 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Logical Instruction Generation
Aug 12, 2025Instruction following has catalyzed the recent era of Large Language Models (LLMs) and is the foundational skill underpinning more advanced capabilities such as reasoning and agentic behaviors. As tasks grow more challenging, the logic structures embedded in natural language instructions becomes increasingly intricate. However, how well LLMs perform on such logic-rich instructions remains under-explored. We propose LogicIFGen and LogicIFEval. LogicIFGen is a scalable, automated framework for generating verifiable instructions from code functions, which can naturally express rich logic such as conditionals, nesting, recursion, and function calls. We further curate a collection of complex code functions and use LogicIFGen to construct LogicIFEval, a benchmark comprising 426 verifiable logic-rich instructions. Our experiments demonstrate that current state-of-the-art LLMs still struggle to correctly follow the instructions in LogicIFEval. Most LLMs can only follow fewer than 60% of the instructions, revealing significant deficiencies in the instruction-following ability. Code and Benchmark: https://github.com/mianzhang/LogicIF
Search Wisely: Mitigating Sub-optimal Agentic Searches By Reducing Uncertainty
May 22, 2025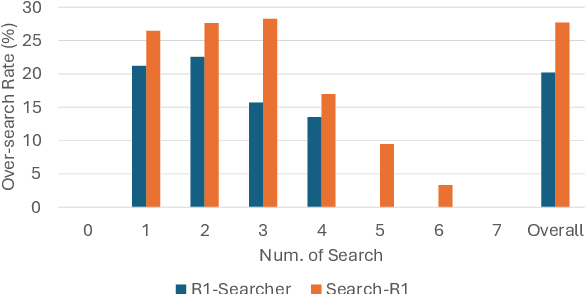
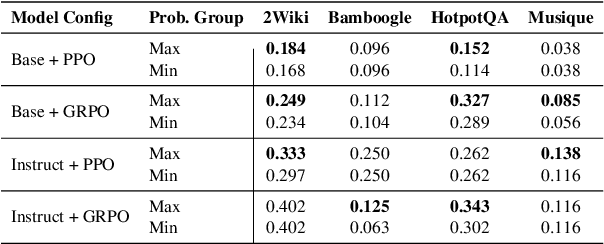
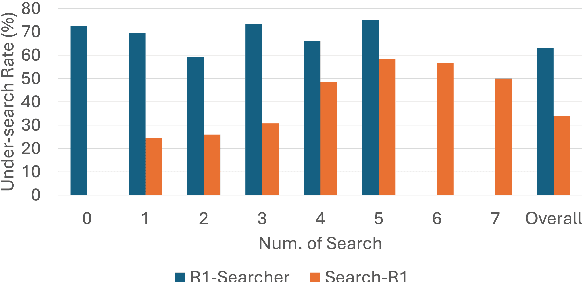
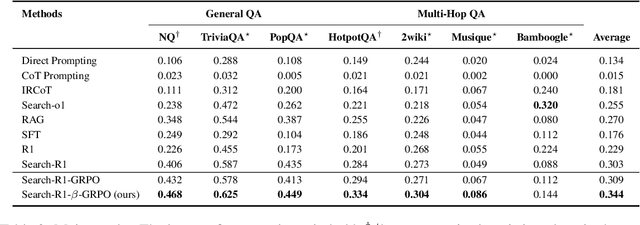
Agentic Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by enabling dynamic, multi-step reasoning and information retrieval. However, these systems often exhibit sub-optimal search behaviors like over-search (retrieving redundant information) and under-search (failing to retrieve necessary information), which hinder efficiency and reliability. This work formally defines and quantifies these behaviors, revealing their prevalence across multiple QA datasets and agentic RAG systems (e.g., one model could have avoided searching in 27.7% of its search steps). Furthermore, we demonstrate a crucial link between these inefficiencies and the models' uncertainty regarding their own knowledge boundaries, where response accuracy correlates with model's uncertainty in its search decisions. To address this, we propose $\beta$-GRPO, a reinforcement learning-based training method that incorporates confidence threshold to reward high-certainty search decisions. Experiments on seven QA benchmarks show that $\beta$-GRPO enable a 3B model with better agentic RAG ability, outperforming other strong baselines with a 4% higher average exact match score.
Do Retrieval-Augmented Language Models Adapt to Varying User Needs?
