 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeaPA: Difficulty-Aware Heap Sampling and On-Policy Query Augmentation for LLM Reinforcement Learning
Jan 30, 2026RLVR is now a standard way to train LLMs on reasoning tasks with verifiable outcomes, but when rollout generation dominates the cost, efficiency depends heavily on which prompts you sample and when. In practice, prompt pools are often static or only loosely tied to the model's learning progress, so uniform sampling can't keep up with the shifting capability frontier and ends up wasting rollouts on prompts that are already solved or still out of reach. Existing approaches improve efficiency through filtering, curricula, adaptive rollout allocation, or teacher guidance, but they typically assume a fixed pool-which makes it hard to support stable on-policy pool growth-or they add extra teacher cost and latency. We introduce HeaPA (Heap Sampling and On-Policy Query Augmentation), which maintains a bounded, evolving pool, tracks the frontier using heap-based boundary sampling, expands the pool via on-policy augmentation with lightweight asynchronous validation, and stabilizes correlated queries through topology-aware re-estimation of pool statistics and controlled reinsertion. Across two training corpora, two training recipes, and seven benchmarks, HeaPA consistently improves accuracy and reaches target performance with fewer computations while keeping wall-clock time comparable. Our analyses suggest these gains come from frontier-focused sampling and on-policy pool growth, with the benefits becoming larger as model scale increases. Our code is available at https://github.com/horizon-rl/HeaPA.
Vision-DeepResearch: Incentivizing DeepResearch Capability in Multimodal Large Language Models
Jan 29, 2026Multimodal large language models (MLLMs) have achieved remarkable success across a broad range of vision tasks. However, constrained by the capacity of their internal world knowledge, prior work has proposed augmenting MLLMs by ``reasoning-then-tool-call'' for visual and textual search engines to obtain substantial gains on tasks requiring extensive factual information. However, these approaches typically define multimodal search in a naive setting, assuming that a single full-level or entity-level image query and few text query suffices to retrieve the key evidence needed to answer the question, which is unrealistic in real-world scenarios with substantial visual noise. Moreover, they are often limited in the reasoning depth and search breadth, making it difficult to solve complex questions that require aggregating evidence from diverse visual and textual sources. Building on this, we propose Vision-DeepResearch, which proposes one new multimodal deep-research paradigm, i.e., performs multi-turn, multi-entity and multi-scale visual and textual search to robustly hit real-world search engines under heavy noise. Our Vision-DeepResearch supports dozens of reasoning steps and hundreds of engine interactions, while internalizing deep-research capabilities into the MLLM via cold-start supervision and RL training, resulting in a strong end-to-end multimodal deep-research MLLM. It substantially outperforming existing multimodal deep-research MLLMs, and workflows built on strong closed-source foundation model such as GPT-5, Gemini-2.5-pro and Claude-4-Sonnet. The code will be released in https://github.com/Osilly/Vision-DeepResearch.
Finding RELIEF: Shaping Reasoning Behavior without Reasoning Supervision via Belief Engineering
Jan 20, 2026Large reasoning models (LRMs) have achieved remarkable success in complex problem-solving, yet they often suffer from computational redundancy or reasoning unfaithfulness. Current methods for shaping LRM behavior typically rely on reinforcement learning or fine-tuning with gold-standard reasoning traces, a paradigm that is both computationally expensive and difficult to scale. In this paper, we reveal that LRMs possess latent \textit{reasoning beliefs} that internally track their own reasoning traits, which can be captured through simple logit probing. Building upon this insight, we propose Reasoning Belief Engineering (RELIEF), a simple yet effective framework that shapes LRM behavior by aligning the model's self-concept with a target belief blueprint. Crucially, RELIEF completely bypasses the need for reasoning-trace supervision. It internalizes desired traits by fine-tuning on synthesized, self-reflective question-answering pairs that affirm the target belief. Extensive experiments on efficiency and faithfulness tasks demonstrate that RELIEF matches or outperforms behavior-supervised and preference-based baselines while requiring lower training costs. Further analysis validates that shifting a model's reasoning belief effectively shapes its actual behavior.
