 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Zero-shot Dialogue State Tracker through Function Calling
Feb 16, 2024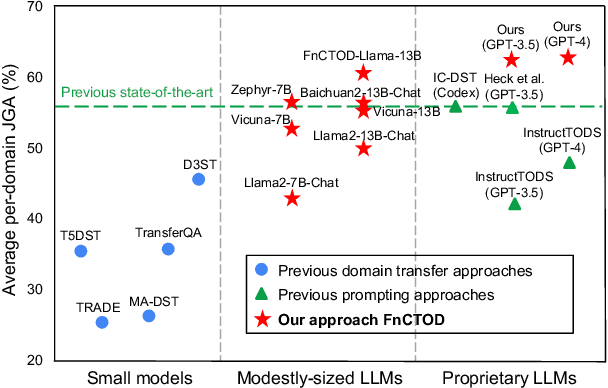

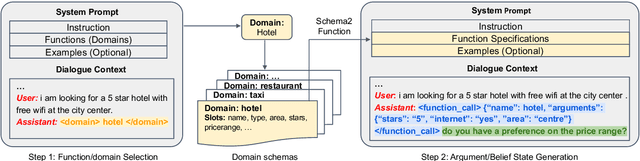
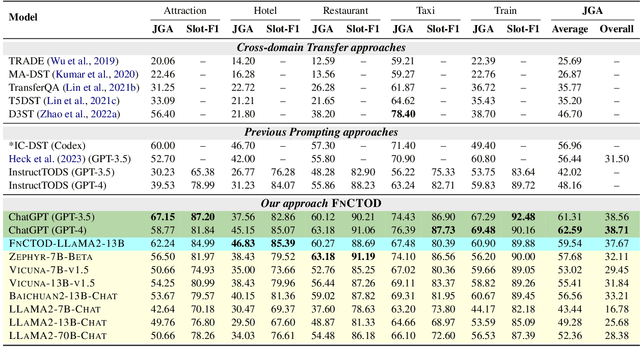
Large language models (LLMs) are increasingly prevalent in conversational systems due to their advanced understanding and generative capabilities in general contexts. However, their effectiveness in task-oriented dialogues (TOD), which requires not only response generation but also effective dialogue state tracking (DST) within specific tasks and domains, remains less satisfying. In this work, we propose a novel approach FnCTOD for solving DST with LLMs through function calling. This method improves zero-shot DST, allowing adaptation to diverse domains without extensive data collection or model tuning. Our experimental results demonstrate that our approach achieves exceptional performance with both modestly sized open-source and also proprietary LLMs: with in-context prompting it enables various 7B or 13B parameter models to surpass the previous state-of-the-art (SOTA) achieved by ChatGPT, and improves ChatGPT's performance beating the SOTA by 5.6% Avg. JGA. Individual model results for GPT-3.5 and GPT-4 are boosted by 4.8% and 14%, respectively. We also show that by fine-tuning on a small collection of diverse task-oriented dialogues, we can equip modestly sized models, specifically a 13B parameter LLaMA2-Chat model, with function-calling capabilities and DST performance comparable to ChatGPT while maintaining their chat capabilities. We plan to open-source experimental code and model.
Towards Zero-Shot Frame Semantic Parsing with Task Agnostic Ontologies and Simple Labels
May 05, 2023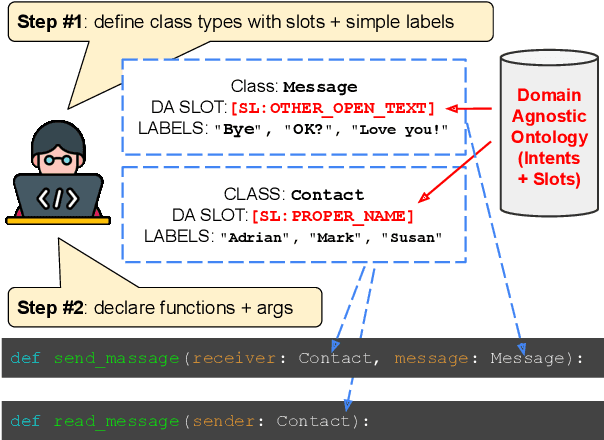
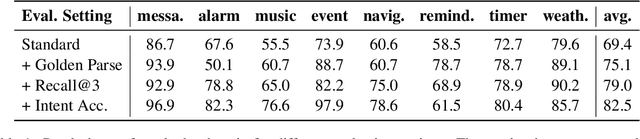
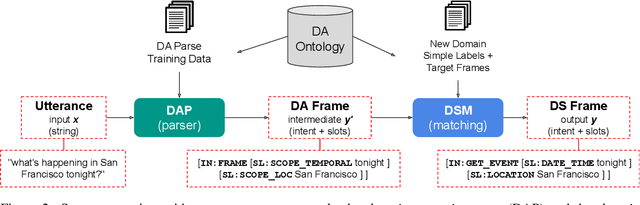
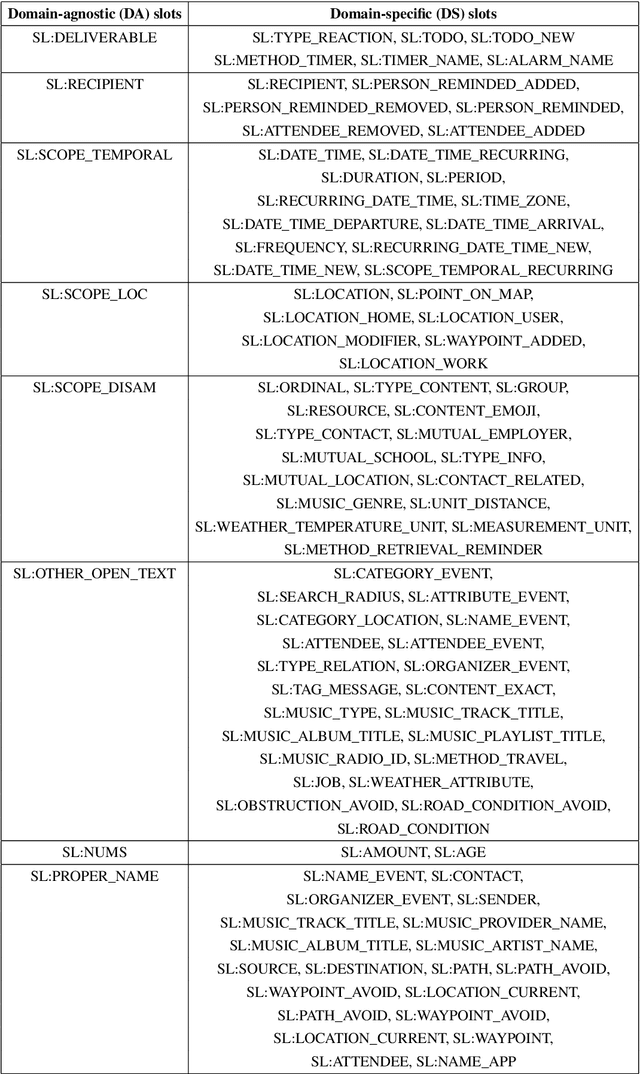
