 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-GGPO: Mitigating Double Descent in LoRA Fine-Tuning via Gradient-Guided Perturbation Optimization
Feb 20, 2025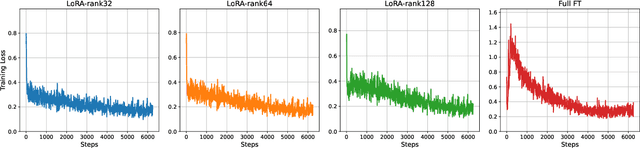
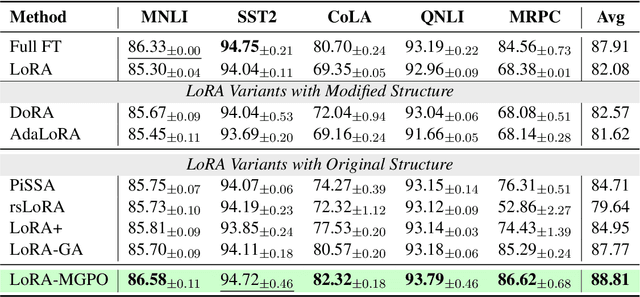
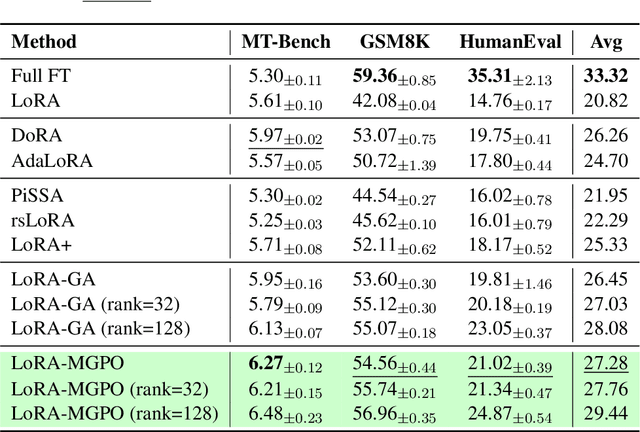
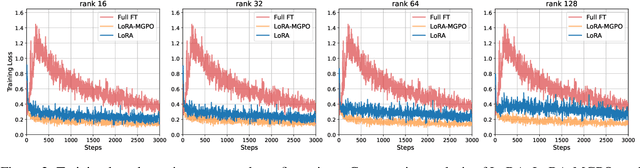
Large Language Models (LLMs) have achieved remarkable success in natural language processing, but their full fine-tuning remains resource-intensive. Parameter-Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), have emerged as a practical solution by approximating parameter updates with low-rank matrices. However, LoRA often exhibits a "double descent" phenomenon during fine-tuning, where model performance degrades due to overfitting and limited expressiveness caused by low-rank constraints. To address this issue, we propose LoRA-GGPO (Gradient-Guided Perturbation Optimization), a novel method that leverages gradient and weight norms to generate targeted perturbations. By optimizing the sharpness of the loss landscape, LoRA-GGPO guides the model toward flatter minima, mitigating the double descent problem and improving generalization. Extensive experiments on natural language understanding (NLU) and generation (NLG) tasks demonstrate that LoRA-GGPO outperforms LoRA and its state-of-the-art variants. Furthermore, extended experiments specifically designed to analyze the double descent phenomenon confirm that LoRA-GGPO effectively alleviates this issue, producing more robust and generalizable models. Our work provides a robust and efficient solution for fine-tuning LLMs, with broad applicability in real-world scenarios. The code is available at https://github.com/llm172/LoRA-GGPO.
