 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMA: Adaptive Memory via Multi-Agent Collaboration
Jan 28, 2026The rapid evolution of Large Language Model (LLM) agents has necessitated robust memory systems to support cohesive long-term interaction and complex reasoning. Benefiting from the strong capabilities of LLMs, recent research focus has shifted from simple context extension to the development of dedicated agentic memory systems. However, existing approaches typically rely on rigid retrieval granularity, accumulation-heavy maintenance strategies, and coarse-grained update mechanisms. These design choices create a persistent mismatch between stored information and task-specific reasoning demands, while leading to the unchecked accumulation of logical inconsistencies over time. To address these challenges, we propose Adaptive Memory via Multi-Agent Collaboration (AMA), a novel framework that leverages coordinated agents to manage memory across multiple granularities. AMA employs a hierarchical memory design that dynamically aligns retrieval granularity with task complexity. Specifically, the Constructor and Retriever jointly enable multi-granularity memory construction and adaptive query routing. The Judge verifies the relevance and consistency of retrieved content, triggering iterative retrieval when evidence is insufficient or invoking the Refresher upon detecting logical conflicts. The Refresher then enforces memory consistency by performing targeted updates or removing outdated entries. Extensive experiments on challenging long-context benchmarks show that AMA significantly outperforms state-of-the-art baselines while reducing token consumption by approximately 80% compared to full-context methods, demonstrating its effectiveness in maintaining retrieval precision and long-term memory consistency.
Jailbreaking Attacks vs. Content Safety Filters: How Far Are We in the LLM Safety Arms Race?
Dec 30, 2025As large language models (LLMs) are increasingly deployed, ensuring their safe use is paramount. Jailbreaking, adversarial prompts that bypass model alignment to trigger harmful outputs, present significant risks, with existing studies reporting high success rates in evading common LLMs. However, previous evaluations have focused solely on the models, neglecting the full deployment pipeline, which typically incorporates additional safety mechanisms like content moderation filters. To address this gap, we present the first systematic evaluation of jailbreak attacks targeting LLM safety alignment, assessing their success across the full inference pipeline, including both input and output filtering stages. Our findings yield two key insights: first, nearly all evaluated jailbreak techniques can be detected by at least one safety filter, suggesting that prior assessments may have overestimated the practical success of these attacks; second, while safety filters are effective in detection, there remains room to better balance recall and precision to further optimize protection and user experience. We highlight critical gaps and call for further refinement of detection accuracy and usability in LLM safety systems.
See-Control: A Multimodal Agent Framework for Smartphone Interaction with a Robotic Arm
Dec 09, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enabled their use as intelligent agents for smartphone operation. However, existing methods depend on the Android Debug Bridge (ADB) for data transmission and action execution, limiting their applicability to Android devices. In this work, we introduce the novel Embodied Smartphone Operation (ESO) task and present See-Control, a framework that enables smartphone operation via direct physical interaction with a low-DoF robotic arm, offering a platform-agnostic solution. See-Control comprises three key components: (1) an ESO benchmark with 155 tasks and corresponding evaluation metrics; (2) an MLLM-based embodied agent that generates robotic control commands without requiring ADB or system back-end access; and (3) a richly annotated dataset of operation episodes, offering valuable resources for future research. By bridging the gap between digital agents and the physical world, See-Control provides a concrete step toward enabling home robots to perform smartphone-dependent tasks in realistic environments.
