 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Vision Transformer-based Modeling Framework for Prediction of Fluid Flows in Energy Systems
Apr 02, 2026Computational fluid dynamics (CFD) simulations of complex fluid flows in energy systems are prohibitively expensive due to strong nonlinearities and multiscale-multiphysics interactions. In this work, we present a transformer-based modeling framework for prediction of fluid flows, and demonstrate it for high-pressure gas injection phenomena relevant to reciprocating engines. The approach employs a hierarchical Vision Transformer (SwinV2-UNet) architecture that processes multimodal flow datasets from multi-fidelity simulations. The model architecture is conditioned on auxiliary tokens explicitly encoding the data modality and time increment. Model performance is assessed on two different tasks: (1) spatiotemporal rollouts, where the model autoregressively predicts the flow state at future times; and (2) feature transformation, where the model infers unobserved fields/views from observed fields/views. We train separate models on multimodal datasets generated from in-house CFD simulations of argon jet injection into a nitrogen environment, encompassing multiple grid resolutions, turbulence models, and equations of state. The resulting data-driven models learn to generalize across resolutions and modalities, accurately forecasting the flow evolution and reconstructing missing flow-field information from limited views. This work demonstrates how large vision transformer-based models can be adapted to advance predictive modeling of complex fluid flow systems.
Mesh-based Super-resolution of Detonation Flows with Multiscale Graph Transformers
Nov 15, 2025Super-resolution flow reconstruction using state-of-the-art data-driven techniques is valuable for a variety of applications, such as subgrid/subfilter closure modeling, accelerating spatiotemporal forecasting, data compression, and serving as an upscaling tool for sparse experimental measurements. In the present work, a first-of-its-kind multiscale graph transformer approach is developed for mesh-based super-resolution (SR-GT) of reacting flows. The novel data-driven modeling paradigm leverages a graph-based flow-field representation compatible with complex geometries and non-uniform/unstructured grids. Further, the transformer backbone captures long-range dependencies between different parts of the low-resolution flow-field, identifies important features, and then generates the super-resolved flow-field that preserves those features at a higher resolution. The performance of SR-GT is demonstrated in the context of spectral-element-discretized meshes for a challenging test problem of 2D detonation propagation within a premixed hydrogen-air mixture exhibiting highly complex multiscale reacting flow behavior. The SR-GT framework utilizes a unique element-local (+ neighborhood) graph representation for the coarse input, which is then tokenized before being processed by the transformer component to produce the fine output. It is demonstrated that SR-GT provides high super-resolution accuracy for reacting flow-field features and superior performance compared to traditional interpolation-based SR schemes.
Generative Deep Learning Framework for Inverse Design of Fuels
Apr 16, 2025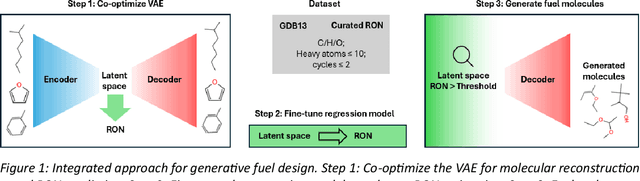
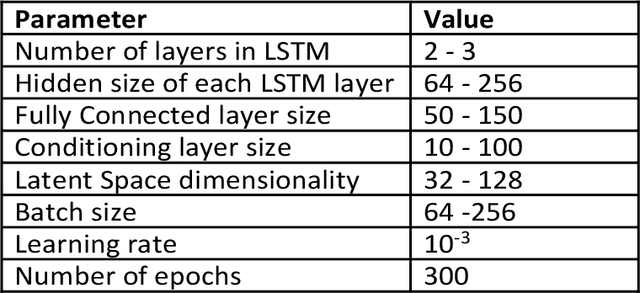
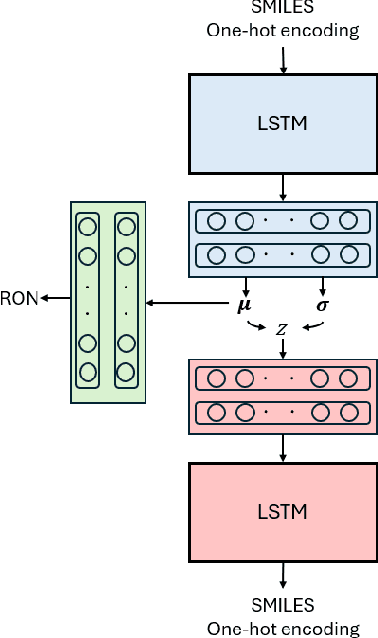

In the present work, a generative deep learning framework combining a Co-optimized Variational Autoencoder (Co-VAE) architecture with quantitative structure-property relationship (QSPR) techniques is developed to enable accelerated inverse design of fuels. The Co-VAE integrates a property prediction component coupled with the VAE latent space, enhancing molecular reconstruction and accurate estimation of Research Octane Number (RON) (chosen as the fuel property of interest). A subset of the GDB-13 database, enriched with a curated RON database, is used for model training. Hyperparameter tuning is further utilized to optimize the balance among reconstruction fidelity, chemical validity, and RON prediction. An independent regression model is then used to refine RON prediction, while a differential evolution algorithm is employed to efficiently navigate the VAE latent space and identify promising fuel molecule candidates with high RON. This methodology addresses the limitations of traditional fuel screening approaches by capturing complex structure-property relationships within a comprehensive latent representation. The generative model provides a flexible tool for systematically exploring vast chemical spaces, paving the way for discovering fuels with superior anti-knock properties. The demonstrated approach can be readily extended to incorporate additional fuel properties and synthesizability criteria to enhance applicability and reliability for de novo design of new fuels.
