 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Paralinguistic Understanding and Generation in Speech LLMs via Multi-Task Reinforcement Learning
Mar 16, 2026Speech large language models (LLMs) observe paralinguistic cues such as prosody, emotion, and non-verbal sounds--crucial for intent understanding. However, leveraging these cues faces challenges: limited training data, annotation difficulty, and models exploiting lexical shortcuts over paralinguistic signals. We propose multi-task reinforcement learning (RL) with chain-of-thought prompting that elicits explicit affective reasoning. To address data scarcity, we introduce a paralinguistics-aware speech LLM (PALLM) that jointly optimizes sentiment classification from audio and paralinguistics-aware response generation via a two-stage pipeline. Experiments demonstrate that our approach improves paralinguistics understanding over both supervised baselines and strong proprietary models (Gemini-2.5-Pro, GPT-4o-audio) by 8-12% on Expresso, IEMOCAP, and RAVDESS. The results show that modeling paralinguistic reasoning with multi-task RL is crucial for building emotionally intelligent speech LLMs.
Pixel-Grounded Retrieval for Knowledgeable Large Multimodal Models
Jan 27, 2026Visual Question Answering (VQA) often requires coupling fine-grained perception with factual knowledge beyond the input image. Prior multimodal Retrieval-Augmented Generation (MM-RAG) systems improve factual grounding but lack an internal policy for when and how to retrieve. We propose PixSearch, the first end-to-end Segmenting Large Multimodal Model (LMM) that unifies region-level perception and retrieval-augmented reasoning. During encoding, PixSearch emits <search> tokens to trigger retrieval, selects query modalities (text, image, or region), and generates pixel-level masks that directly serve as visual queries, eliminating the reliance on modular pipelines (detectors, segmenters, captioners, etc.). A two-stage supervised fine-tuning regimen with search-interleaved supervision teaches retrieval timing and query selection while preserving segmentation ability. On egocentric and entity-centric VQA benchmarks, PixSearch substantially improves factual consistency and generalization, yielding a 19.7% relative gain in accuracy on CRAG-MM compared to whole image retrieval, while retaining competitive reasoning performance on various VQA and text-only QA tasks.
WearVox: An Egocentric Multichannel Voice Assistant Benchmark for Wearables
Dec 25, 2025Wearable devices such as AI glasses are transforming voice assistants into always-available, hands-free collaborators that integrate seamlessly with daily life, but they also introduce challenges like egocentric audio affected by motion and noise, rapid micro-interactions, and the need to distinguish device-directed speech from background conversations. Existing benchmarks largely overlook these complexities, focusing instead on clean or generic conversational audio. To bridge this gap, we present WearVox, the first benchmark designed to rigorously evaluate voice assistants in realistic wearable scenarios. WearVox comprises 3,842 multi-channel, egocentric audio recordings collected via AI glasses across