Causal Sufficiency and Necessity Improves Chain-of-Thought Reasoning
Jun 11, 2025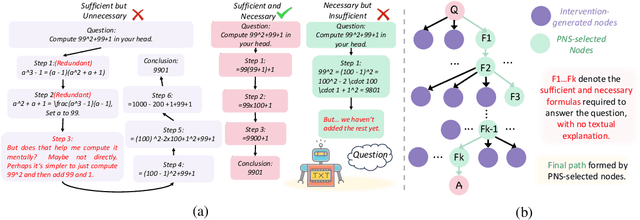
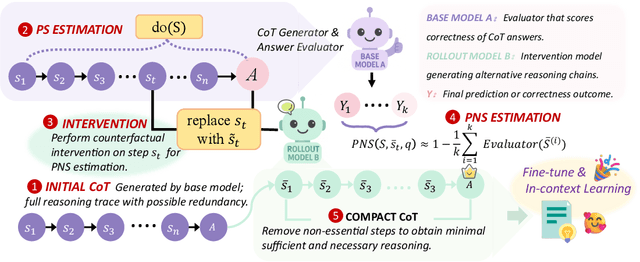
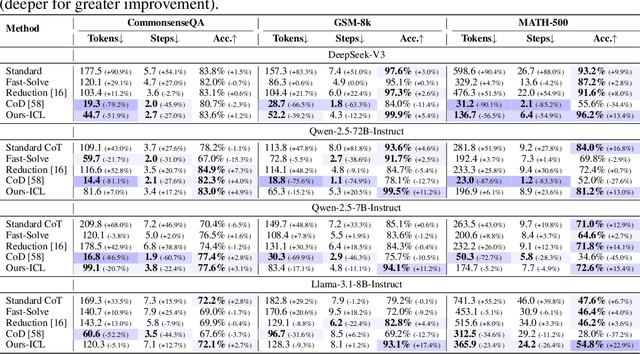
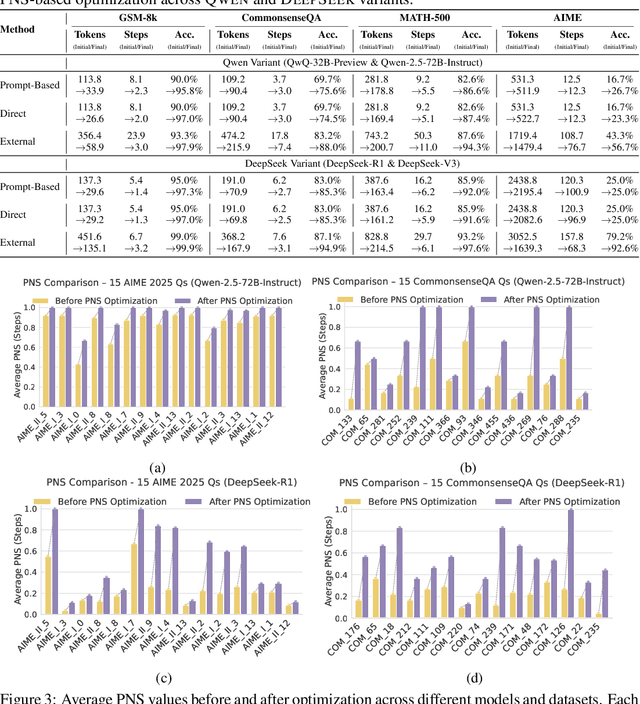
Chain-of-Thought (CoT) prompting plays an indispensable role in endowing large language models (LLMs) with complex reasoning capabilities. However, CoT currently faces two fundamental challenges: (1) Sufficiency, which ensures that the generated intermediate inference steps comprehensively cover and substantiate the final conclusion; and (2) Necessity, which identifies the inference steps that are truly indispensable for the soundness of the resulting answer. We propose a causal framework that characterizes CoT reasoning through the dual lenses of sufficiency and necessity. Incorporating causal Probability of Sufficiency and Necessity allows us not only to determine which steps are logically sufficient or necessary to the prediction outcome, but also to quantify their actual influence on the final reasoning outcome under different intervention scenarios, thereby enabling the automated addition of missing steps and the pruning of redundant ones. Extensive experimental results on various mathematical and commonsense reasoning benchmarks confirm substantial improvements in reasoning efficiency and reduced token usage without sacrificing accuracy. Our work provides a promising direction for improving LLM reasoning performance and cost-effectiveness.
ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning
Mar 12, 2025Recent research on Reasoning of Large Language Models (LLMs) has sought to further enhance their performance by integrating meta-thinking -- enabling models to monitor, evaluate, and control their reasoning processes for more adaptive and effective problem-solving. However, current single-agent work lacks a specialized design for acquiring meta-thinking, resulting in low efficacy. To address this challenge, we introduce Reinforced Meta-thinking Agents (ReMA), a novel framework that leverages Multi-Agent Reinforcement Learning (MARL) to elicit meta-thinking behaviors, encouraging LLMs to think about thinking. ReMA decouples the reasoning process into two hierarchical agents: a high-level meta-thinking agent responsible for generating strategic oversight and plans, and a low-level reasoning agent for detailed executions. Through iterative reinforcement learning with aligned objectives, these agents explore and learn collaboration, leading to improved generalization and robustness. Experimental results demonstrate that ReMA outperforms single-agent RL baselines on complex reasoning tasks, including competitive-level mathematical benchmarks and LLM-as-a-Judge benchmarks. Comprehensive ablation studies further illustrate the evolving dynamics of each distinct agent, providing valuable insights into how the meta-thinking reasoning process enhances the reasoning capabilities of LLMs.