Scalable and Consistent Graph Neural Networks for Distributed Mesh-based Data-driven Modeling
Oct 02, 2024This work develops a distributed graph neural network (GNN) methodology for mesh-based modeling applications using a consistent neural message passing layer. As the name implies, the focus is on enabling scalable operations that satisfy physical consistency via halo nodes at sub-graph boundaries. Here, consistency refers to the fact that a GNN trained and evaluated on one rank (one large graph) is arithmetically equivalent to evaluations on multiple ranks (a partitioned graph). This concept is demonstrated by interfacing GNNs with NekRS, a GPU-capable exascale CFD solver developed at Argonne National Laboratory. It is shown how the NekRS mesh partitioning can be linked to the distributed GNN training and inference routines, resulting in a scalable mesh-based data-driven modeling workflow. We study the impact of consistency on the scalability of mesh-based GNNs, demonstrating efficient scaling in consistent GNNs for up to O(1B) graph nodes on the Frontier exascale supercomputer.
Mesh-based Super-Resolution of Fluid Flows with Multiscale Graph Neural Networks
Sep 12, 2024A graph neural network (GNN) approach is introduced in this work which enables mesh-based three-dimensional super-resolution of fluid flows. In this framework, the GNN is designed to operate not on the full mesh-based field at once, but on localized meshes of elements (or cells) directly. To facilitate mesh-based GNN representations in a manner similar to spectral (or finite) element discretizations, a baseline GNN layer (termed a message passing layer, which updates local node properties) is modified to account for synchronization of coincident graph nodes, rendering compatibility with commonly used element-based mesh connectivities. The architecture is multiscale in nature, and is comprised of a combination of coarse-scale and fine-scale message passing layer sequences (termed processors) separated by a graph unpooling layer. The coarse-scale processor embeds a query element (alongside a set number of neighboring coarse elements) into a single latent graph representation using coarse-scale synchronized message passing over the element neighborhood, and the fine-scale processor leverages additional message passing operations on this latent graph to correct for interpolation errors. Demonstration studies are performed using hexahedral mesh-based data from Taylor-Green Vortex flow simulations at Reynolds numbers of 1600 and 3200. Through analysis of both global and local errors, the results ultimately show how the GNN is able to produce accurate super-resolved fields compared to targets in both coarse-scale and multiscale model configurations. Reconstruction errors for fixed architectures were found to increase in proportion to the Reynolds number, while the inclusion of surrounding coarse element neighbors was found to improve predictions at Re=1600, but not at Re=3200.