Transfer-Prompting: Enhancing Cross-Task Adaptation in Large Language Models via Dual-Stage Prompts Optimization
Feb 20, 2025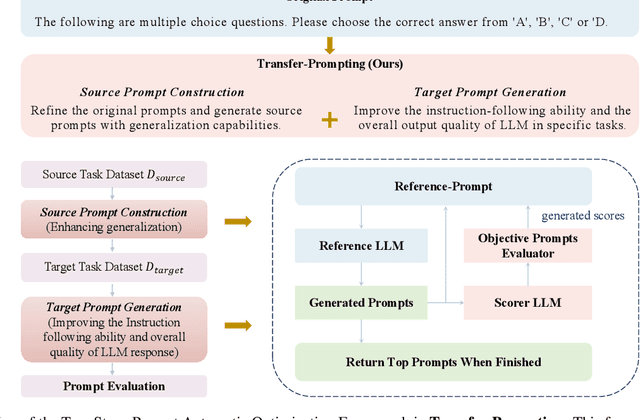
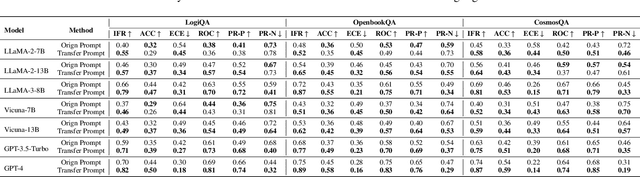

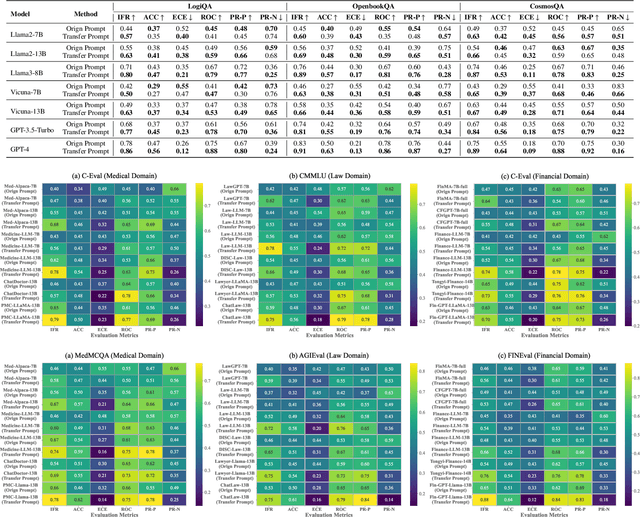
Large language models (LLMs) face significant challenges when balancing multiple high-level objectives, such as generating coherent, relevant, and high-quality responses while maintaining efficient task adaptation across diverse tasks. To address these challenges, we introduce Transfer-Prompting, a novel two-stage framework designed to enhance cross-task adaptation in prompt generation. The framework comprises two key components: (1) source prompt construction, which refines the original prompts on source task datasets to generate source prompts with enhanced generalization ability, and (2) target prompt generation, which enhances cross-task adaptation of target prompts by fine-tuning a set of high-scored source prompts on task-specific datasets. In each optimization cycle, a reference LLM generates candidate prompts based on historical prompt-score pairs and task descriptions in our designed reference prompt. These candidate prompts are refined iteratively, while a scorer LLM evaluates their effectiveness using the multi-dimensional metrics designed in the objective prompts evaluator-a novel contribution in this work that provides a holistic evaluation of prompt quality and task performance. This feedback loop facilitates continuous refinement, optimizing both prompt quality and task-specific outcomes. We validate Transfer-Prompting through extensive experiments across 25 LLMs, including 7 foundational models and 18 specialized models, evaluated on 9 diverse datasets. The results demonstrate that Transfer-Prompting significantly improves task-specific performance, highlighting its potential for enhancing cross-task adaptation in LLMs. The code is available at https://github.com/llm172/Transfer-Prompting.