Evaluating Parameter Efficient Methods for RLVR
Dec 30, 2025We systematically evaluate Parameter-Efficient Fine-Tuning (PEFT) methods under the paradigm of Reinforcement Learning with Verifiable Rewards (RLVR). RLVR incentivizes language models to enhance their reasoning capabilities through verifiable feedback; however, while methods like LoRA are commonly used, the optimal PEFT architecture for RLVR remains unidentified. In this work, we conduct the first comprehensive evaluation of over 12 PEFT methodologies across the DeepSeek-R1-Distill families on mathematical reasoning benchmarks. Our empirical results challenge the default adoption of standard LoRA with three main findings. First, we demonstrate that structural variants, such as DoRA, AdaLoRA, and MiSS, consistently outperform LoRA. Second, we uncover a spectral collapse phenomenon in SVD-informed initialization strategies (\textit{e.g.,} PiSSA, MiLoRA), attributing their failure to a fundamental misalignment between principal-component updates and RL optimization. Furthermore, our ablations reveal that extreme parameter reduction (\textit{e.g.,} VeRA, Rank-1) severely bottlenecks reasoning capacity. We further conduct ablation studies and scaling experiments to validate our findings. This work provides a definitive guide for advocating for more exploration for parameter-efficient RL methods.
Interleaving Reasoning for Better Text-to-Image Generation
Sep 09, 2025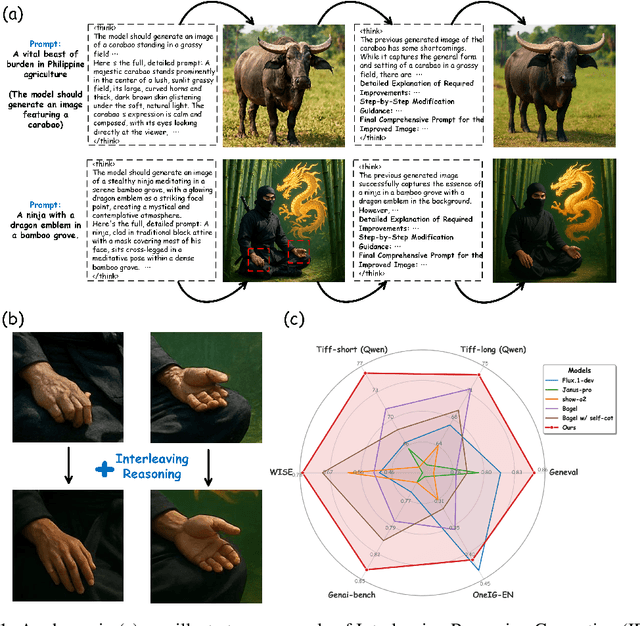
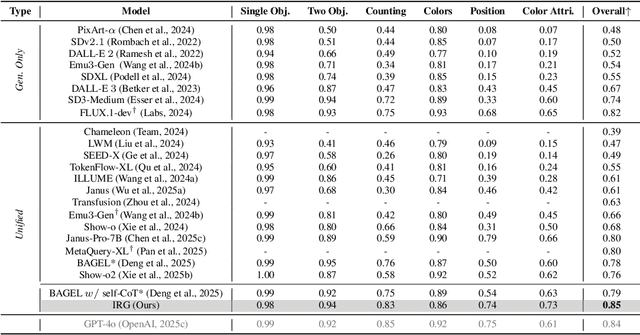

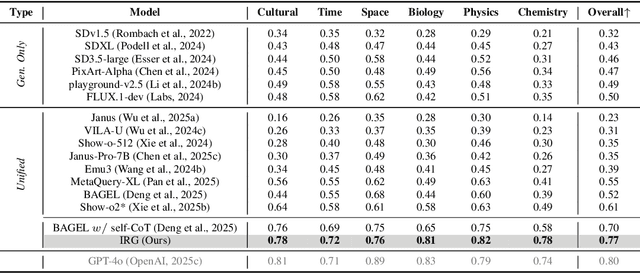
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
Jul 27, 2025Session history is a common way of recording user interacting behaviors throughout a browsing activity with multiple products. For example, if an user clicks a product webpage and then leaves, it might because there are certain features that don't satisfy the user, which serve as an important indicator of on-the-spot user preferences. However, all prior works fail to capture and model customer intention effectively because insufficient information exploitation and only apparent information like descriptions and titles are used. There is also a lack of data and corresponding benchmark for explicitly modeling intention in E-commerce product purchase sessions. To address these issues, we introduce the concept of an intention tree and propose a dataset curation pipeline. Together, we construct a sibling multimodal benchmark, SessionIntentBench, that evaluates L(V)LMs' capability on understanding inter-session intention shift with four subtasks. With 1,952,177 intention entries, 1,132,145 session intention trajectories, and 13,003,664 available tasks mined using 10,905 sessions, we provide a scalable way to exploit the existing session data for customer intention understanding. We conduct human annotations to collect ground-truth label for a subset of collected data to form an evaluation gold set. Extensive experiments on the annotated data further confirm that current L(V)LMs fail to capture and utilize the intention across the complex session setting. Further analysis show injecting intention enhances LLMs' performances.
