 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable and Verifiable Tool-Use Data Synthesis for Agentic Reinforcement Learning
Apr 10, 2026Existing synthetic tool-use corpora are primarily designed for offline supervised fine-tuning, yet reinforcement learning (RL) requires executable environments that support reward-checkable online rollouts. We propose COVERT, a two-stage pipeline that first generates reliable base tool-use trajectories through self-evolving synthesis with multi-level validation, and then applies oracle-preserving augmentations that systematically increase environmental complexity. These augmentations introduce distractor tools, indirect or ambiguous user queries, and noisy, multi-format, or erroneous tool outputs, while strictly preserving oracle tool calls and final answers as ground truth. This design enables automatic reward computation via reference matching for standard cases and lightweight judge-assisted verification for special behaviors such as error detection, supporting RL optimization of tool-calling policies. On Qwen2.5-Instruct-14B, COVERT-RL improves overall accuracy on BFCL v3 from 56.5 to 59.9 and on ACEBench from 53.0 to 59.3, with minimal regressions on general-ability benchmarks; when stacked on SFT, it further reaches 62.1 and 61.8, confirming additive gains. These results suggest that oracle-preserving synthetic environments offer a practical RL refinement stage, complementary to SFT, for improving tool-use robustness under ambiguity and unreliable tool feedback.
GSR-GNN: Training Acceleration and Memory-Saving Framework of Deep GNNs on Circuit Graph
Mar 28, 2026Graph Neural Networks (GNNs) show strong promise for circuit analysis, but scaling to modern large-scale circuit graphs is limited by GPU memory and training cost, especially for deep models. We revisit deep GNNs for circuit graphs and show that, when trainable, they significantly outperform shallow architectures, motivating an efficient, domain-specific training framework. We propose Grouped-Sparse-Reversible GNN (GSR-GNN), which enables training GNNs with up to hundreds of layers while reducing both compute and memory overhead. GSR-GNN integrates reversible residual modules with a group-wise sparse nonlinear operator that compresses node embeddings without sacrificing task-relevant information, and employs an optimized execution pipeline to eliminate fragmented activation storage and reduce data movement. On sampled circuit graphs, GSR-GNN achieves up to 87.2\% peak memory reduction and over 30$\times$ training speedup with negligible degradation in correlation-based quality metrics, making deep GNNs practical for large-scale EDA workloads.
Training LLMs for Multi-Step Tool Orchestration with Constrained Data Synthesis and Graduated Rewards
Mar 25, 2026Multi-step tool orchestration, where LLMs must invoke multiple dependent APIs in the correct order while propagating intermediate outputs, remains challenging. State-of-the-art models frequently fail on full sequence execution, with parameter value errors accounting for a significant portion of failures. Training models to handle such workflows faces two obstacles: existing environments focus on simple per-turn function calls with simulated data, and binary rewards provide no signal for partial correctness. We present a framework addressing both challenges. First, we construct a reinforcement learning environment backed by a large-scale cache of real API responses, enabling a data synthesis pipeline that samples valid multi-step orchestration traces with controllable complexity and significantly higher generation efficiency than unconstrained methods. Second, we propose a graduated reward design that decomposes correctness into atomic validity (individual function call correctness at increasing granularity) and orchestration (correct tool sequencing with dependency respect). On ComplexFuncBench, our approach demonstrates substantial improvements in turn accuracy. Ablation studies confirm both reward components are essential: using either alone significantly degrades performance.