five diverse tasks including Search-Grounded QA, Closed-Book QA, Side-Talk Rejection, Tool Calling, and Speech Translation, spanning a wide range of indoor and outdoor environments and acoustic conditions. Each recording is accompanied by rich metadata, enabling nuanced analysis of model performance under real-world constraints. We benchmark leading proprietary and open-source speech Large Language Models (SLLMs) and find that most real-time SLLMs achieve accuracies on WearVox ranging from 29% to 59%, with substantial performance degradation on noisy outdoor audio, underscoring the difficulty and realism of the benchmark. Additionally, we conduct a case study with two new SLLMs that perform inference with single-channel and multi-channel audio, demonstrating that multi-channel audio inputs significantly enhance model robustness to environmental noise and improve discrimination between device-directed and background speech. Our results highlight the critical importance of spatial audio cues for context-aware voice assistants and establish WearVox as a comprehensive testbed for advancing wearable voice AI research.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
CRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025


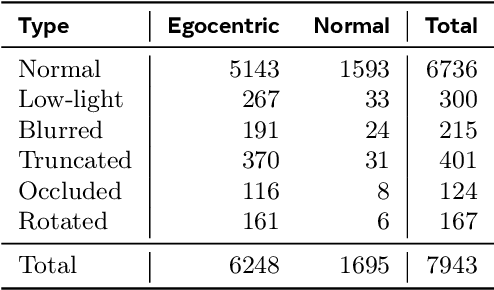
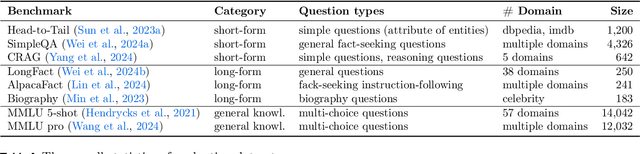
Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage
Oct 02, 2025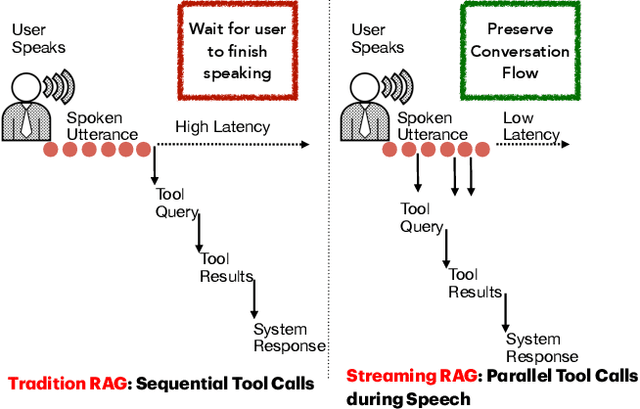
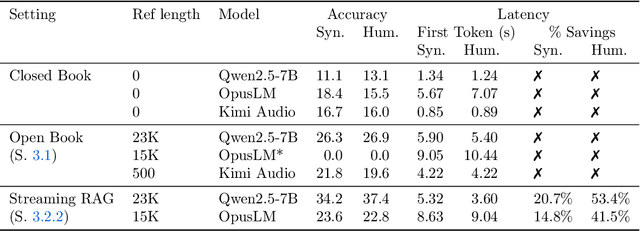
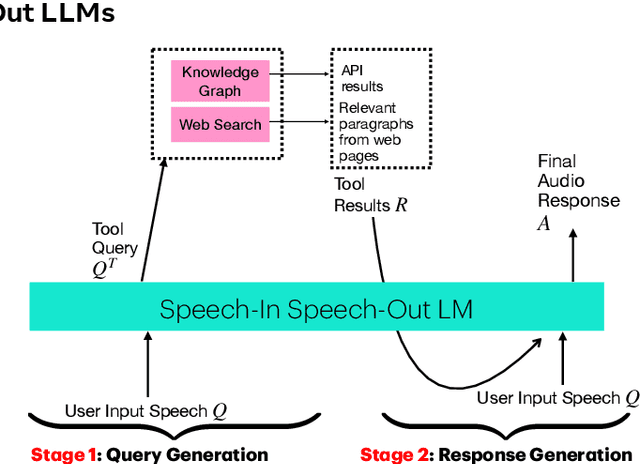
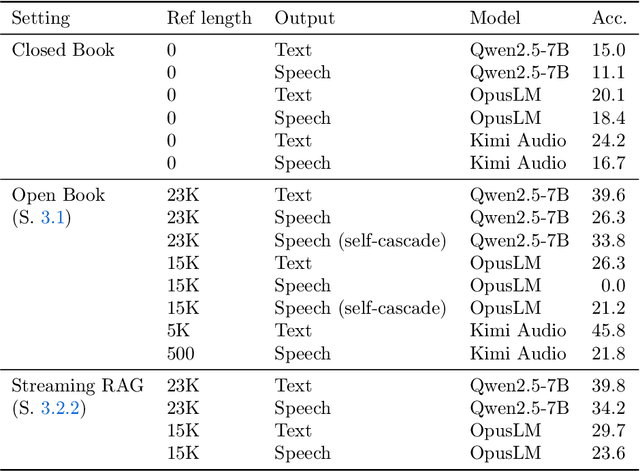
End-to-end speech-in speech-out dialogue systems are emerging as a powerful alternative to traditional ASR-LLM-TTS pipelines, generating more natural, expressive responses with significantly lower latency. However, these systems remain prone to hallucinations due to limited factual grounding. While text-based dialogue systems address this challenge by integrating tools such as web search and knowledge graph APIs, we introduce the first approach to extend tool use directly into speech-in speech-out systems. A key challenge is that tool integration substantially increases response latency, disrupting conversational flow. To mitigate this, we propose Streaming Retrieval-Augmented Generation (Streaming RAG), a novel framework that reduces user-perceived latency by predicting tool queries in parallel with user speech, even before the user finishes speaking. Specifically, we develop a post-training pipeline that teaches the model when to issue tool calls during ongoing speech and how to generate spoken summaries that fuse audio queries with retrieved text results, thereby improving both accuracy and responsiveness. To evaluate our approach, we construct AudioCRAG, a benchmark created by converting queries from the publicly available CRAG dataset into speech form. Experimental results demonstrate that our streaming RAG approach increases QA accuracy by up to 200% relative (from 11.1% to 34.2% absolute) and further enhances user experience by reducing tool use latency by 20%. Importantly, our streaming RAG approach is modality-agnostic and can be applied equally to typed input, paving the way for more agentic, real-time AI assistants.