Feb 27, 2025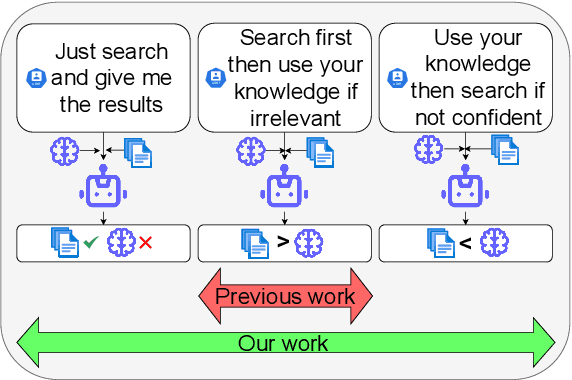


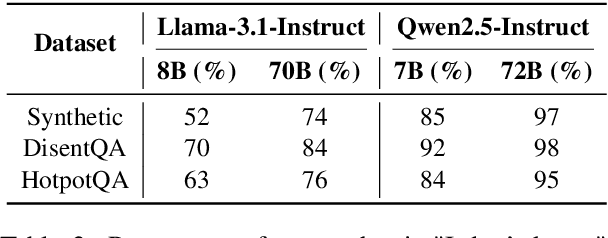
Recent advancements in Retrieval-Augmented Language Models (RALMs) have demonstrated their efficacy in knowledge-intensive tasks. However, existing evaluation benchmarks often assume a single optimal approach to leveraging retrieved information, failing to account for varying user needs. This paper introduces a novel evaluation framework that systematically assesses RALMs under three user need cases-Context-Exclusive, Context-First, and Memory-First-across three distinct context settings: Context Matching, Knowledge Conflict, and Information Irrelevant. By varying both user instructions and the nature of retrieved information, our approach captures the complexities of real-world applications where models must adapt to diverse user requirements. Through extensive experiments on multiple QA datasets, including HotpotQA, DisentQA, and our newly constructed synthetic URAQ dataset, we find that restricting memory usage improves robustness in adversarial retrieval conditions but decreases peak performance with ideal retrieval results and model family dominates behavioral differences. Our findings highlight the necessity of user-centric evaluations in the development of retrieval-augmented systems and provide insights into optimizing model performance across varied retrieval contexts. We will release our code and URAQ dataset upon acceptance of the paper.
Preference Learning Unlocks LLMs' Psycho-Counseling Skills
Feb 27, 2025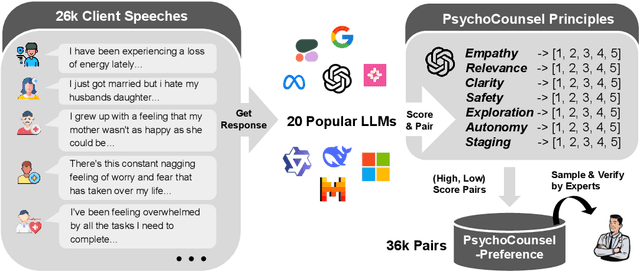
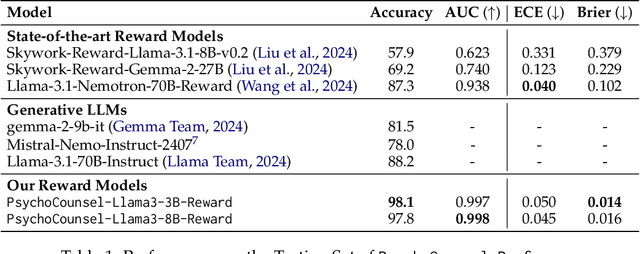
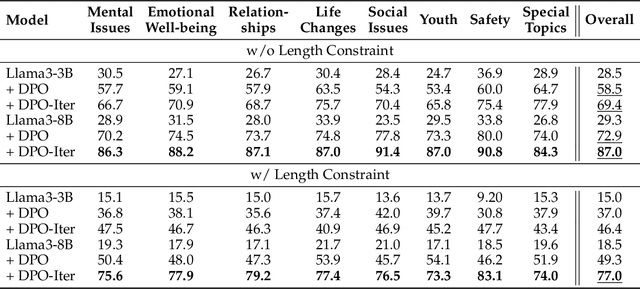
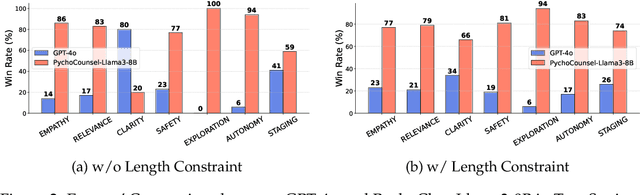
Applying large language models (LLMs) to assist in psycho-counseling is an emerging and meaningful approach, driven by the significant gap between patient needs and the availability of mental health support. However, current LLMs struggle to consistently provide effective responses to client speeches, largely due to the lack of supervision from high-quality real psycho-counseling data, whose content is typically inaccessible due to client privacy concerns. Furthermore, the quality of therapists' responses in available sessions can vary significantly based on their professional training and experience. Assessing the quality of therapists' responses remains an open challenge. In this work, we address these challenges by first proposing a set of professional and comprehensive principles to evaluate therapists' responses to client speeches. Using these principles, we create a preference dataset, PsychoCounsel-Preference, which contains 36k high-quality preference comparison pairs. This dataset aligns with the preferences of professional psychotherapists, providing a robust foundation for evaluating and improving LLMs in psycho-counseling. Experiments on reward modeling and preference learning demonstrate that PsychoCounsel-Preference is an excellent resource for LLMs to acquire essential skills for responding to clients in a counseling session. Our best-aligned model, PsychoCounsel-Llama3-8B, achieves an impressive win rate of 87% against GPT-4o. We release PsychoCounsel-Preference, PsychoCounsel-Llama3-8B and the reward model PsychoCounsel Llama3-8B-Reward to facilitate the research of psycho-counseling with LLMs at: https://hf.co/Psychotherapy-LLM.