PRISM: Streaming Human Motion Generation with Per-Joint Latent Decomposition
Mar 10, 2026Text-to-motion generation has advanced rapidly, yet two challenges persist. First, existing motion autoencoders compress each frame into a single monolithic latent vector, entangling trajectory and per-joint rotations in an unstructured representation that downstream generators struggle to model faithfully. Second, text-to-motion, pose-conditioned generation, and long-horizon sequential synthesis typically require separate models or task-specific mechanisms, with autoregressive approaches suffering from severe error accumulation over extended rollouts. We present PRISM, addressing each challenge with a dedicated contribution. (1) A joint-factorized motion latent space: each body joint occupies its own token, forming a structured 2D grid (time joints) compressed by a causal VAE with forward-kinematics supervision. This simple change to the latent space -- without modifying the generator -- substantially improves generation quality, revealing that latent space design has been an underestimated bottleneck. (2) Noise-free condition injection: each latent token carries its own timestep embedding, allowing conditioning frames to be injected as clean tokens (timestep0) while the remaining tokens are denoised. This unifies text-to-motion and pose-conditioned generation in a single model, and directly enables autoregressive segment chaining for streaming synthesis. Self-forcing training further suppresses drift in long rollouts. With these two components, we train a single motion generation foundation model that seamlessly handles text-to-motion, pose-conditioned generation, autoregressive sequential generation, and narrative motion composition, achieving state-of-the-art on HumanML3D, MotionHub, BABEL, and a 50-scenario user study.
StitchCUDA: An Automated Multi-Agents End-to-End GPU Programing Framework with Rubric-based Agentic Reinforcement Learning
Mar 03, 2026Modern machine learning (ML) workloads increasingly rely on GPUs, yet achieving high end-to-end performance remains challenging due to dependencies on both GPU kernel efficiency and host-side settings. Although LLM-based methods show promise on automated GPU kernel generation, prior works mainly focus on single-kernel optimization and do not extend to end-to-end programs, hindering practical deployment. To address the challenge, in this work, we propose StitchCUDA, a multi-agent framework for end-to-end GPU program generation, with three specialized agents: a Planner to orchestrate whole system design, a Coder dedicated to implementing it step-by-step, and a Verifier for correctness check and performance profiling using Nsys/NCU. To fundamentally improve the Coder's ability in end-to-end GPU programming, StitchCUDA integrates rubric-based agentic reinforcement learning over two atomic skills, task-to-code generation and feedback-driven code optimization, with combined rubric reward and rule-based reward from real executions. Therefore, the Coder learns how to implement advanced CUDA programming techniques (e.g., custom kernel fusion, cublas epilogue), and we also effectively prevent Coder's reward hacking (e.g., just copy PyTorch code or hardcoding output) during benchmarking. Experiments on KernelBench show that StitchCUDA achieves nearly 100% success rate on end-to-end GPU programming tasks, with 1.72x better speedup over the multi-agent baseline and 2.73x than the RL model baselines.
Denoising-Enhanced YOLO for Robust SAR Ship Detection
Feb 27, 2026With the rapid advancement of deep learning, synthetic aperture radar (SAR) imagery has become a key modality for ship detection. However, robust performance remains challenging in complex scenes, where clutter and speckle noise can induce false alarms and small targets are easily missed. To address these issues, we propose CPN-YOLO, a high-precision ship detection framework built upon YOLOv8 with three targeted improvements. First, we introduce a learnable large-kernel denoising module for input pre-processing, producing cleaner representations and more discriminative features across diverse ship types. Second, we design a feature extraction enhancement strategy based on the PPA attention mechanism to strengthen multi-scale modeling and improve sensitivity to small ships. Third, we incorporate a Gaussian similarity loss derived from the normalized Wasserstein distance (NWD) to better measure similarity under complex bounding-box distributions and improve generalization. Extensive experiments on HRSID and SSDD demonstrate the effectiveness of our method. On SSDD, CPN-YOLO surpasses the YOLOv8 baseline, achieving 97.0% precision, 95.1% recall, and 98.9% mAP, and consistently outperforms other representative deep-learning detectors in overall performance.
