 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefill/Decode-Aware Evaluation of LLM Inference on Emerging AI Accelerators
Jun 14, 2026As large language models (LLMs) are increasingly deployed in latency- and cost-sensitive settings, inference efficiency has become a central systems challenge. While GPUs dominate current deployments, a growing number of AI accelerators claim advantages for LLM inference, yet it remains unclear under which conditions such accelerators outperform GPUs in practice. Recent inference systems decompose execution into Prefill and Decode phases, which exhibit distinct computational characteristics and latency metrics, commonly captured by time to first token (TTFT) and time per output token (TPOT). This paper presents a phase-aware evaluation of LLM inference performance across GPUs and emerging AI accelerators using a common model, Llama2-7B. By separately measuring Prefill and Decode performance, we reveal that accelerator advantages differ by phase and metric. Our results show that GPUs consistently excel in the compute-intensive Prefill phase, while GroqRack achieves significantly lower TPOT during Decode (batching not currently supported). However, GPUs regain an advantage in Decode throughput as batch size increases. These findings demonstrate that each platform exhibits distinct phase-dependent strengths. We further analyze heterogeneous Prefill/Decode disaggregation across different accelerator platforms, identifying performance gains and the workload and network conditions under which such gains are realized.
Probabilistic Attribution For Large Language Models
May 20, 2026The generative nature of Large Language Models (LLMs) is reflected in the conditional probabilities they compute to sample each response token given the previous tokens. These probabilities encode the distributional structure that the model learns in training and exploits in inference. In this work, we use these probabilities to situate LLMs within the mathematical theory of stochastic processes. We use this framework to design a model-agnostic probabilistic token attribution measure, using Bayes rule to invert the next-token log-probabilities so as to capture the models internal representation of the distribution over token sequences. The representation is independent of the models computational structure. This representation yields the conditional probability of the response given the prompt, and of the response given the prompt with a token marginalized away. Our attribution score is the log of the ratio of these probabilities. We further compute the entropies of a single prompts token distributions, conditioned on the remaining context. The interplay between entropy and attribution score sheds light on LLM behavior. We evaluate 8 models across 7 prompts and investigate anomalies, token sensitivity, response stability, model stability, and training convergence, thereby improving interpretability and guiding users to focus on uncertain or unstable parts of the generation.
Multi-Agent Orchestration for High-Throughput Materials Screening on a Leadership-Class System
Apr 09, 2026The integration of Artificial Intelligence (AI) with High-Performance Computing (HPC) is transforming scientific workflows from human-directed pipelines into adaptive systems capable of autonomous decision-making. Large language models (LLMs) play a critical role in autonomous workflows; however, deploying LLM-based agents at scale remains a significant challenge. Single-agent architectures and sequential tool calls often become serialization bottlenecks when executing large-scale simulation campaigns, failing to utilize the massive parallelism of exascale resources. To address this, we present a scalable, hierarchical multi-agent framework for orchestrating high-throughput screening campaigns. Our planner-executor architecture employs a central planning agent to dynamically partition workloads and assign subtasks to a swarm of parallel executor agents. All executor agents interface with a shared Model Context Protocol (MCP) server that orchestrates tasks via the Parsl workflow engine. To demonstrate this framework, we employed the open-weight gpt-oss-120b model to orchestrate a high-throughput screening of the Computation-Ready Experimental (CoRE) Metal-Organic Framework (MOF) database for atmospheric water harvesting. The results demonstrate that the proposed agentic framework enables efficient and scalable execution on the Aurora supercomputer, with low orchestration overhead and high task completion rates. This work establishes a flexible paradigm for LLM-driven scientific automation on HPC systems, with broad applicability to materials discovery and beyond.
Extending $μ$P: Spectral Conditions for Feature Learning Across Optimizers
Feb 24, 2026Several variations of adaptive first-order and second-order optimization methods have been proposed to accelerate and scale the training of large language models. The performance of these optimization routines is highly sensitive to the choice of hyperparameters (HPs), which are computationally expensive to tune for large-scale models. Maximal update parameterization $(μ$P$)$ is a set of scaling rules which aims to make the optimal HPs independent of the model size, thereby allowing the HPs tuned on a smaller (computationally cheaper) model to be transferred to train a larger, target model. Despite promising results for SGD and Adam, deriving $μ$P for other optimizers is challenging because the underlying tensor programming approach is difficult to grasp. Building on recent work that introduced spectral conditions as an alternative to tensor programs, we propose a novel framework to derive $μ$P for a broader class of optimizers, including AdamW, ADOPT, LAMB, Sophia, Shampoo and Muon. We implement our $μ$P derivations on multiple benchmark models and demonstrate zero-shot learning rate transfer across increasing model width for the above optimizers. Further, we provide empirical insights into depth-scaling parameterization for these optimizers.
