 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTT-Prune: Joint Model Pruning and Resource Allocation for Communication-efficient Time-triggered Federated Learning
Nov 06, 2025Federated learning (FL) offers new opportunities in machine learning, particularly in addressing data privacy concerns. In contrast to conventional event-based federated learning, time-triggered federated learning (TT-Fed), as a general form of both asynchronous and synchronous FL, clusters users into different tiers based on fixed time intervals. However, the FL network consists of a growing number of user devices with limited wireless bandwidth, consequently magnifying issues such as stragglers and communication overhead. In this paper, we introduce adaptive model pruning to wireless TT-Fed systems and study the problem of jointly optimizing the pruning ratio and bandwidth allocation to minimize the training loss while ensuring minimal learning latency. To answer this question, we perform convergence analysis on the gradient l_2 norm of the TT-Fed model based on model pruning. Based on the obtained convergence upper bound, a joint optimization problem of pruning ratio and wireless bandwidth is formulated to minimize the model training loss under a given delay threshold. Then, we derive closed-form solutions for wireless bandwidth and pruning ratio using Karush-Kuhn-Tucker(KKT) conditions. The simulation results show that model pruning could reduce the communication cost by 40% while maintaining the model performance at the same level.
Search Wisely: Mitigating Sub-optimal Agentic Searches By Reducing Uncertainty
May 22, 2025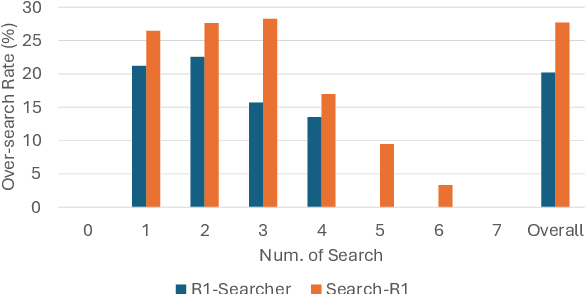
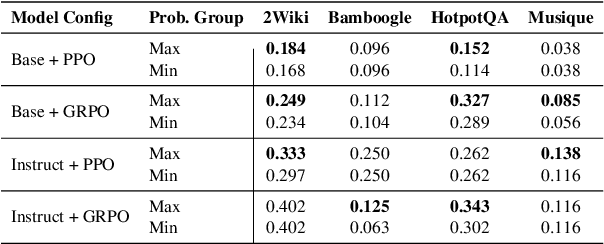
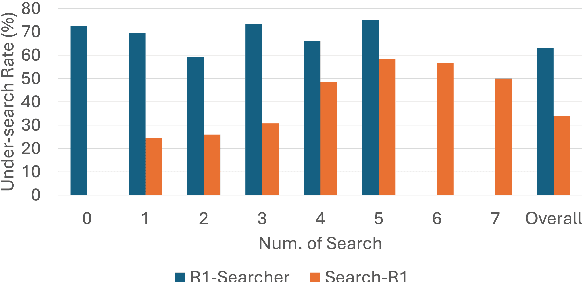
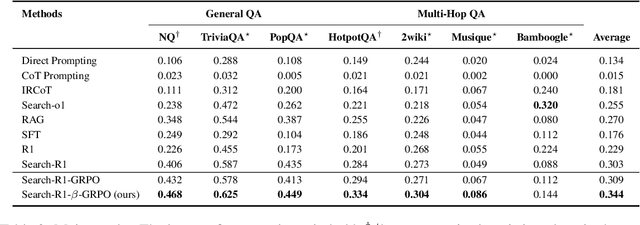
Agentic Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by enabling dynamic, multi-step reasoning and information retrieval. However, these systems often exhibit sub-optimal search behaviors like over-search (retrieving redundant information) and under-search (failing to retrieve necessary information), which hinder efficiency and reliability. This work formally defines and quantifies these behaviors, revealing their prevalence across multiple QA datasets and agentic RAG systems (e.g., one model could have avoided searching in 27.7% of its search steps). Furthermore, we demonstrate a crucial link between these inefficiencies and the models' uncertainty regarding their own knowledge boundaries, where response accuracy correlates with model's uncertainty in its search decisions. To address this, we propose $\beta$-GRPO, a reinforcement learning-based training method that incorporates confidence threshold to reward high-certainty search decisions. Experiments on seven QA benchmarks show that $\beta$-GRPO enable a 3B model with better agentic RAG ability, outperforming other strong baselines with a 4% higher average exact match score.
Do Retrieval-Augmented Language Models Adapt to Varying User Needs?
