 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Grounded Retrieval for Knowledgeable Large Multimodal Models
Jan 27, 2026Visual Question Answering (VQA) often requires coupling fine-grained perception with factual knowledge beyond the input image. Prior multimodal Retrieval-Augmented Generation (MM-RAG) systems improve factual grounding but lack an internal policy for when and how to retrieve. We propose PixSearch, the first end-to-end Segmenting Large Multimodal Model (LMM) that unifies region-level perception and retrieval-augmented reasoning. During encoding, PixSearch emits <search> tokens to trigger retrieval, selects query modalities (text, image, or region), and generates pixel-level masks that directly serve as visual queries, eliminating the reliance on modular pipelines (detectors, segmenters, captioners, etc.). A two-stage supervised fine-tuning regimen with search-interleaved supervision teaches retrieval timing and query selection while preserving segmentation ability. On egocentric and entity-centric VQA benchmarks, PixSearch substantially improves factual consistency and generalization, yielding a 19.7% relative gain in accuracy on CRAG-MM compared to whole image retrieval, while retaining competitive reasoning performance on various VQA and text-only QA tasks.
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage
Oct 02, 2025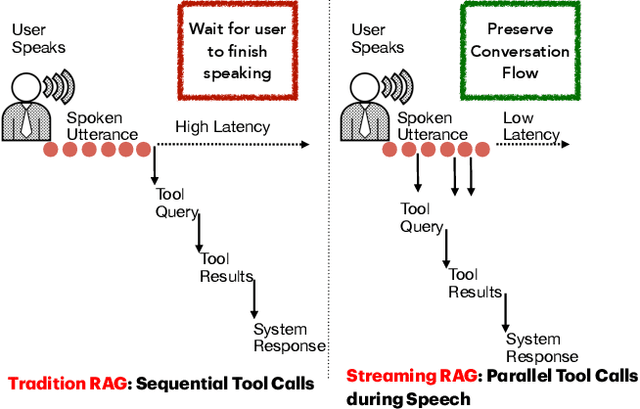
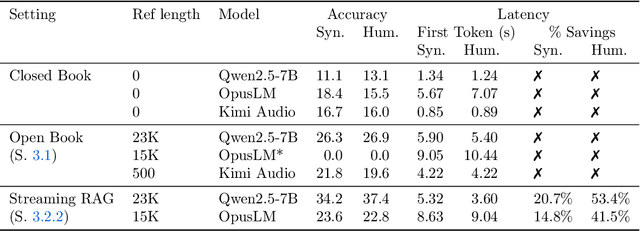
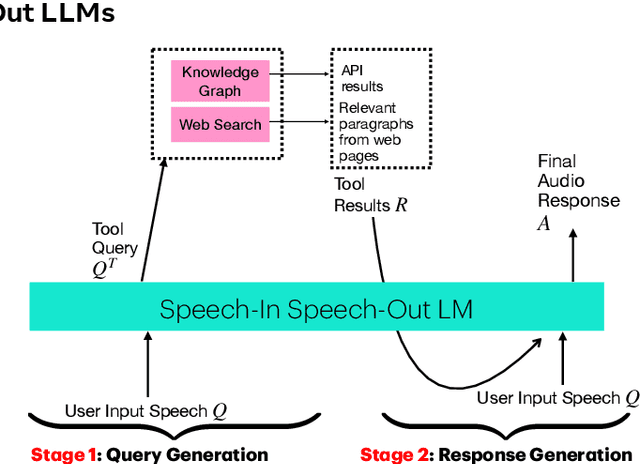
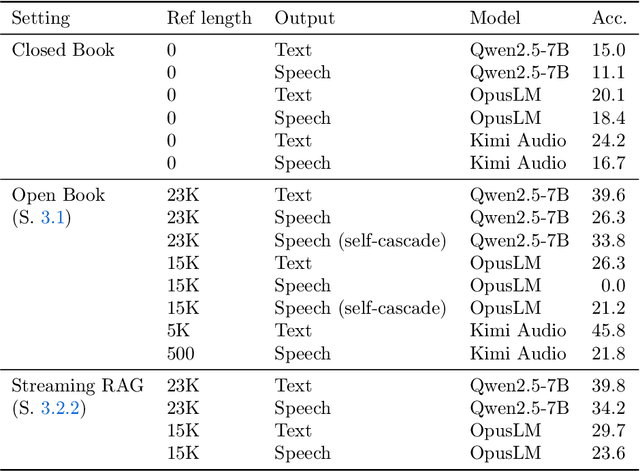
End-to-end speech-in speech-out dialogue systems are emerging as a powerful alternative to traditional ASR-LLM-TTS pipelines, generating more natural, expressive responses with significantly lower latency. However, these systems remain prone to hallucinations due to limited factual grounding. While text-based dialogue systems address this challenge by integrating tools such as web search and knowledge graph APIs, we introduce the first approach to extend tool use directly into speech-in speech-out systems. A key challenge is that tool integration substantially increases response latency, disrupting conversational flow. To mitigate this, we propose Streaming Retrieval-Augmented Generation (Streaming RAG), a novel framework that reduces user-perceived latency by predicting tool queries in parallel with user speech, even before the user finishes speaking. Specifically, we develop a post-training pipeline that teaches the model when to issue tool calls during ongoing speech and how to generate spoken summaries that fuse audio queries with retrieved text results, thereby improving both accuracy and responsiveness. To evaluate our approach, we construct AudioCRAG, a benchmark created by converting queries from the publicly available CRAG dataset into speech form. Experimental results demonstrate that our streaming RAG approach increases QA accuracy by up to 200% relative (from 11.1% to 34.2% absolute) and further enhances user experience by reducing tool use latency by 20%. Importantly, our streaming RAG approach is modality-agnostic and can be applied equally to typed input, paving the way for more agentic, real-time AI assistants.