Scalable Agentic Reasoning for Designing Biologics Targeting Intrinsically Disordered Proteins
Dec 17, 2025Intrinsically disordered proteins (IDPs) represent crucial therapeutic targets due to their significant role in disease -- approximately 80\% of cancer-related proteins contain long disordered regions -- but their lack of stable secondary/tertiary structures makes them "undruggable". While recent computational advances, such as diffusion models, can design high-affinity IDP binders, translating these to practical drug discovery requires autonomous systems capable of reasoning across complex conformational ensembles and orchestrating diverse computational tools at scale.To address this challenge, we designed and implemented StructBioReasoner, a scalable multi-agent system for designing biologics that can be used to target IDPs. StructBioReasoner employs a novel tournament-based reasoning framework where specialized agents compete to generate and refine therapeutic hypotheses, naturally distributing computational load for efficient exploration of the vast design space. Agents integrate domain knowledge with access to literature synthesis, AI-structure prediction, molecular simulations, and stability analysis, coordinating their execution on HPC infrastructure via an extensible federated agentic middleware, Academy. We benchmark StructBioReasoner across Der f 21 and NMNAT-2 and demonstrate that over 50\% of 787 designed and validated candidates for Der f 21 outperformed the human-designed reference binders from literature, in terms of improved binding free energy. For the more challenging NMNAT-2 protein, we identified three binding modes from 97,066 binders, including the well-studied NMNAT2:p53 interface. Thus, StructBioReasoner lays the groundwork for agentic reasoning systems for IDP therapeutic discovery on Exascale platforms.
Sketch-Augmented Features Improve Learning Long-Range Dependencies in Graph Neural Networks
Nov 05, 2025Graph Neural Networks learn on graph-structured data by iteratively aggregating local neighborhood information. While this local message passing paradigm imparts a powerful inductive bias and exploits graph sparsity, it also yields three key challenges: (i) oversquashing of long-range information, (ii) oversmoothing of node representations, and (iii) limited expressive power. In this work we inject randomized global embeddings of node features, which we term \textit{Sketched Random Features}, into standard GNNs, enabling them to efficiently capture long-range dependencies. The embeddings are unique, distance-sensitive, and topology-agnostic -- properties which we analytically and empirically show alleviate the aforementioned limitations when injected into GNNs. Experimental results on real-world graph learning tasks confirm that this strategy consistently improves performance over baseline GNNs, offering both a standalone solution and a complementary enhancement to existing techniques such as graph positional encodings. Our source code is available at \href{https://github.com/ryienh/sketched-random-features}{https://github.com/ryienh/sketched-random-features}.
PagedEviction: Structured Block-wise KV Cache Pruning for Efficient Large Language Model Inference
Sep 04, 2025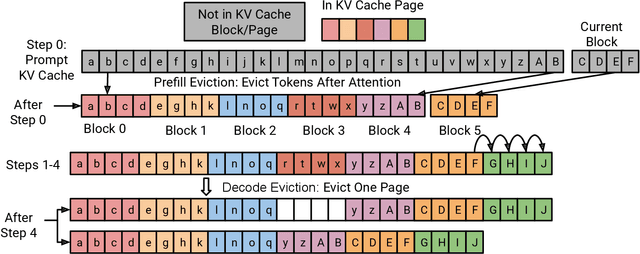



KV caching significantly improves the efficiency of Large Language Model (LLM) inference by storing attention states from previously processed tokens, enabling faster generation of subsequent tokens. However, as sequence length increases, the KV cache quickly becomes a major memory bottleneck. To address this, we propose PagedEviction, a novel fine-grained, structured KV cache pruning strategy that enhances the memory efficiency of vLLM's PagedAttention. Unlike existing approaches that rely on attention-based token importance or evict tokens across different vLLM pages, PagedEviction introduces an efficient block-wise eviction algorithm tailored for paged memory layouts. Our method integrates seamlessly with PagedAttention without requiring any modifications to its CUDA attention kernels. We evaluate PagedEviction across Llama-3.1-8B-Instruct, Llama-3.2-1B-Instruct, and Llama-3.2-3B-Instruct models on the LongBench benchmark suite, demonstrating improved memory usage with better accuracy than baselines on long context tasks.