DeepReview: Improving LLM-based Paper Review with Human-like Deep Thinking Process
Mar 11, 2025Large Language Models (LLMs) are increasingly utilized in scientific research assessment, particularly in automated paper review. However, existing LLM-based review systems face significant challenges, including limited domain expertise, hallucinated reasoning, and a lack of structured evaluation. To address these limitations, we introduce DeepReview, a multi-stage framework designed to emulate expert reviewers by incorporating structured analysis, literature retrieval, and evidence-based argumentation. Using DeepReview-13K, a curated dataset with structured annotations, we train DeepReviewer-14B, which outperforms CycleReviewer-70B with fewer tokens. In its best mode, DeepReviewer-14B achieves win rates of 88.21\% and 80.20\% against GPT-o1 and DeepSeek-R1 in evaluations. Our work sets a new benchmark for LLM-based paper review, with all resources publicly available. The code, model, dataset and demo have be released in http://ai-researcher.net.
LAG: LLM agents for Leaderboard Auto Generation on Demanding
Feb 25, 2025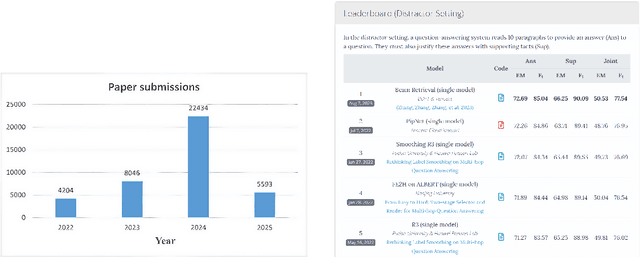
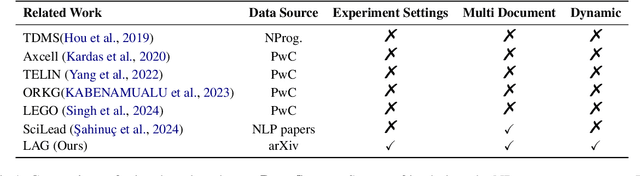
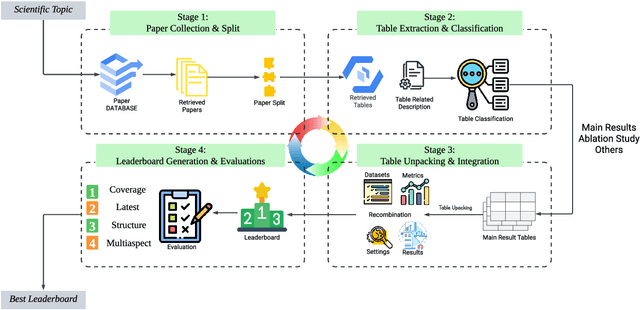

This paper introduces Leaderboard Auto Generation (LAG), a novel and well-organized framework for automatic generation of leaderboards on a given research topic in rapidly evolving fields like Artificial Intelligence (AI). Faced with a large number of AI papers updated daily, it becomes difficult for researchers to track every paper's proposed methods, experimental results, and settings, prompting the need for efficient automatic leaderboard construction. While large language models (LLMs) offer promise in automating this process, challenges such as multi-document summarization, leaderboard generation, and experiment fair comparison still remain under exploration. LAG solves these challenges through a systematic approach that involves the paper collection, experiment results extraction and integration, leaderboard generation, and quality evaluation. Our contributions include a comprehensive solution to the leaderboard construction problem, a reliable evaluation method, and experimental results showing the high quality of leaderboards.
ThinkBench: Dynamic Out-of-Distribution Evaluation for Robust LLM Reasoning
Feb 22, 2025Evaluating large language models (LLMs) poses significant challenges, particularly due to issues of data contamination and the leakage of correct answers. To address these challenges, we introduce ThinkBench, a novel evaluation framework designed to evaluate LLMs' reasoning capability robustly. ThinkBench proposes a dynamic data generation method for constructing out-of-distribution (OOD) datasets and offers an OOD dataset that contains 2,912 samples drawn from reasoning tasks. ThinkBench unifies the evaluation of reasoning models and non-reasoning models. We evaluate 16 LLMs and 4 PRMs under identical experimental conditions and show that most of the LLMs' performance are far from robust and they face a certain level of data leakage. By dynamically generating OOD datasets, ThinkBench effectively provides a reliable evaluation of LLMs and reduces the impact of data contamination.