Proactive Assistant Dialogue Generation from Streaming Egocentric Videos
Jun 06, 2025Recent advances in conversational AI have been substantial, but developing real-time systems for perceptual task guidance remains challenging. These systems must provide interactive, proactive assistance based on streaming visual inputs, yet their development is constrained by the costly and labor-intensive process of data collection and system evaluation. To address these limitations, we present a comprehensive framework with three key contributions. First, we introduce a novel data curation pipeline that synthesizes dialogues from annotated egocentric videos, resulting in \dataset, a large-scale synthetic dialogue dataset spanning multiple domains. Second, we develop a suite of automatic evaluation metrics, validated through extensive human studies. Third, we propose an end-to-end model that processes streaming video inputs to generate contextually appropriate responses, incorporating novel techniques for handling data imbalance and long-duration videos. This work lays the foundation for developing real-time, proactive AI assistants capable of guiding users through diverse tasks. Project page: https://pro-assist.github.io/
VisualLens: Personalization through Visual History
Nov 25, 2024

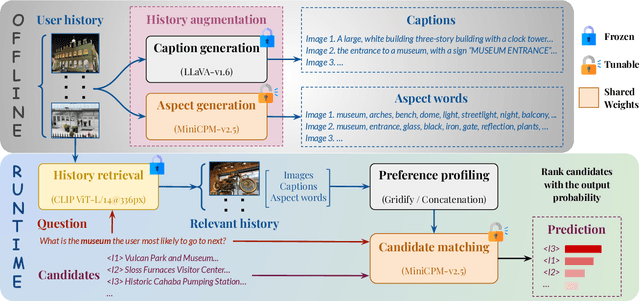
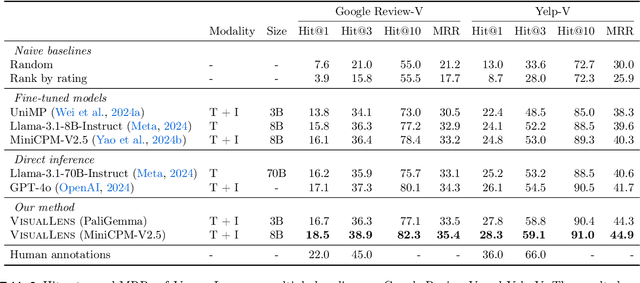
We hypothesize that a user's visual history with images reflecting their daily life, offers valuable insights into their interests and preferences, and can be leveraged for personalization. Among the many challenges to achieve this goal, the foremost is the diversity and noises in the visual history, containing images not necessarily related to a recommendation task, not necessarily reflecting the user's interest, or even not necessarily preference-relevant. Existing recommendation systems either rely on task-specific user interaction logs, such as online shopping history for shopping recommendations, or focus on text signals. We propose a novel approach, VisualLens, that extracts, filters, and refines image representations, and leverages these signals for personalization. We created two new benchmarks with task-agnostic visual histories, and show that our method improves over state-of-the-art recommendations by 5-10% on Hit@3, and improves over GPT-4o by 2-5%. Our approach paves the way for personalized recommendations in scenarios where traditional methods fail.