Bias-Aware Low-Rank Adaptation: Mitigating Catastrophic Inheritance of Large Language Models
Aug 08, 2024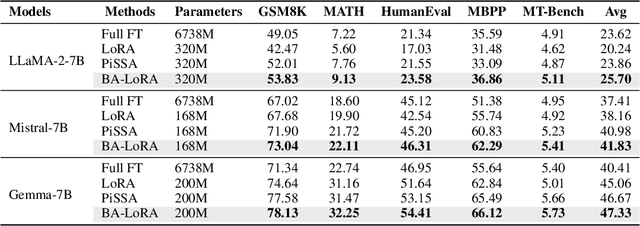
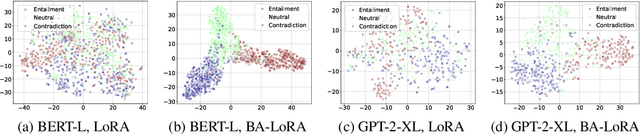
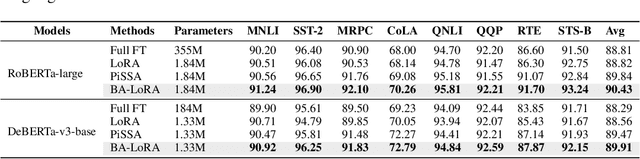
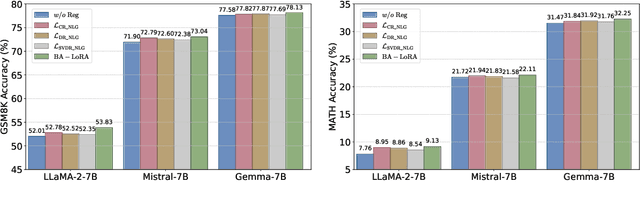
Large language models (LLMs) have exhibited remarkable proficiency across a diverse array of natural language processing (NLP) tasks. However, adapting LLMs to downstream applications typically necessitates computationally intensive and memory-demanding fine-tuning procedures. To mitigate these burdens, parameter-efficient fine-tuning (PEFT) techniques have emerged as a promising approach to tailor LLMs with minimal computational overhead. While PEFT methods offer substantial advantages, they do not fully address the pervasive issue of bias propagation from pre-training data. In this work, we introduce Bias-Aware Low-Rank Adaptation (BA-LoRA), a novel PEFT method designed to counteract bias inheritance. BA-LoRA incorporates three distinct regularization terms: (1) consistency regularizer, (2) diversity regularizer, and (3) singular vector decomposition regularizer. These regularizers collectively aim to improve the generative models' consistency, diversity, and generalization capabilities during the fine-tuning process. Through extensive experiments on a variety of natural language understanding (NLU) and natural language generation (NLG) tasks, employing prominent LLMs such as LLaMA, Mistral, and Gemma, we demonstrate that BA-LoRA surpasses the performance of LoRA and its state-of-the-art variants. Moreover, our method effectively mitigates the deleterious effects of pre-training bias, leading to more reliable and robust model outputs. The code is available at https://github.com/cyp-jlu-ai/BA-LoRA.
Trajectory Planning for Autonomous Driving in Unstructured Scenarios Based on Graph Neural Network and Numerical Optimization
Jun 13, 2024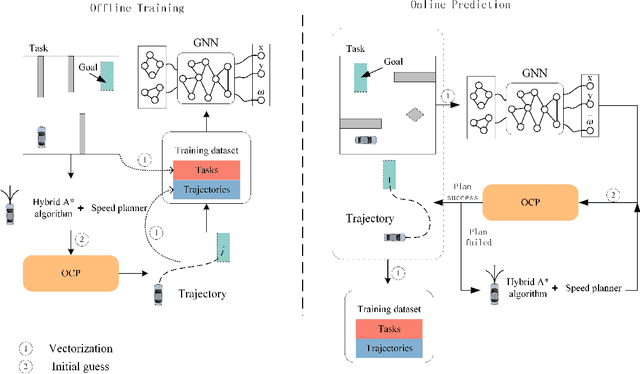
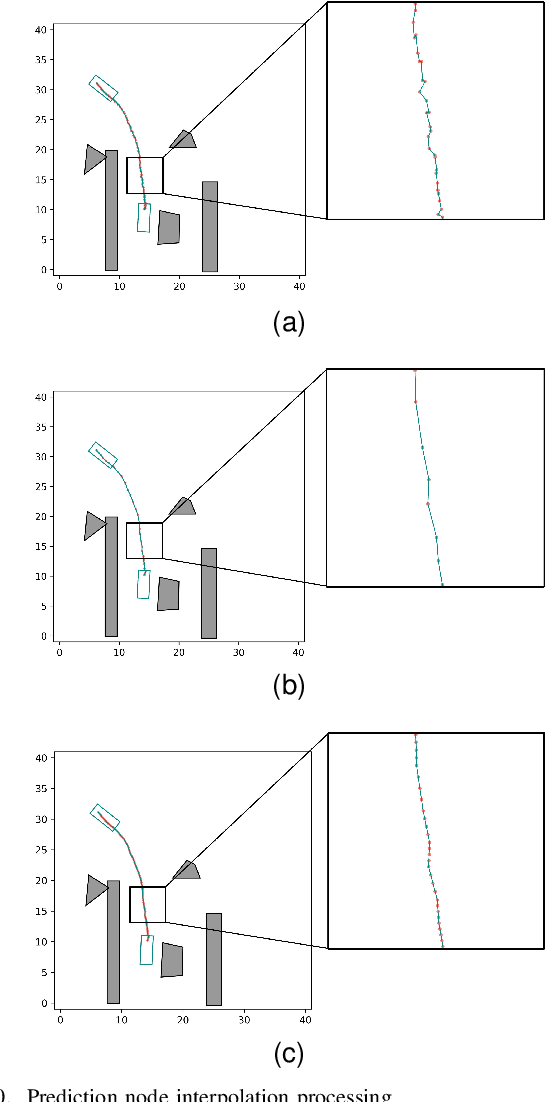
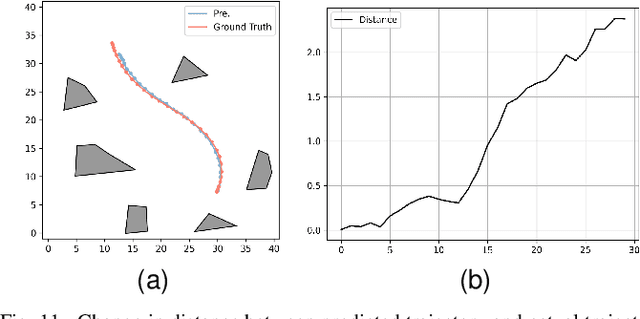
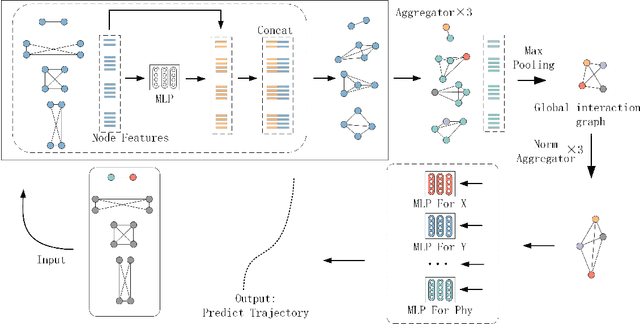
In unstructured environments, obstacles are diverse and lack lane markings, making trajectory planning for intelligent vehicles a challenging task. Traditional trajectory planning methods typically involve multiple stages, including path planning, speed planning, and trajectory optimization. These methods require the manual design of numerous parameters for each stage, resulting in significant workload and computational burden. While end-to-end trajectory planning methods are simple and efficient, they often fail to ensure that the trajectory meets vehicle dynamics