 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAP: Data Contamination Detection via Consistency Amplification
Paper and Code
Oct 19, 2024

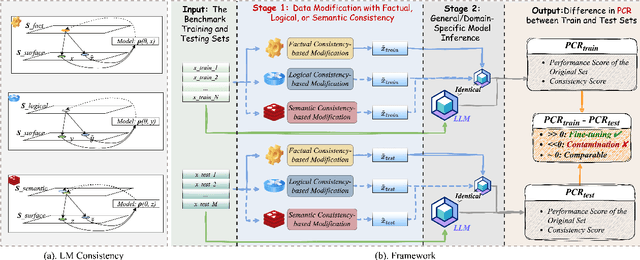

Large language models (LLMs) are widely used, but concerns about data contamination challenge the reliability of LLM evaluations. Existing contamination detection methods are often task-specific or require extra prerequisites, limiting practicality. We propose a novel framework, Consistency Amplification-based Data Contamination Detection (CAP), which introduces the Performance Consistency Ratio (PCR) to measure dataset leakage by leveraging LM consistency. To the best of our knowledge, this is the first method to explicitly differentiate between fine-tuning and contamination, which is crucial for detecting contamination in domain-specific models. Additionally, CAP is applicable to various benchmarks and works for both white-box and black-box models. We validate CAP's effectiveness through experiments on seven LLMs and four domain-specific benchmarks. Our findings also show that composite benchmarks from various dataset sources are particularly prone to unintentional contamination. Codes will be publicly available soon.