Doppelgänger's Watch: A Split Objective Approach to Large Language Models
Sep 09, 2024In this paper, we investigate the problem of "generation supervision" in large language models, and present a novel bicameral architecture to separate supervision signals from their core capability, helpfulness. Doppelg\"anger, a new module parallel to the underlying language model, supervises the generation of each token, and learns to concurrently predict the supervision score(s) of the sequences up to and including each token. In this work, we present the theoretical findings, and leave the report on experimental results to a forthcoming publication.
SnapNTell: Enhancing Entity-Centric Visual Question Answering with Retrieval Augmented Multimodal LLM
Mar 07, 2024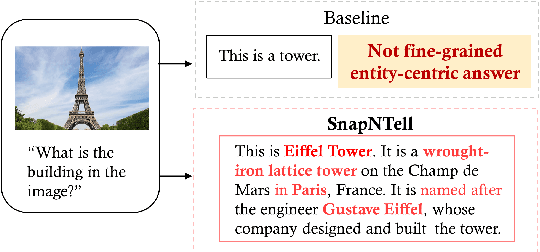

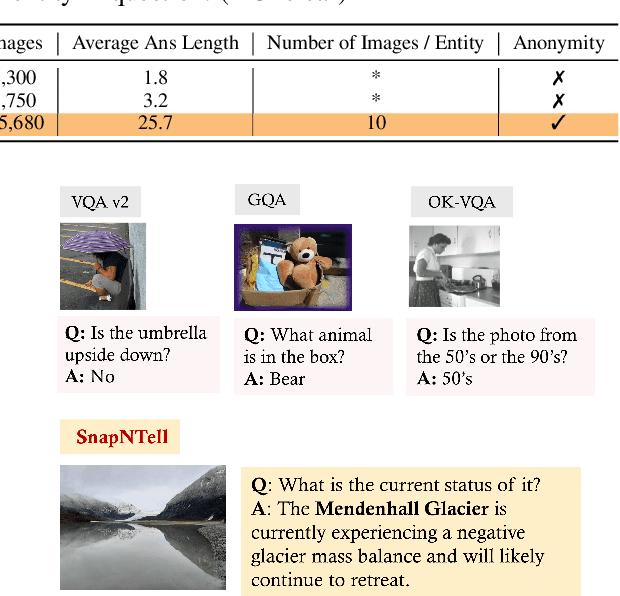
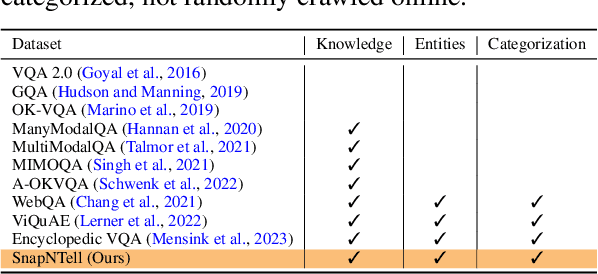
Vision-extended LLMs have made significant strides in Visual Question Answering (VQA). Despite these advancements, VLLMs still encounter substantial difficulties in handling queries involving long-tail entities, with a tendency to produce erroneous or hallucinated responses. In this work, we introduce a novel evaluative benchmark named \textbf{SnapNTell}, specifically tailored for entity-centric VQA. This task aims to test the models' capabilities in identifying entities and providing detailed, entity-specific knowledge. We have developed the \textbf{SnapNTell Dataset}, distinct from traditional VQA datasets: (1) It encompasses a wide range of categorized entities, each represented by images and explicitly named in the answers; (2) It features QA pairs that require extensive knowledge for accurate responses. The dataset is organized into 22 major categories, containing 7,568 unique entities in total. For each entity, we curated 10 illustrative images and crafted 10 knowledge-intensive QA pairs. To address this novel task, we devised a scalable, efficient, and transparent retrieval-augmented multimodal LLM. Our approach markedly outperforms existing methods on the SnapNTell dataset, achieving a 66.5\% improvement in the BELURT score. We will soon make the dataset and the source code publicly accessible.