Forward Gradients for Data-Driven CFD Wall Modeling
Nov 28, 2023
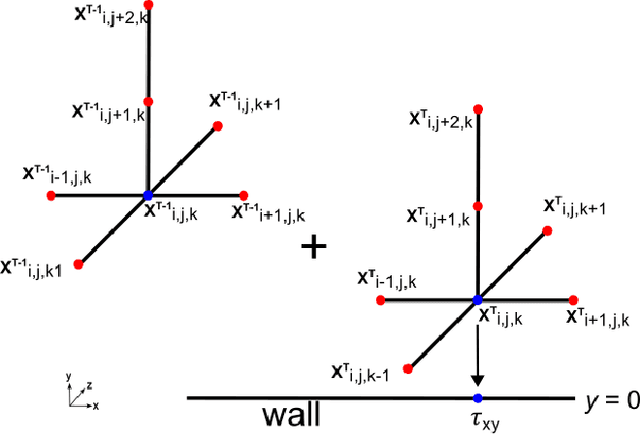
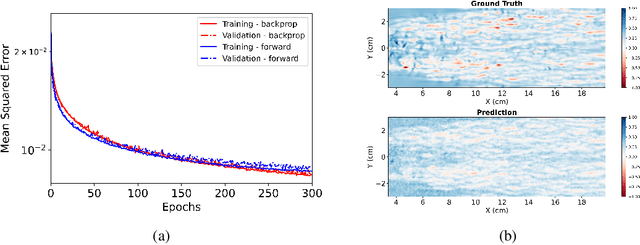
Computational Fluid Dynamics (CFD) is used in the design and optimization of gas turbines and many other industrial/ scientific applications. However, the practical use is often limited by the high computational cost, and the accurate resolution of near-wall flow is a significant contributor to this cost. Machine learning (ML) and other data-driven methods can complement existing wall models. Nevertheless, training these models is bottlenecked by the large computational effort and memory footprint demanded by back-propagation. Recent work has presented alternatives for computing gradients of neural networks where a separate forward and backward sweep is not needed and storage of intermediate results between sweeps is not required because an unbiased estimator for the gradient is computed in a single forward sweep. In this paper, we discuss the application of this approach for training a subgrid wall model that could potentially be used as a surrogate in wall-bounded flow CFD simulations to reduce the computational overhead while preserving predictive accuracy.
A Physics-Constrained NeuralODE Approach for Robust Learning of Stiff Chemical Kinetics
Nov 22, 2023The high computational cost associated with solving for detailed chemistry poses a significant challenge for predictive computational fluid dynamics (CFD) simulations of turbulent reacting flows. These models often require solving a system of coupled stiff ordinary differential equations (ODEs). While deep learning techniques have been experimented with to develop faster surrogate models, they often fail to integrate reliably with CFD solvers. This instability arises because deep learning methods optimize for training error without ensuring compatibility with ODE solvers, leading to accumulation of errors over time. Recently, NeuralODE-based techniques have offered a promising solution by effectively modeling chemical kinetics. In this study, we extend the NeuralODE framework for stiff chemical kinetics by incorporating mass conservation constraints directly into the loss function during training. This ensures that the total mass and the elemental mass are conserved, a critical requirement for reliable downstream integration with CFD solvers. Our results demonstrate that this enhancement not only improves the physical consistency with respect to mass conservation criteria but also ensures better robustness and makes the training process more computationally efficient.
An automated machine learning-genetic algorithm (AutoML-GA) approach for efficient simulation-driven engine design optimization
Jan 07, 2021


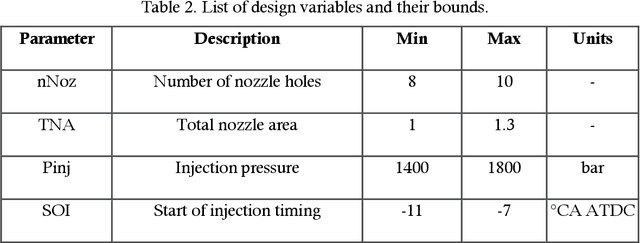
In recent years, the use of machine learning techniques as surrogate models for computational fluid dynamics (CFD) simulations has emerged as a promising method for reducing the computational cost associated with engine design optimization. However, such methods still suffer from drawbacks. One main disadvantage of such methods is that the default machine learning hyperparameters are often severely suboptimal for a given problem. This has often been addressed by manually trying out different hyperparameter settings, but this solution is ineffective in a high-dimensional hyperparameter space. Besides this problem, the amount of data needed for training is also not known a priori. In response to these issues which need to be addressed, this work describes and validates an automated active learning approach for surrogate-based optimization of internal combustion engines, AutoML-GA. In this approach, a Bayesian optimization technique is used to find the best machine learning hyperparameters based on an initial dataset obtained from a small number of CFD simulations. Subsequently, a genetic algorithm is employed to locate the design optimum on the surrogate surface trained with the optimal hyperparameters. In the vicinity of the design optimum, the solution is refined by repeatedly running CFD simulations at the projected optimum and adding the newly obtained data to the training dataset. It is shown that this approach leads to a better optimum with a lower number of CFD simulations, compared to the use of default hyperparameters. The developed approach offers the advantage of being a more hands-off approach that can be easily applied by researchers and engineers in industry who do not have a machine learning background.