Feb 27, 2025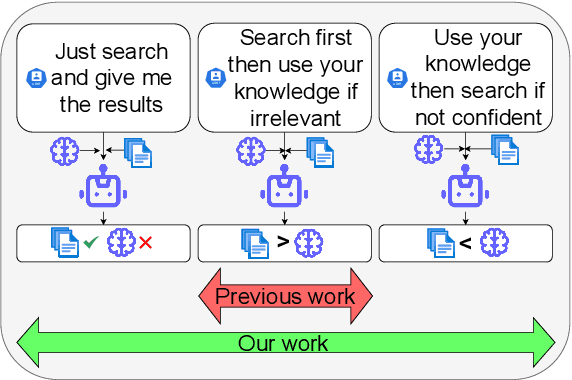


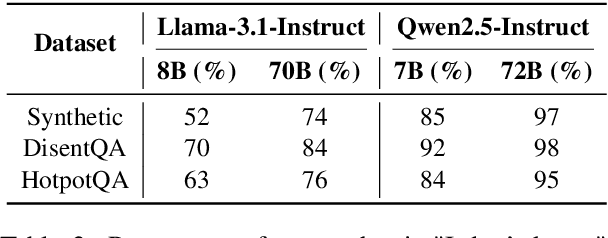
Recent advancements in Retrieval-Augmented Language Models (RALMs) have demonstrated their efficacy in knowledge-intensive tasks. However, existing evaluation benchmarks often assume a single optimal approach to leveraging retrieved information, failing to account for varying user needs. This paper introduces a novel evaluation framework that systematically assesses RALMs under three user need cases-Context-Exclusive, Context-First, and Memory-First-across three distinct context settings: Context Matching, Knowledge Conflict, and Information Irrelevant. By varying both user instructions and the nature of retrieved information, our approach captures the complexities of real-world applications where models must adapt to diverse user requirements. Through extensive experiments on multiple QA datasets, including HotpotQA, DisentQA, and our newly constructed synthetic URAQ dataset, we find that restricting memory usage improves robustness in adversarial retrieval conditions but decreases peak performance with ideal retrieval results and model family dominates behavioral differences. Our findings highlight the necessity of user-centric evaluations in the development of retrieval-augmented systems and provide insights into optimizing model performance across varied retrieval contexts. We will release our code and URAQ dataset upon acceptance of the paper.
CBT-Bench: Evaluating Large Language Models on Assisting Cognitive Behavior Therapy
Oct 17, 2024
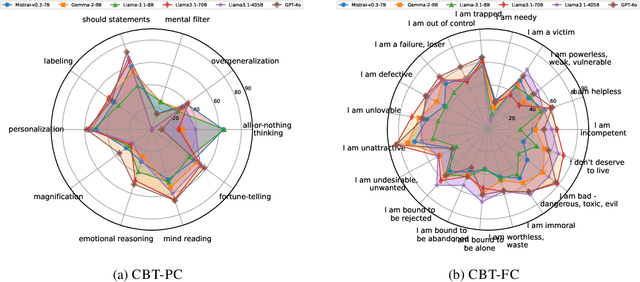

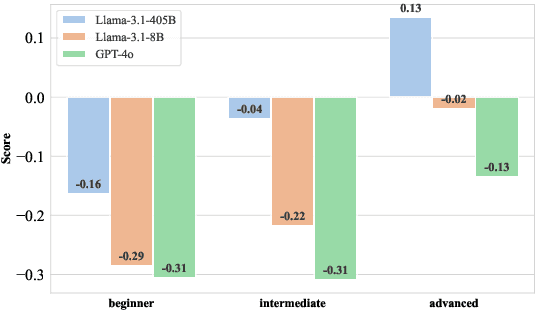
There is a significant gap between patient needs and available mental health support today. In this paper, we aim to thoroughly examine the potential of using Large Language Models (LLMs) to assist professional psychotherapy. To this end, we propose a new benchmark, CBT-BENCH, for the systematic evaluation of cognitive behavioral therapy (CBT) assistance. We include three levels of tasks in CBT-BENCH: I: Basic CBT knowledge acquisition, with the task of multiple-choice questions; II: Cognitive model understanding, with the tasks of cognitive distortion classification, primary core belief classification, and fine-grained core belief classification; III: Therapeutic response generation, with the task of generating responses to patient speech in CBT therapy sessions. These tasks encompass key aspects of CBT that could potentially be enhanced through AI assistance, while also outlining a hierarchy of capability requirements, ranging from basic knowledge recitation to engaging in real therapeutic conversations. We evaluated representative LLMs on our benchmark. Experimental results indicate that while LLMs perform well in reciting CBT knowledge, they fall short in complex real-world scenarios requiring deep analysis of patients' cognitive structures and generating effective responses, suggesting potential future work.