and obstacle avoidance constraints in unstructured scenarios. Therefore, this paper proposes a novel trajectory planning method based on Graph Neural Networks (GNN) and numerical optimization. The proposed method consists of two stages: (1) initial trajectory prediction using the GNN, (2) trajectory optimization using numerical optimization. First, the graph neural network processes the environment information and predicts a rough trajectory, replacing traditional path and speed planning. This predicted trajectory serves as the initial solution for the numerical optimization stage, which optimizes the trajectory to ensure compliance with vehicle dynamics and obstacle avoidance constraints. We conducted simulation experiments to validate the feasibility of the proposed algorithm and compared it with other mainstream planning algorithms. The results demonstrate that the proposed method simplifies the trajectory planning process and significantly improves planning efficiency.
A Survey on Evaluation of Large Language Models
Jul 18, 2023



Large language models (LLMs) are gaining increasing popularity in both academia and industry, owing to their unprecedented performance in various applications. As LLMs continue to play a vital role in both research and daily use, their evaluation becomes increasingly critical, not only at the task level, but also at the society level for better understanding of their potential risks. Over the past years, significant efforts have been made to examine LLMs from various perspectives. This paper presents a comprehensive review of these evaluation methods for LLMs, focusing on three key dimensions: what to evaluate, where to evaluate, and how to evaluate. Firstly, we provide an overview from the perspective of evaluation tasks, encompassing general natural language processing tasks, reasoning, medical usage, ethics, educations, natural and social sciences, agent applications, and other areas. Secondly, we answer the `where' and `how' questions by diving into the evaluation methods and benchmarks, which serve as crucial components in assessing performance of LLMs. Then, we summarize the success and failure cases of LLMs in different tasks. Finally, we shed light on several future challenges that lie ahead in LLMs evaluation. Our aim is to offer invaluable insights to researchers in the realm of LLMs evaluation, thereby aiding the development of more proficient LLMs. Our key point is that evaluation should be treated as an essential discipline to better assist the development of LLMs. We consistently maintain the related open-source materials at: https://github.com/MLGroupJLU/LLM-eval-survey.