Spec2VolCAMU-Net: A Spectrogram-to-Volume Model for EEG-to-fMRI Reconstruction based on Multi-directional Time-Frequency Convolutional Attention Encoder and Vision-Mamba U-Net
May 14, 2025High-resolution functional magnetic resonance imaging (fMRI) is essential for mapping human brain activity; however, it remains costly and logistically challenging. If comparable volumes could be generated directly from widely available scalp electroencephalography (EEG), advanced neuroimaging would become significantly more accessible. Existing EEG-to-fMRI generators rely on plain CNNs that fail to capture cross-channel time-frequency cues or on heavy transformer/GAN decoders that strain memory and stability. We propose Spec2VolCAMU-Net, a lightweight spectrogram-to-volume generator that confronts these issues via a Multi-directional Time-Frequency Convolutional Attention Encoder, stacking temporal, spectral and joint convolutions with self-attention, and a Vision-Mamba U-Net decoder whose linear-time state-space blocks enable efficient long-range spatial modelling. Trained end-to-end with a hybrid SSI-MSE loss, Spec2VolCAMU-Net achieves state-of-the-art fidelity on three public benchmarks, recording SSIMs of 0.693 on NODDI, 0.725 on Oddball and 0.788 on CN-EPFL, representing improvements of 14.5%, 14.9%, and 16.9% respectively over previous best SSIM scores. Furthermore, it achieves competitive PSNR scores, particularly excelling on the CN-EPFL dataset with a 4.6% improvement over the previous best PSNR, thus striking a better balance in reconstruction quality. The proposed model is lightweight and efficient, making it suitable for real-time applications in clinical and research settings. The code is available at https://github.com/hdy6438/Spec2VolCAMU-Net.
IHEval: Evaluating Language Models on Following the Instruction Hierarchy
Feb 12, 2025The instruction hierarchy, which establishes a priority order from system messages to user messages, conversation history, and tool outputs, is essential for ensuring consistent and safe behavior in language models (LMs). Despite its importance, this topic receives limited attention, and there is a lack of comprehensive benchmarks for evaluating models' ability to follow the instruction hierarchy. We bridge this gap by introducing IHEval, a novel benchmark comprising 3,538 examples across nine tasks, covering cases where instructions in different priorities either align or conflict. Our evaluation of popular LMs highlights their struggle to recognize instruction priorities. All evaluated models experience a sharp performance decline when facing conflicting instructions, compared to their original instruction-following performance. Moreover, the most competitive open-source model only achieves 48% accuracy in resolving such conflicts. Our results underscore the need for targeted optimization in the future development of LMs.
MotionLLaMA: A Unified Framework for Motion Synthesis and Comprehension
Nov 26, 2024