CBT-Bench: Evaluating Large Language Models on Assisting Cognitive Behavior Therapy
Oct 17, 2024
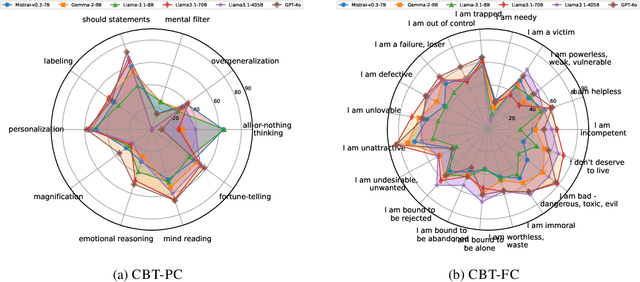

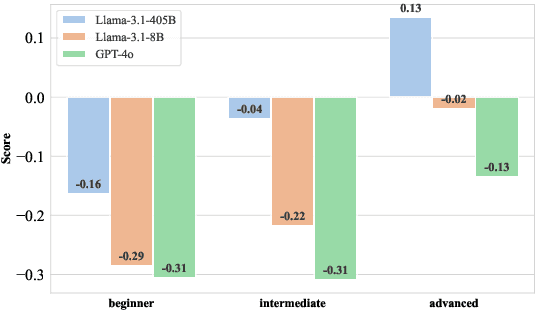
There is a significant gap between patient needs and available mental health support today. In this paper, we aim to thoroughly examine the potential of using Large Language Models (LLMs) to assist professional psychotherapy. To this end, we propose a new benchmark, CBT-BENCH, for the systematic evaluation of cognitive behavioral therapy (CBT) assistance. We include three levels of tasks in CBT-BENCH: I: Basic CBT knowledge acquisition, with the task of multiple-choice questions; II: Cognitive model understanding, with the tasks of cognitive distortion classification, primary core belief classification, and fine-grained core belief classification; III: Therapeutic response generation, with the task of generating responses to patient speech in CBT therapy sessions. These tasks encompass key aspects of CBT that could potentially be enhanced through AI assistance, while also outlining a hierarchy of capability requirements, ranging from basic knowledge recitation to engaging in real therapeutic conversations. We evaluated representative LLMs on our benchmark. Experimental results indicate that while LLMs perform well in reciting CBT knowledge, they fall short in complex real-world scenarios requiring deep analysis of patients' cognitive structures and generating effective responses, suggesting potential future work.
Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
May 30, 2024



Instruction Fine-Tuning (IFT) significantly enhances the zero-shot capabilities of pretrained Large Language Models (LLMs). While coding data is known to boost reasoning abilities during LLM pretraining, its role in activating internal reasoning capacities during IFT remains understudied. This paper investigates a key question: How does coding data impact LLMs' reasoning capacities during the IFT stage? To explore this, we thoroughly examine the impact of coding data across different coding data proportions, model families, sizes, and reasoning domains, from various perspectives. Specifically, we create three IFT datasets with increasing coding data proportions, fine-tune six LLM backbones across different families and scales on these datasets, evaluate the tuned models' performance across twelve tasks in three reasoning domains, and analyze the outcomes from three broad-to-granular perspectives: overall, domain-level, and task-specific. Our holistic analysis provides valuable insights in each perspective. First, coding data tuning enhances the overall reasoning capabilities of LLMs across different model families and scales. Moreover, the effect of coding data varies among different domains but shows consistent trends across model families and scales within each domain. Additionally, coding data generally yields comparable task-specific benefits across different model families, with the optimal coding data proportions in IFT datasets being task-specific.