Joint Model Pruning and Resource Allocation for Wireless Time-triggered Federated Learning
Aug 03, 2024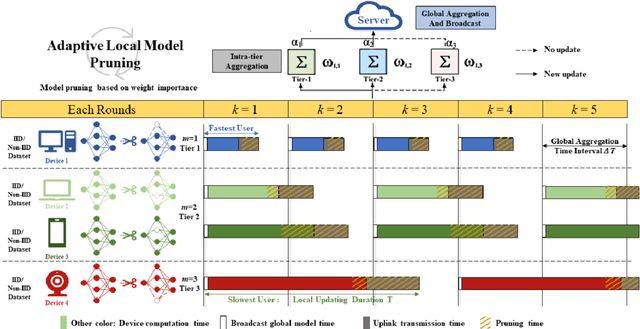
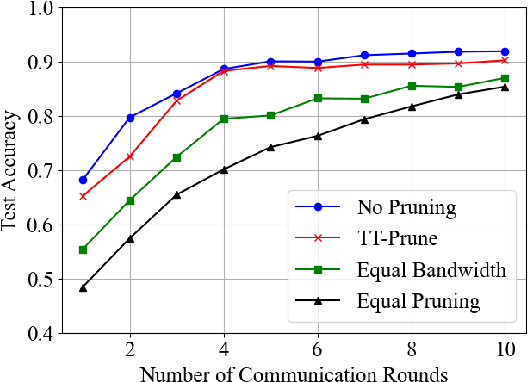
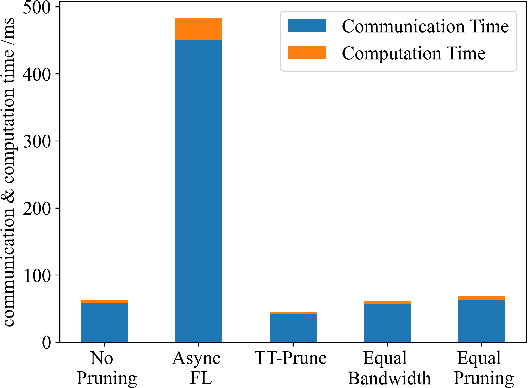
Time-triggered federated learning, in contrast to conventional event-based federated learning, organizes users into tiers based on fixed time intervals. However, this network still faces challenges due to a growing number of devices and limited wireless bandwidth, increasing issues like stragglers and communication overhead. In this paper, we apply model pruning to wireless Time-triggered systems and jointly study the problem of optimizing the pruning ratio and bandwidth allocation to minimize training loss under communication latency constraints. To solve this joint optimization problem, we perform a convergence analysis on the gradient $l_2$-norm of the asynchronous multi-tier federated learning (FL) model with adaptive model pruning. The convergence upper bound is derived and a joint optimization problem of pruning ratio and wireless bandwidth is defined to minimize the model training loss under a given communication latency constraint. The closed-form solutions for wireless bandwidth and pruning ratio by using KKT conditions are then formulated. As indicated in the simulation experiments, our proposed TT-Prune demonstrates a 40% reduction in communication cost, compared with the asynchronous multi-tier FL without model pruning, while maintaining the model convergence at the same level.
Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
May 30, 2024



Instruction Fine-Tuning (IFT) significantly enhances the zero-shot capabilities of pretrained Large Language Models (LLMs). While coding data is known to boost reasoning abilities during LLM pretraining, its role in activating internal reasoning capacities during IFT remains understudied. This paper investigates a key question: How does coding data impact LLMs' reasoning capacities during the IFT stage? To explore this, we thoroughly examine the impact of coding data across different coding data proportions, model families, sizes, and reasoning domains, from various perspectives. Specifically, we create three IFT datasets with increasing coding data proportions, fine-tune six LLM backbones across different families and scales on these datasets, evaluate the tuned models' performance across twelve tasks in three reasoning domains, and analyze the outcomes from three broad-to-granular perspectives: overall, domain-level, and task-specific. Our holistic analysis provides valuable insights in each perspective. First, coding data tuning enhances the overall reasoning capabilities of LLMs across different model families and scales. Moreover, the effect of coding data varies among different domains but shows consistent trends across model families and scales within each domain. Additionally, coding data generally yields comparable task-specific benefits across different model families, with the optimal coding data proportions in IFT datasets being task-specific.