Large Language Models as Zero-shot Dialogue State Tracker through Function Calling
Feb 16, 2024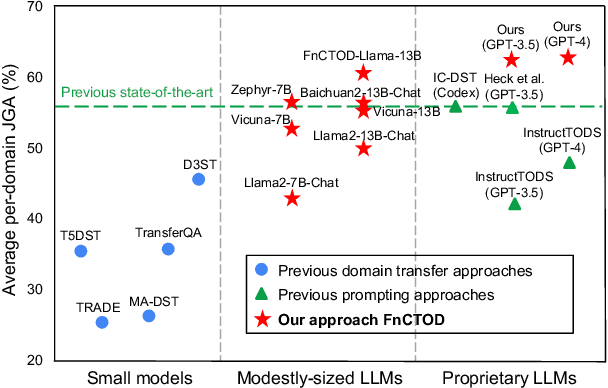

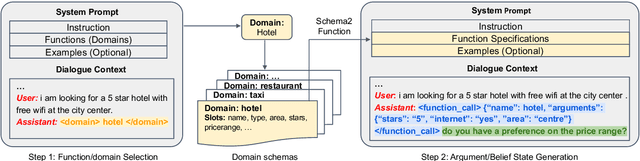
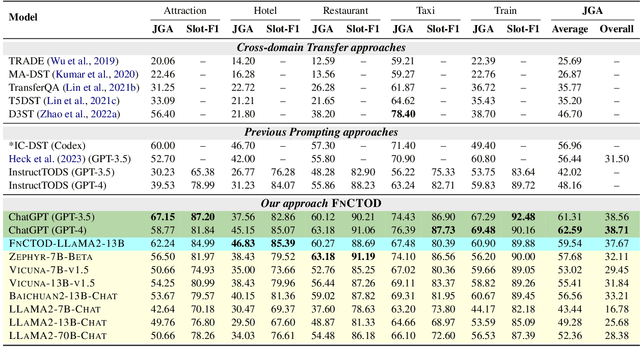
Large language models (LLMs) are increasingly prevalent in conversational systems due to their advanced understanding and generative capabilities in general contexts. However, their effectiveness in task-oriented dialogues (TOD), which requires not only response generation but also effective dialogue state tracking (DST) within specific tasks and domains, remains less satisfying. In this work, we propose a novel approach FnCTOD for solving DST with LLMs through function calling. This method improves zero-shot DST, allowing adaptation to diverse domains without extensive data collection or model tuning. Our experimental results demonstrate that our approach achieves exceptional performance with both modestly sized open-source and also proprietary LLMs: with in-context prompting it enables various 7B or 13B parameter models to surpass the previous state-of-the-art (SOTA) achieved by ChatGPT, and improves ChatGPT's performance beating the SOTA by 5.6% Avg. JGA. Individual model results for GPT-3.5 and GPT-4 are boosted by 4.8% and 14%, respectively. We also show that by fine-tuning on a small collection of diverse task-oriented dialogues, we can equip modestly sized models, specifically a 13B parameter LLaMA2-Chat model, with function-calling capabilities and DST performance comparable to ChatGPT while maintaining their chat capabilities. We plan to open-source experimental code and model.
AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
Sep 27, 2023



We present Any-Modality Augmented Language Model (AnyMAL), a unified model that reasons over diverse input modality signals (i.e. text, image, video, audio, IMU motion sensor), and generates textual responses. AnyMAL inherits the powerful text-based reasoning abilities of the state-of-the-art LLMs including LLaMA-2 (70B), and converts modality-specific signals to the joint textual space through a pre-trained aligner module. To further strengthen the multimodal LLM's capabilities, we fine-tune the model with a multimodal instruction set manually collected to cover diverse topics and tasks beyond simple QAs. We conduct comprehensive empirical analysis comprising both human and automatic evaluations, and demonstrate state-of-the-art performance on various multimodal tasks.