Direct Value Optimization: Improving Chain-of-Thought Reasoning in LLMs with Refined Values
Feb 19, 2025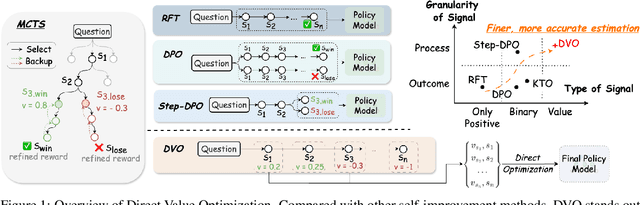
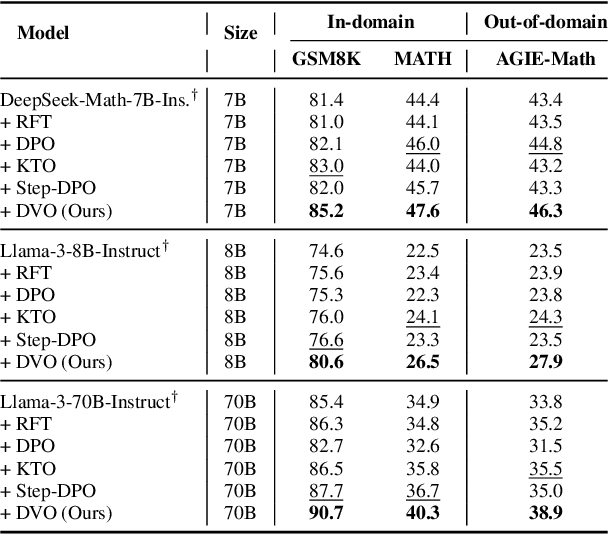
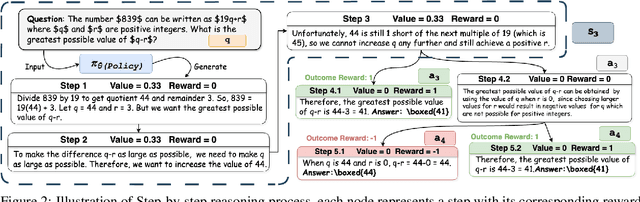
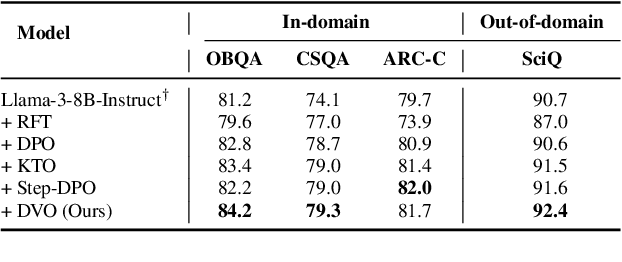
We introduce Direct Value Optimization (DVO), an innovative reinforcement learning framework for enhancing large language models in complex reasoning tasks. Unlike traditional methods relying on preference labels, DVO utilizes value signals at individual reasoning steps, optimizing models via a mean squared error loss. The key benefit of DVO lies in its fine-grained supervision, circumventing the need for labor-intensive human annotations. Target values within the DVO are estimated using either Monte Carlo Tree Search or an outcome value model. Our empirical analysis on both mathematical and commonsense reasoning tasks shows that DVO consistently outperforms existing offline preference optimization techniques, even with fewer training steps. These findings underscore the importance of value signals in advancing reasoning capabilities and highlight DVO as a superior methodology under scenarios lacking explicit human preference information.
Direct Preference Optimization Using Sparse Feature-Level Constraints
Nov 12, 2024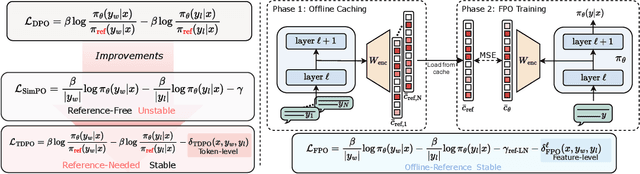


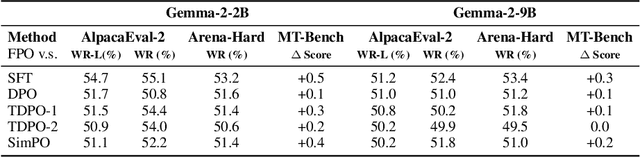
The alignment of large language models (LLMs) with human preferences remains a key challenge. While post-training techniques like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) have achieved notable success, they often introduce computational inefficiencies and training instability. In this paper, we propose Feature-level constrained Preference Optimization (FPO), a novel method designed to simplify the alignment process while ensuring stability. FPO leverages pre-trained Sparse Autoencoders (SAEs) and introduces feature-level constraints, allowing for efficient, sparsity-enforced alignment. Our approach enjoys efficiency by using sparse features activated in a well-trained sparse autoencoder and the quality of sequential KL divergence by using the feature-level offline reference. Experimental results on benchmark datasets demonstrate that FPO achieves a 5.08% absolute improvement in win rate with much lower computational cost compared to state-of-the-art baselines, making it a promising solution for efficient and controllable LLM alignments.