical optimization. First, the graph neural network processes the environment information and predicts a rough trajectory, replacing traditional path and speed planning. This predicted trajectory serves as the initial solution for the numerical optimization stage, which optimizes the trajectory to ensure compliance with vehicle dynamics and obstacle avoidance constraints. We conducted simulation experiments to validate the feasibility of the proposed algorithm and compared it with other mainstream planning algorithms. The results demonstrate that the proposed method simplifies the trajectory planning process and significantly improves planning efficiency.
A Point-Neighborhood Learning Framework for Nasal Endoscope Image Segmentation
May 30, 2024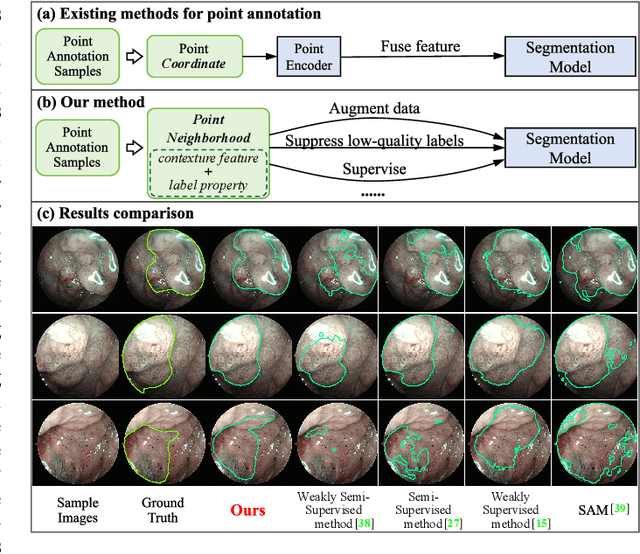
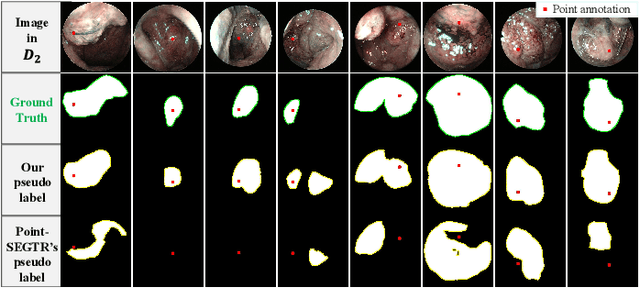
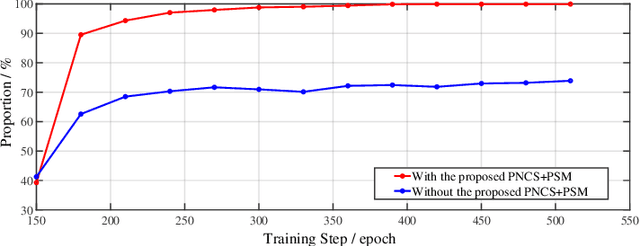
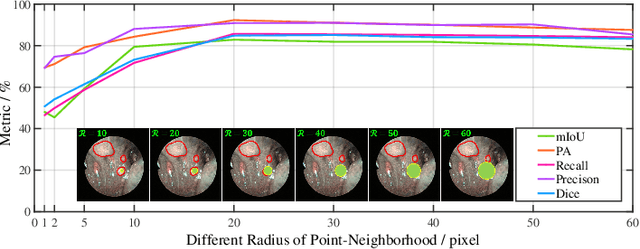
The lesion segmentation on endoscopic images is challenging due to its complex and ambiguous features. Fully-supervised deep learning segmentation methods can receive good performance based on entirely pixel-level labeled dataset but greatly increase experts' labeling burden. Semi-supervised and weakly supervised methods can ease labeling burden, but heavily strengthen the learning difficulty. To alleviate this difficulty, weakly semi-supervised segmentation adopts a new annotation protocol of adding a large number of point annotation samples into a few pixel-level annotation samples. However, existing methods only mine points' limited information while ignoring reliable prior surrounding the point annotations. In this paper, we propose a weakly semi-supervised method called Point-Neighborhood Learning (PNL) framework. To mine the prior of the pixels surrounding the annotated point, we transform a single-point annotation into a circular area named a point-neighborhood. We propose point-neighborhood supervision loss and pseudo-label scoring mechanism to enhance training supervision. Point-neighborhoods are also used to augment the data diversity. Our method greatly improves performance without changing the structure of segmentation network. Comprehensive experiments show the superiority of our method over the other existing methods, demonstrating its effectiveness in point-annotated medical images. The project code will be available on: https://github.com/ParryJay/PNL.