SCRIBES: Web-Scale Script-Based Semi-Structured Data Extraction with Reinforcement Learning
Oct 02, 2025
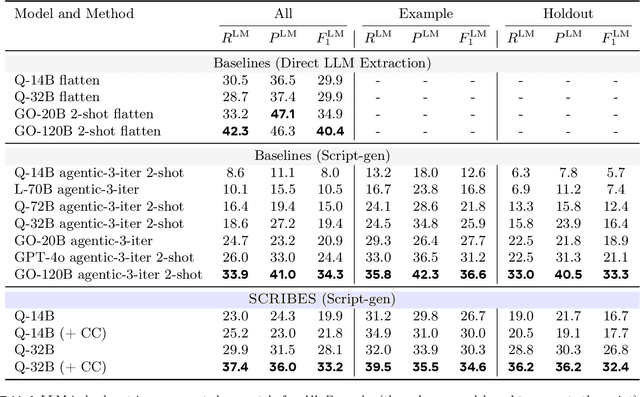


Semi-structured content in HTML tables, lists, and infoboxes accounts for a substantial share of factual data on the web, yet the formatting complicates usage, and reliably extracting structured information from them remains challenging. Existing methods either lack generalization or are resource-intensive due to per-page LLM inference. In this paper, we introduce SCRIBES (SCRIpt-Based Semi-Structured Content Extraction at Web-Scale), a novel reinforcement learning framework that leverages layout similarity across webpages within the same site as a reward signal. Instead of processing each page individually, SCRIBES generates reusable extraction scripts that can be applied to groups of structurally similar webpages. Our approach further improves by iteratively training on synthetic annotations from in-the-wild CommonCrawl data. Experiments show that our approach outperforms strong baselines by over 13% in script quality and boosts downstream question answering accuracy by more than 4% for GPT-4o, enabling scalable and resource-efficient web information extraction.
ConfQA: Answer Only If You Are Confident
Jun 08, 2025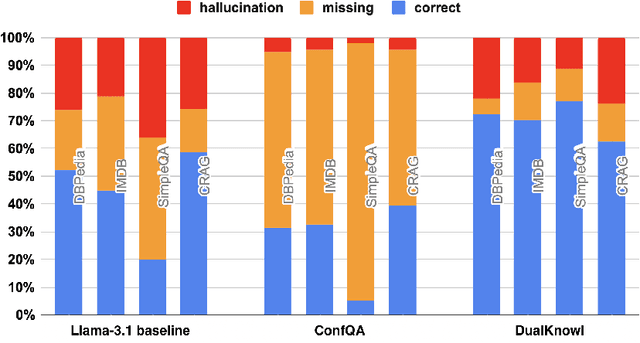
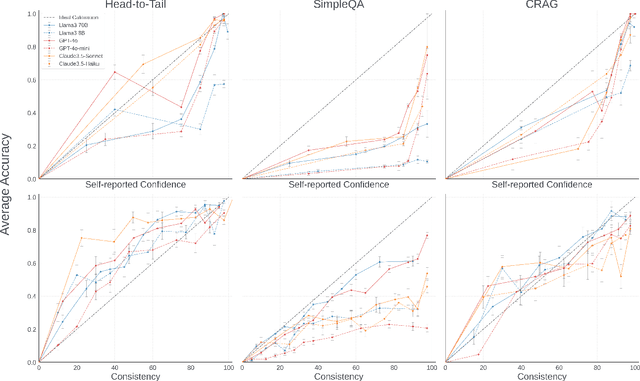
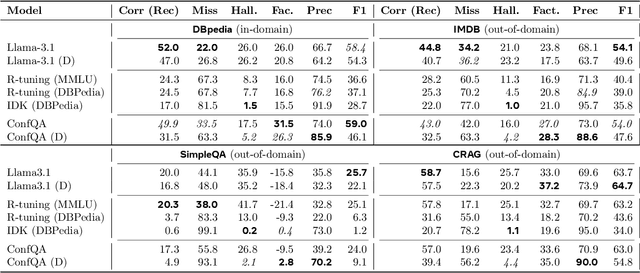
Can we teach Large Language Models (LLMs) to refrain from hallucinating factual statements? In this paper we present a fine-tuning strategy that we call ConfQA, which can reduce hallucination rate from 20-40% to under 5% across multiple factuality benchmarks. The core idea is simple: when the LLM answers a question correctly, it is trained to continue with the answer; otherwise, it is trained to admit "I am unsure". But there are two key factors that make the training highly effective. First, we introduce a dampening prompt "answer only if you are confident" to explicitly guide the behavior, without which hallucination remains high as 15%-25%. Second, we leverage simple factual statements, specifically attribute values from knowledge graphs, to help LLMs calibrate the confidence, resulting in robust generalization across domains and question types. Building on this insight, we propose the Dual Neural Knowledge framework, which seamlessly select between internally parameterized neural knowledge and externally recorded symbolic knowledge based on ConfQA's confidence. The framework enables potential accuracy gains to beyond 95%, while reducing unnecessary external retrievals by over 30%.