Frame semantic parsing is an important component of task-oriented dialogue systems. Current models rely on a significant amount training data to successfully identify the intent and slots in the user's input utterance. This creates a significant barrier for adding new domains to virtual assistant capabilities, as creation of this data requires highly specialized NLP expertise. In this work we propose OpenFSP, a framework that allows for easy creation of new domains from a handful of simple labels that can be generated without specific NLP knowledge. Our approach relies on creating a small, but expressive, set of domain agnostic slot types that enables easy annotation of new domains. Given such annotation, a matching algorithm relying on sentence encoders predicts the intent and slots for domains defined by end-users. Extensive experiments on the TopV2 dataset shows that our model outperforms strong baselines in this simple labels setting.
Data-Efficiency with a Single GPU: An Exploration of Transfer Methods for Small Language Models
Oct 08, 2022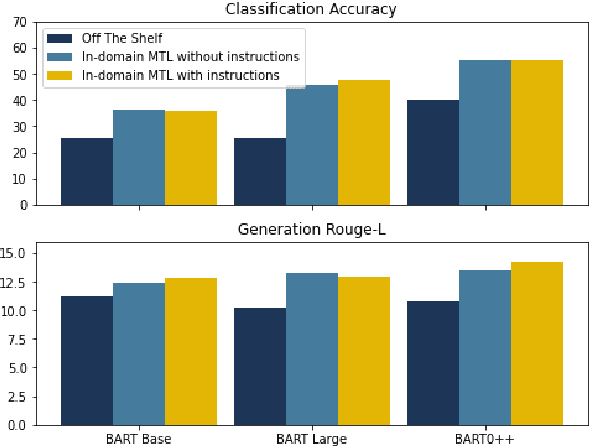
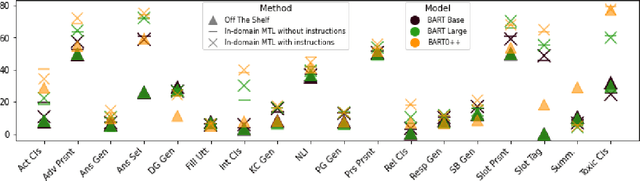
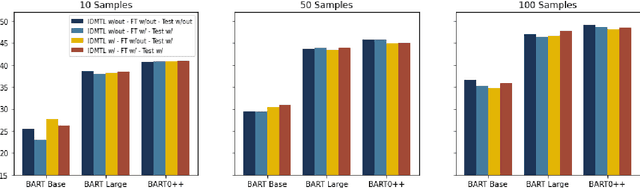
Multi-task learning (MTL), instruction tuning, and prompting have recently been shown to improve the generalizability of large language models to new tasks. However, the benefits of such methods are less well-documented in smaller language models, with some studies finding contradictory results. In this work, we explore and isolate the effects of (i) model size, (ii) general purpose MTL, (iii) in-domain MTL, (iv) instruction tuning, and (v) few-shot fine-tuning for models with fewer than 500 million parameters. Our experiments in the zero-shot setting demonstrate that models gain 31% relative improvement, on average, from general purpose MTL, with an additional 37.6% relative gain from in-domain MTL. Contradictory to prior works on large models, we find that instruction tuning provides a modest 2% performance improvement for small models.