Longer Context, Deeper Thinking: Uncovering the Role of Long-Context Ability in Reasoning
May 22, 2025Recent language models exhibit strong reasoning capabilities, yet the influence of long-context capacity on reasoning remains underexplored. In this work, we hypothesize that current limitations in reasoning stem, in part, from insufficient long-context capacity, motivated by empirical observations such as (1) higher context window length often leads to stronger reasoning performance, and (2) failed reasoning cases resemble failed long-context cases. To test this hypothesis, we examine whether enhancing a model's long-context ability before Supervised Fine-Tuning (SFT) leads to improved reasoning performance. Specifically, we compared models with identical architectures and fine-tuning data but varying levels of long-context capacity. Our results reveal a consistent trend: models with stronger long-context capacity achieve significantly higher accuracy on reasoning benchmarks after SFT. Notably, these gains persist even on tasks with short input lengths, indicating that long-context training offers generalizable benefits for reasoning performance. These findings suggest that long-context modeling is not just essential for processing lengthy inputs, but also serves as a critical foundation for reasoning. We advocate for treating long-context capacity as a first-class objective in the design of future language models.
ModRWKV: Transformer Multimodality in Linear Time
May 20, 2025Currently, most multimodal studies are based on large language models (LLMs) with quadratic-complexity Transformer architectures. While linear models like RNNs enjoy low inference costs, their application has been largely limited to the text-only modality. This work explores the capabilities of modern RNN architectures in multimodal contexts. We propose ModRWKV-a decoupled multimodal framework built upon the RWKV7 architecture as its LLM backbone-which achieves multi-source information fusion through dynamically adaptable heterogeneous modality encoders. We designed the multimodal modules in ModRWKV with an extremely lightweight architecture and, through extensive experiments, identified a configuration that achieves an optimal balance between performance and computational efficiency. ModRWKV leverages the pretrained weights of the RWKV7 LLM for initialization, which significantly accelerates multimodal training. Comparative experiments with different pretrained checkpoints further demonstrate that such initialization plays a crucial role in enhancing the model's ability to understand multimodal signals. Supported by extensive experiments, we conclude that modern RNN architectures present a viable alternative to Transformers in the domain of multimodal large language models (MLLMs). Furthermore, we identify the optimal configuration of the ModRWKV architecture through systematic exploration.
MagicInfinite: Generating Infinite Talking Videos with Your Words and Voice
Mar 07, 2025We present MagicInfinite, a novel diffusion Transformer (DiT) framework that overcomes traditional portrait animation limitations, delivering high-fidelity results across diverse character types-realistic humans, full-body figures, and stylized anime characters. It supports varied facial poses, including back-facing views, and animates single or multiple characters with input masks for precise speaker designation in multi-character scenes. Our approach tackles key challenges with three innovations: (1) 3D full-attention mechanisms with a sliding window denoising strategy, enabling infinite video generation with temporal coherence and visual quality across diverse character styles; (2) a two-stage curriculum learning scheme, integrating audio for lip sync, text for expressive dynamics, and reference images for identity preservation, enabling flexible multi-modal control over long sequences; and (3) region-specific masks with adaptive loss functions to balance global textual control and local audio guidance, supporting speaker-specific animations. Efficiency is enhanced via our innovative unified step and cfg distillation techniques, achieving a 20x inference speed boost over the basemodel: generating a 10 second 540x540p video in 10 seconds or 720x720p in 30 seconds on 8 H100 GPUs, without quality loss. Evaluations on our new benchmark demonstrate MagicInfinite's superiority in audio-lip synchronization, identity preservation, and motion naturalness across diverse scenarios. It is publicly available at https://www.hedra.com/, with examples at https://magicinfinite.github.io/.
Why Safeguarded Ships Run Aground? Aligned Large Language Models' Safety Mechanisms Tend to Be Anchored in The Template Region
Feb 19, 2025



The safety alignment of large language models (LLMs) remains vulnerable, as their initial behavior can be easily jailbroken by even relatively simple attacks. Since infilling a fixed template between the input instruction and initial model output is a common practice for existing LLMs, we hypothesize that this template is a key factor behind their vulnerabilities: LLMs' safety-related decision-making overly relies on the aggregated information from the template region, which largely influences these models' safety behavior. We refer to this issue as template-anchored safety alignment. In this paper, we conduct extensive experiments and verify that template-anchored safety alignment is widespread across various aligned LLMs. Our mechanistic analyses demonstrate how it leads to models' susceptibility when encountering inference-time jailbreak attacks. Furthermore, we show that detaching safety mechanisms from the template region is promising in mitigating vulnerabilities to jailbreak attacks. We encourage future research to develop more robust safety alignment techniques that reduce reliance on the template region.