Embodied Executable Policy Learning with Language-based Scene Summarization
Jun 09, 2023Large Language models (LLMs) have shown remarkable success in assisting robot learning tasks, i.e., complex household planning. However, the performance of pretrained LLMs heavily relies on domain-specific templated text data, which may be infeasible in real-world robot learning tasks with image-based observations. Moreover, existing LLMs with text inputs lack the capability to evolve with non-expert interactions with environments. In this work, we introduce a novel learning paradigm that generates robots' executable actions in the form of text, derived solely from visual observations, using language-based summarization of these observations as the connecting bridge between both domains. Our proposed paradigm stands apart from previous works, which utilized either language instructions or a combination of language and visual data as inputs. Moreover, our method does not require oracle text summarization of the scene, eliminating the need for human involvement in the learning loop, which makes it more practical for real-world robot learning tasks. Our proposed paradigm consists of two modules: the SUM module, which interprets the environment using visual observations and produces a text summary of the scene, and the APM module, which generates executable action policies based on the natural language descriptions provided by the SUM module. We demonstrate that our proposed method can employ two fine-tuning strategies, including imitation learning and reinforcement learning approaches, to adapt to the target test tasks effectively. We conduct extensive experiments involving various SUM/APM model selections, environments, and tasks across 7 house layouts in the VirtualHome environment. Our experimental results demonstrate that our method surpasses existing baselines, confirming the effectiveness of this novel learning paradigm.
Normalized Contrastive Learning for Text-Video Retrieval
Nov 30, 2022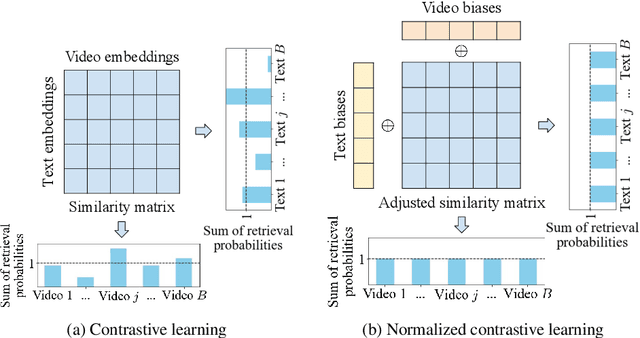
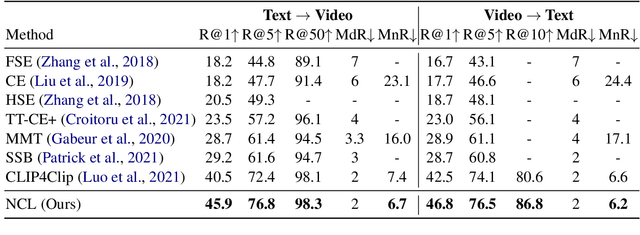
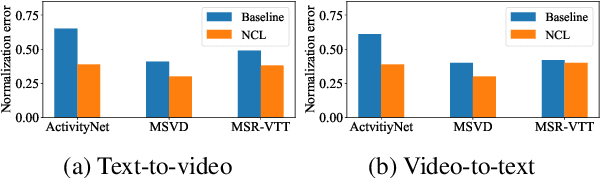
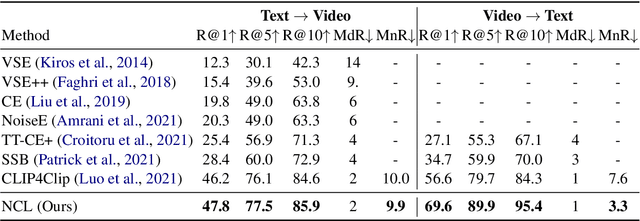
Cross-modal contrastive learning has led the recent advances in multimodal retrieval with its simplicity and effectiveness. In this work, however, we reveal that cross-modal contrastive learning suffers from incorrect normalization of the sum retrieval probabilities of each text or video instance. Specifically, we show that many test instances are either over- or under-represented during retrieval, significantly hurting the retrieval performance. To address this problem, we propose Normalized Contrastive Learning (NCL) which utilizes the Sinkhorn-Knopp algorithm to compute the instance-wise biases that properly normalize the sum retrieval probabilities of each instance so that every text and video instance is fairly represented during cross-modal retrieval. Empirical study shows that NCL brings consistent and significant gains in text-video retrieval on different model architectures, with new state-of-the-art multimodal retrieval metrics on the ActivityNet, MSVD, and MSR-VTT datasets without any architecture engineering.