CVPR 2023 Text Guided Video Editing Competition
Oct 24, 2023



Humans watch more than a billion hours of video per day. Most of this video was edited manually, which is a tedious process. However, AI-enabled video-generation and video-editing is on the rise. Building on text-to-image models like Stable Diffusion and Imagen, generative AI has improved dramatically on video tasks. But it's hard to evaluate progress in these video tasks because there is no standard benchmark. So, we propose a new dataset for text-guided video editing (TGVE), and we run a competition at CVPR to evaluate models on our TGVE dataset. In this paper we present a retrospective on the competition and describe the winning method. The competition dataset is available at https://sites.google.com/view/loveucvpr23/track4.
Dataset Condensation for Recommendation
Oct 02, 2023Training recommendation models on large datasets often requires significant time and computational resources. Consequently, an emergent imperative has arisen to construct informative, smaller-scale datasets for efficiently training. Dataset compression techniques explored in other domains show potential possibility to address this problem, via sampling a subset or synthesizing a small dataset. However, applying existing approaches to condense recommendation datasets is impractical due to following challenges: (i) sampling-based methods are inadequate in addressing the long-tailed distribution problem; (ii) synthesizing-based methods are not applicable due to discreteness of interactions and large size of recommendation datasets; (iii) neither of them fail to address the specific issue in recommendation of false negative items, where items with potential user interest are incorrectly sampled as negatives owing to insufficient exposure. To bridge this gap, we investigate dataset condensation for recommendation, where discrete interactions are continualized with probabilistic re-parameterization. To avoid catastrophically expensive computations, we adopt a one-step update strategy for inner model training and introducing policy gradient estimation for outer dataset synthesis. To mitigate amplification of long-tailed problem, we compensate long-tailed users in the condensed dataset. Furthermore, we propose to utilize a proxy model to identify false negative items. Theoretical analysis regarding the convergence property is provided. Extensive experiments on multiple datasets demonstrate the efficacy of our method. In particular, we reduce the dataset size by 75% while approximating over 98% of the original performance on Dianping and over 90% on other datasets.
MAE-GEBD:Winning the CVPR'2023 LOVEU-GEBD Challenge
Jun 27, 2023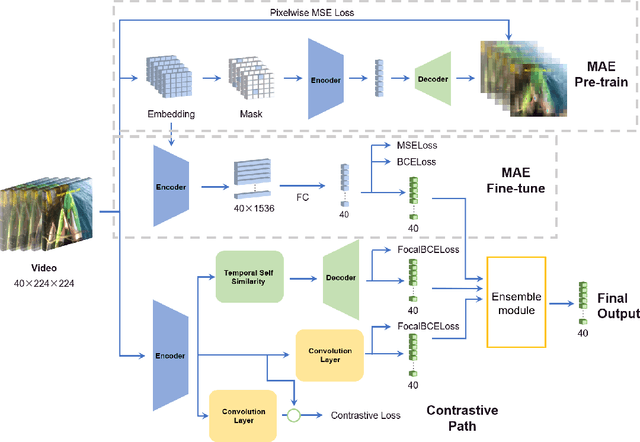
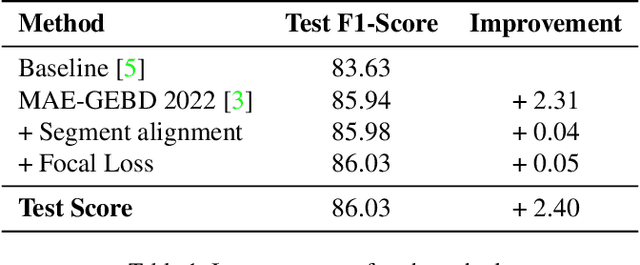
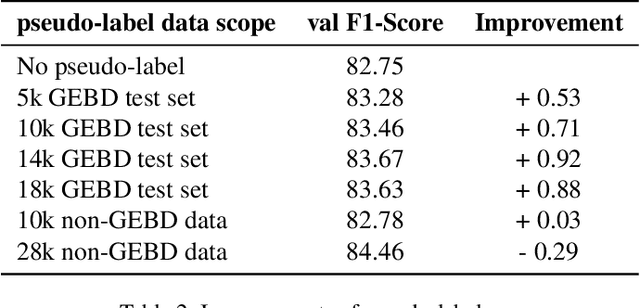
The Generic Event Boundary Detection (GEBD) task aims to build a model for segmenting videos into segments by detecting general event boundaries applicable to various classes. In this paper, based on last year's MAE-GEBD method, we have improved our model performance on the GEBD task by adjusting the data processing strategy and loss function. Based on last year's approach, we extended the application of pseudo-label to a larger dataset and made many experimental attempts. In addition, we applied focal loss to concentrate more on difficult samples and improved our model performance. Finally, we improved the segmentation alignment strategy used last year, and dynamically adjusted the segmentation alignment method according to the boundary density and duration of the video, so that our model can be more flexible and fully applicable in different situations. With our method, we achieve an F1 score of 86.03% on the Kinetics-GEBD test set, which is a 0.09% improvement in the F1 score compared to our 2022 Kinetics-GEBD method.