A novel machine learning-based optimization algorithm (ActivO) for accelerating simulation-driven engine design
Jan 04, 2021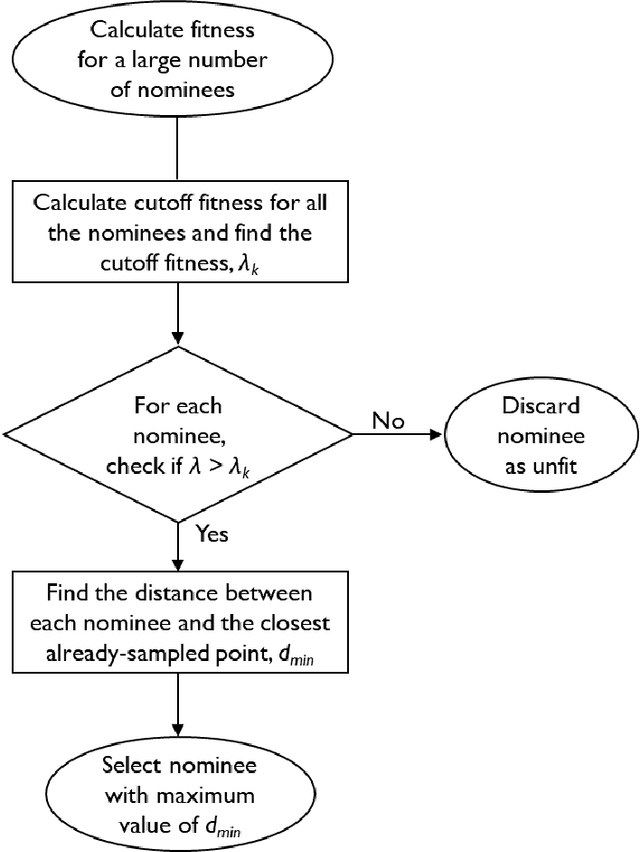
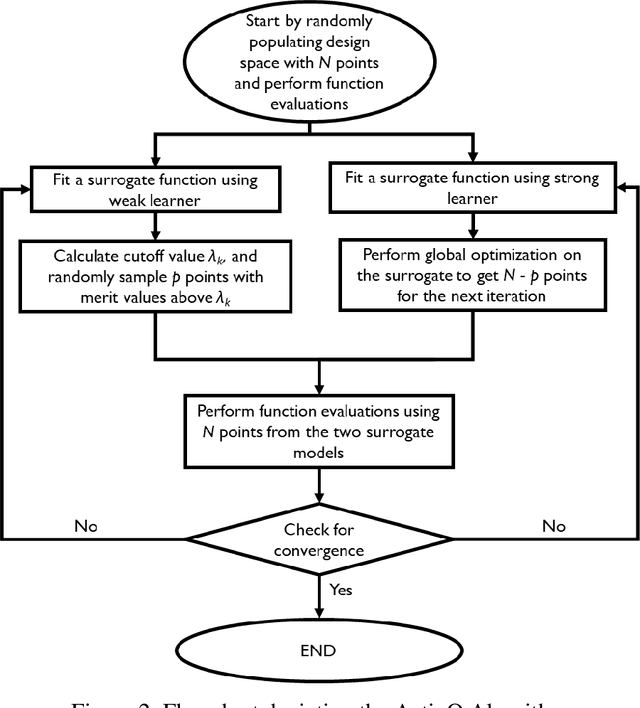

A novel design optimization approach (ActivO) that employs an ensemble of machine learning algorithms is presented. The proposed approach is a surrogate-based scheme, where the predictions of a weak leaner and a strong learner are utilized within an active learning loop. The weak learner is used to identify promising regions within the design space to explore, while the strong learner is used to determine the exact location of the optimum within promising regions. For each design iteration, exploration is done by randomly selecting evaluation points within regions where the weak learner-predicted fitness is high. The global optimum obtained by using the strong learner as a surrogate is also evaluated to enable rapid convergence once the most promising region has been identified. First, the performance of ActivO was compared against five other optimizers on a cosine mixture function with 25 local optima and one global optimum. In the second problem, the objective was to minimize indicated specific fuel consumption of a compression-ignition internal combustion (IC) engine while adhering to desired constraints associated with in-cylinder pressure and emissions. Here, the efficacy of the proposed approach is compared to that of a genetic algorithm, which is widely used within the internal combustion engine community for engine optimization, showing that ActivO reduces the number of function evaluations needed to reach the global optimum, and thereby time-to-design by 80%. Furthermore, the optimization of engine design parameters leads to savings of around 1.9% in energy consumption, while maintaining operability and acceptable pollutant emissions.