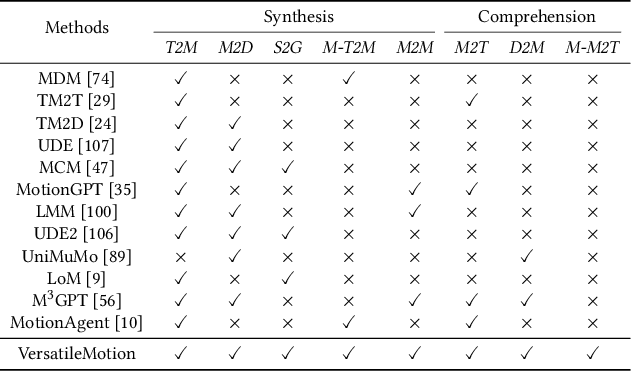
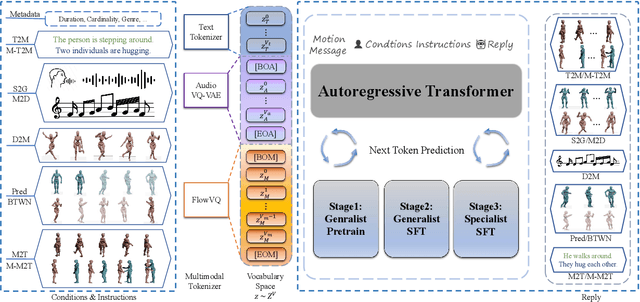
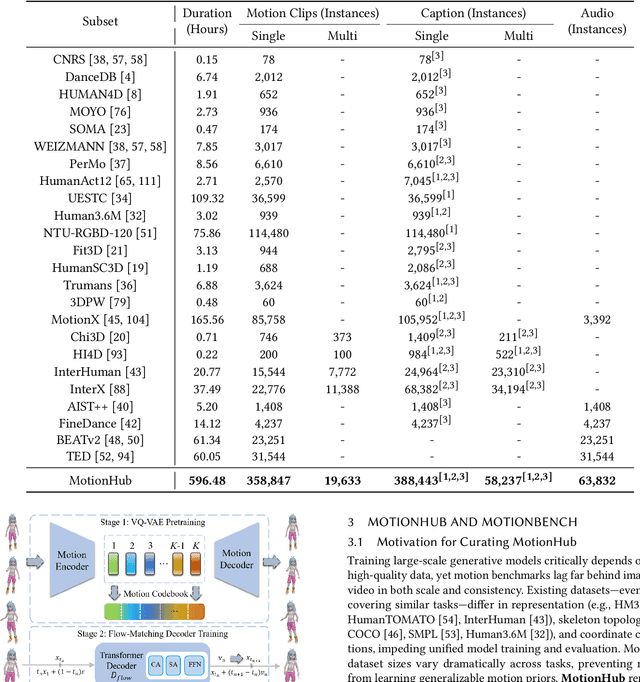
This paper introduces MotionLLaMA, a unified framework for motion synthesis and comprehension, along with a novel full-body motion tokenizer called the HoMi Tokenizer. MotionLLaMA is developed based on three core principles. First, it establishes a powerful unified representation space through the HoMi Tokenizer. Using a single codebook, the HoMi Tokenizer in MotionLLaMA achieves reconstruction accuracy comparable to residual vector quantization tokenizers utilizing six codebooks, outperforming all existing single-codebook tokenizers. Second, MotionLLaMA integrates a large language model to tackle various motion-related tasks. This integration bridges various modalities, facilitating both comprehensive and intricate motion synthesis and comprehension. Third, MotionLLaMA introduces the MotionHub dataset, currently the most extensive multimodal, multitask motion dataset, which enables fine-tuning of large language models. Extensive experimental results demonstrate that MotionLLaMA not only covers the widest range of motion-related tasks but also achieves state-of-the-art (SOTA) performance in motion completion, interaction dual-person text-to-motion, and all comprehension tasks while reaching performance comparable to SOTA in the remaining tasks. The code and MotionHub dataset are publicly available.
Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
Aug 07, 2024



Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research into the reasoning capabilities of Large Language Models (LLMs), most studies have failed to rigorously differentiate between inductive and deductive reasoning, leading to a blending of the two. This raises an essential question: In LLM reasoning, which poses a greater challenge - deductive or inductive reasoning? While the deductive reasoning capabilities of LLMs, (i.e. their capacity to follow instructions in reasoning tasks), have received considerable attention, their abilities in true inductive reasoning remain largely unexplored. To investigate into the true inductive reasoning capabilities of LLMs, we propose a novel framework, SolverLearner. This framework enables LLMs to learn the underlying function (i.e., $y = f_w(x)$), that maps input data points $(x)$ to their corresponding output values $(y)$, using only in-context examples. By focusing on inductive reasoning and separating it from LLM-based deductive reasoning, we can isolate and investigate inductive reasoning of LLMs in its pure form via SolverLearner. Our observations reveal that LLMs demonstrate remarkable inductive reasoning capabilities through SolverLearner, achieving near-perfect performance with ACC of 1 in most cases. Surprisingly, despite their strong inductive reasoning abilities, LLMs tend to relatively lack deductive reasoning capabilities, particularly in tasks involving ``counterfactual'' reasoning.