Perturbation-Based Two-Stage Multi-Domain Active Learning
Jun 19, 2023In multi-domain learning (MDL) scenarios, high labeling effort is required due to the complexity of collecting data from various domains. Active Learning (AL) presents an encouraging solution to this issue by annotating a smaller number of highly informative instances, thereby reducing the labeling effort. Previous research has relied on conventional AL strategies for MDL scenarios, which underutilize the domain-shared information of each instance during the selection procedure. To mitigate this issue, we propose a novel perturbation-based two-stage multi-domain active learning (P2S-MDAL) method incorporated into the well-regarded ASP-MTL model. Specifically, P2S-MDAL involves allocating budgets for domains and establishing regions for diversity selection, which are further used to select the most cross-domain influential samples in each region. A perturbation metric has been introduced to evaluate the robustness of the shared feature extractor of the model, facilitating the identification of potentially cross-domain influential samples. Experiments are conducted on three real-world datasets, encompassing both texts and images. The superior performance over conventional AL strategies shows the effectiveness of the proposed strategy. Additionally, an ablation study has been carried out to demonstrate the validity of each component. Finally, we outline several intriguing potential directions for future MDAL research, thus catalyzing the field's advancement.
Large Language Models can be Guided to Evade AI-Generated Text Detection
May 19, 2023

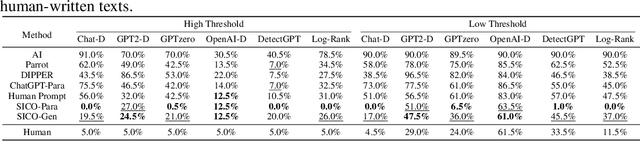

Large Language Models (LLMs) have demonstrated exceptional performance in a variety of tasks, including essay writing and question answering. However, it is crucial to address the potential misuse of these models, which can lead to detrimental outcomes such as plagiarism and spamming. Recently, several detectors have been proposed, including fine-tuned classifiers and various statistical methods. In this study, we reveal that with the aid of carefully crafted prompts, LLMs can effectively evade these detection systems. We propose a novel Substitution-based In-Context example Optimization method (SICO) to automatically generate such prompts. On three real-world tasks where LLMs can be misused, SICO successfully enables ChatGPT to evade six existing detectors, causing a significant 0.54 AUC drop on average. Surprisingly, in most cases these detectors perform even worse than random classifiers. These results firmly reveal the vulnerability of existing detectors. Finally, the strong performance of SICO suggests itself as a reliable evaluation protocol for any new detector in this field.
Multi-Domain Learning From Insufficient Annotations
May 04, 2023Multi-domain learning (MDL) refers to simultaneously constructing a model or a set of models on datasets collected from different domains. Conventional approaches emphasize domain-shared information extraction and domain-private information preservation, following the shared-private framework (SP models), which offers significant advantages over single-domain learning. However, the limited availability of annotated data in each domain considerably hinders the effectiveness of conventional supervised MDL approaches in real-world applications. In this paper, we introduce a novel method called multi-domain contrastive learning (MDCL) to alleviate the impact of insufficient annotations by capturing both semantic and structural information from both labeled and unlabeled data.Specifically, MDCL comprises two modules: inter-domain semantic alignment and intra-domain contrast. The former aims to align annotated instances of the same semantic category from distinct domains within a shared hidden space, while the latter focuses on learning a cluster structure of unlabeled instances in a private hidden space for each domain. MDCL is readily compatible with many SP models, requiring no additional model parameters and allowing for end-to-end training. Experimental results across five textual and image multi-domain datasets demonstrate that MDCL brings noticeable improvement over various SP models.Furthermore, MDCL can further be employed in multi-domain active learning (MDAL) to achieve a superior initialization, eventually leading to better overall performance.