PATIENT-Ψ: Using Large Language Models to Simulate Patients for Training Mental Health Professionals
May 30, 2024Mental illness remains one of the most critical public health issues, with a significant gap between the available mental health support and patient needs. Many mental health professionals highlight a disconnect between their training and real-world patient interactions, leaving some trainees feeling unprepared and potentially affecting their early career success. In this paper, we propose PATIENT-{\Psi}, a novel patient simulation framework for cognitive behavior therapy (CBT) training. To build PATIENT-{\Psi}, we constructed diverse patient profiles and their corresponding cognitive models based on CBT principles, and then used large language models (LLMs) programmed with the patient cognitive models to act as a simulated therapy patient. We propose an interactive training scheme, PATIENT-{\Psi}-TRAINER, for mental health trainees to practice a key skill in CBT -- formulating the cognitive model of the patient -- through role-playing a therapy session with PATIENT-{\Psi}. To evaluate PATIENT-{\Psi}, we conducted a user study of 4 mental health trainees and 10 experts. The results demonstrate that practice using PATIENT-{\Psi}-TRAINER greatly enhances the perceived skill acquisition and confidence of the trainees beyond existing forms of training such as textbooks, videos, and role-play with non-patients. Based on the experts' perceptions, PATIENT-{\Psi} is perceived to be closer to real patient interactions than GPT-4, and PATIENT-{\Psi}-TRAINER holds strong promise to improve trainee competencies. Our pioneering patient simulation training framework, using LLMs, holds great potential to enhance and advance mental health training, ultimately leading to improved patient care and outcomes. We will release all our data, code, and the training platform.
Large Language Models as Zero-shot Dialogue State Tracker through Function Calling
Feb 16, 2024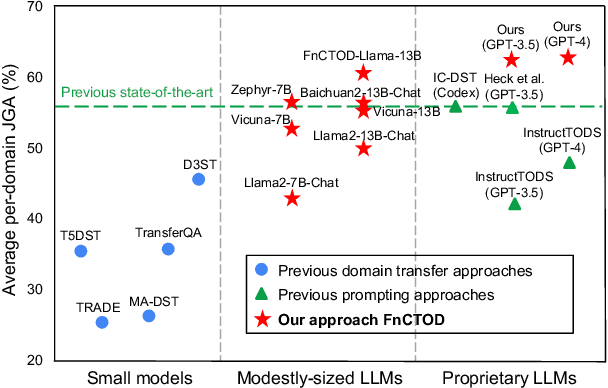

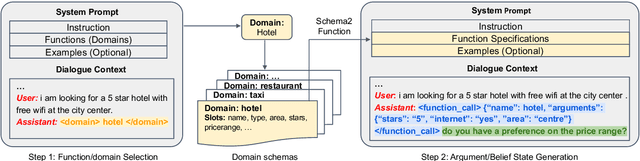
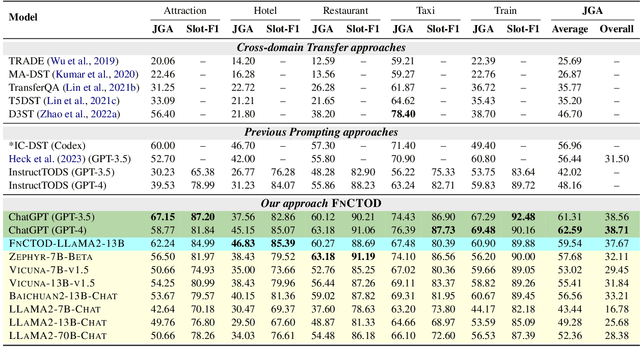
Large language models (LLMs) are increasingly prevalent in conversational systems due to their advanced understanding and generative capabilities in general contexts. However, their effectiveness in task-oriented dialogues (TOD), which requires not only response generation but also effective dialogue state tracking (DST) within specific tasks and domains, remains less satisfying. In this work, we propose a novel approach FnCTOD for solving DST with LLMs through function calling. This method improves zero-shot DST, allowing adaptation to diverse domains without extensive data collection or model tuning. Our experimental results demonstrate that our approach achieves exceptional performance with both modestly sized open-source and also proprietary LLMs: with in-context prompting it enables various 7B or 13B parameter models to surpass the previous state-of-the-art (SOTA) achieved by ChatGPT, and improves ChatGPT's performance beating the SOTA by 5.6% Avg. JGA. Individual model results for GPT-3.5 and GPT-4 are boosted by 4.8% and 14%, respectively. We also show that by fine-tuning on a small collection of diverse task-oriented dialogues, we can equip modestly sized models, specifically a 13B parameter LLaMA2-Chat model, with function-calling capabilities and DST performance comparable to ChatGPT while maintaining their chat capabilities. We plan to open-source experimental code and model.