Proactive Assistant Dialogue Generation from Streaming Egocentric Videos
Jun 06, 2025Recent advances in conversational AI have been substantial, but developing real-time systems for perceptual task guidance remains challenging. These systems must provide interactive, proactive assistance based on streaming visual inputs, yet their development is constrained by the costly and labor-intensive process of data collection and system evaluation. To address these limitations, we present a comprehensive framework with three key contributions. First, we introduce a novel data curation pipeline that synthesizes dialogues from annotated egocentric videos, resulting in \dataset, a large-scale synthetic dialogue dataset spanning multiple domains. Second, we develop a suite of automatic evaluation metrics, validated through extensive human studies. Third, we propose an end-to-end model that processes streaming video inputs to generate contextually appropriate responses, incorporating novel techniques for handling data imbalance and long-duration videos. This work lays the foundation for developing real-time, proactive AI assistants capable of guiding users through diverse tasks. Project page: https://pro-assist.github.io/
VisualLens: Personalization through Visual History
Nov 25, 2024

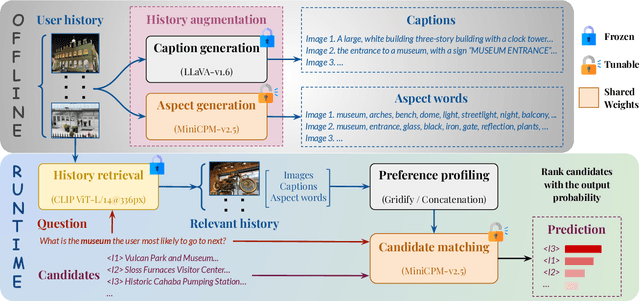
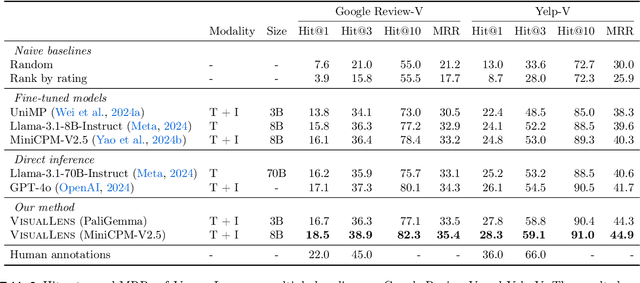
We hypothesize that a user's visual history with images reflecting their daily life, offers valuable insights into their interests and preferences, and can be leveraged for personalization. Among the many challenges to achieve this goal, the foremost is the diversity and noises in the visual history, containing images not necessarily related to a recommendation task, not necessarily reflecting the user's interest, or even not necessarily preference-relevant. Existing recommendation systems either rely on task-specific user interaction logs, such as online shopping history for shopping recommendations, or focus on text signals. We propose a novel approach, VisualLens, that extracts, filters, and refines image representations, and leverages these signals for personalization. We created two new benchmarks with task-agnostic visual histories, and show that our method improves over state-of-the-art recommendations by 5-10% on Hit@3, and improves over GPT-4o by 2-5%. Our approach paves the way for personalized recommendations in scenarios where traditional methods fail.