GPT-4V as a Generalist Evaluator for Vision-Language Tasks
Nov 02, 2023Automatically evaluating vision-language tasks is challenging, especially when it comes to reflecting human judgments due to limitations in accounting for fine-grained details. Although GPT-4V has shown promising results in various multi-modal tasks, leveraging GPT-4V as a generalist evaluator for these tasks has not yet been systematically explored. We comprehensively validate GPT-4V's capabilities for evaluation purposes, addressing tasks ranging from foundational image-to-text and text-to-image synthesis to high-level image-to-image translations and multi-images to text alignment. We employ two evaluation methods, single-answer grading and pairwise comparison, using GPT-4V. Notably, GPT-4V shows promising agreement with humans across various tasks and evaluation methods, demonstrating immense potential for multi-modal LLMs as evaluators. Despite limitations like restricted visual clarity grading and real-world complex reasoning, its ability to provide human-aligned scores enriched with detailed explanations is promising for universal automatic evaluator.
AlpaCare:Instruction-tuned Large Language Models for Medical Application
Oct 23, 2023Large Language Models (LLMs) have demonstrated significant enhancements in instruction-following abilities through instruction tuning, achieving notable performances across various tasks. Previous research has focused on fine-tuning medical domain-specific LLMs using an extensive array of medical-specific data, incorporating millions of pieces of biomedical literature to augment their medical capabilities. However, existing medical instruction-tuned LLMs have been constrained by the limited scope of tasks and instructions available, restricting the efficacy of instruction tuning and adversely affecting performance in the general domain. In this paper, we fine-tune LLaMA-series models using 52k diverse, machine-generated, medical instruction-following data, MedInstruct-52k, resulting in the model AlpaCare. Comprehensive experimental results on both general and medical-specific domain free-form instruction evaluations showcase AlpaCare's strong medical proficiency and generalizability compared to previous instruction-tuned models in both medical and general domains. We provide public access to our MedInstruct-52k dataset and a clinician-crafted free-form instruction test set, MedInstruct-test, along with our codebase, to foster further research and development. Our project page is available at https://github.com/XZhang97666/AlpaCare.
Enhancing Small Medical Learners with Privacy-preserving Contextual Prompting
May 22, 2023Large language models (LLMs) demonstrate remarkable medical expertise, but data privacy concerns impede their direct use in healthcare environments. Although offering improved data privacy protection, domain-specific small language models (SLMs) often underperform LLMs, emphasizing the need for methods that reduce this performance gap while alleviating privacy concerns. In this paper, we present a simple yet effective method that harnesses LLMs' medical proficiency to boost SLM performance in medical tasks under privacy-restricted scenarios. Specifically, we mitigate patient privacy issues by extracting keywords from medical data and prompting the LLM to generate a medical knowledge-intensive context by simulating clinicians' thought processes. This context serves as additional input for SLMs, augmenting their decision-making capabilities. Our method significantly enhances performance in both few-shot and full training settings across three medical knowledge-intensive tasks, achieving up to a 22.57% increase in absolute accuracy compared to SLM fine-tuning without context, and sets new state-of-the-art results in two medical tasks within privacy-restricted scenarios. Further out-of-domain testing and experiments in two general domain datasets showcase its generalizability and broad applicability.
Exploring the Limits of ChatGPT for Query or Aspect-based Text Summarization
Feb 16, 2023Text summarization has been a crucial problem in natural language processing (NLP) for several decades. It aims to condense lengthy documents into shorter versions while retaining the most critical information. Various methods have been proposed for text summarization, including extractive and abstractive summarization. The emergence of large language models (LLMs) like GPT3 and ChatGPT has recently created significant interest in using these models for text summarization tasks. Recent studies \cite{goyal2022news, zhang2023benchmarking} have shown that LLMs-generated news summaries are already on par with humans. However, the performance of LLMs for more practical applications like aspect or query-based summaries is underexplored. To fill this gap, we conducted an evaluation of ChatGPT's performance on four widely used benchmark datasets, encompassing diverse summaries from Reddit posts, news articles, dialogue meetings, and stories. Our experiments reveal that ChatGPT's performance is comparable to traditional fine-tuning methods in terms of Rouge scores. Moreover, we highlight some unique differences between ChatGPT-generated summaries and human references, providing valuable insights into the superpower of ChatGPT for diverse text summarization tasks. Our findings call for new directions in this area, and we plan to conduct further research to systematically examine the characteristics of ChatGPT-generated summaries through extensive human evaluation.