MoE-Inference-Bench: Performance Evaluation of Mixture of Expert Large Language and Vision Models
Aug 24, 2025Mixture of Experts (MoE) models have enabled the scaling of Large Language Models (LLMs) and Vision Language Models (VLMs) by achieving massive parameter counts while maintaining computational efficiency. However, MoEs introduce several inference-time challenges, including load imbalance across experts and the additional routing computational overhead. To address these challenges and fully harness the benefits of MoE, a systematic evaluation of hardware acceleration techniques is essential. We present MoE-Inference-Bench, a comprehensive study to evaluate MoE performance across diverse scenarios. We analyze the impact of batch size, sequence length, and critical MoE hyperparameters such as FFN dimensions and number of experts on throughput. We evaluate several optimization techniques on Nvidia H100 GPUs, including pruning, Fused MoE operations, speculative decoding, quantization, and various parallelization strategies. Our evaluation includes MoEs from the Mixtral, DeepSeek, OLMoE and Qwen families. The results reveal performance differences across configurations and provide insights for the efficient deployment of MoEs.
LangVision-LoRA-NAS: Neural Architecture Search for Variable LoRA Rank in Vision Language Models
Aug 17, 2025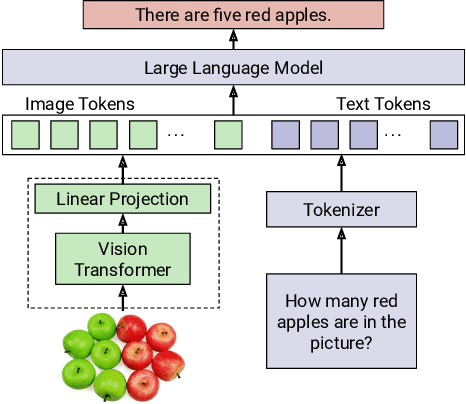
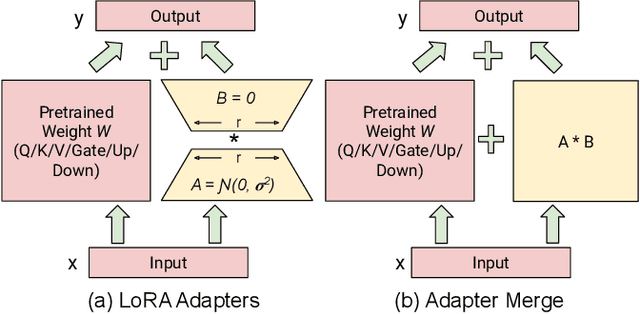
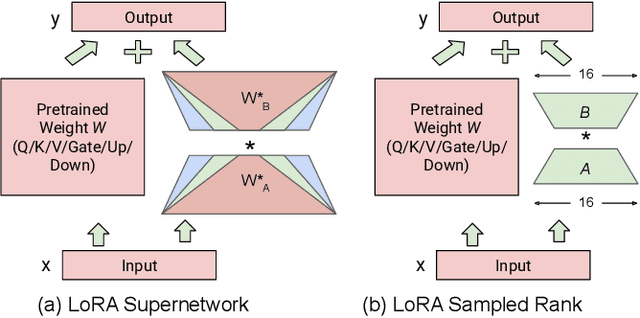
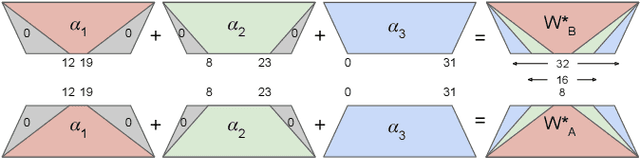
Vision Language Models (VLMs) integrate visual and text modalities to enable multimodal understanding and generation. These models typically combine a Vision Transformer (ViT) as an image encoder and a Large Language Model (LLM) for text generation. LoRA (Low-Rank Adaptation) is an efficient fine-tuning method to adapt pre-trained models to new tasks by introducing low-rank updates to their weights. While LoRA has emerged as a powerful technique for fine-tuning large models by introducing low-rank updates, current implementations assume a fixed rank, potentially limiting flexibility and efficiency across diverse tasks. This paper introduces \textit{LangVision-LoRA-NAS}, a novel framework that integrates Neural Architecture Search (NAS) with LoRA to optimize VLMs for variable-rank adaptation. Our approach leverages NAS to dynamically search for the optimal LoRA rank configuration tailored to specific multimodal tasks, balancing performance and computational efficiency. Through extensive experiments using the LLaMA-3.2-11B model on several datasets, LangVision-LoRA-NAS demonstrates notable improvement in model performance while reducing fine-tuning costs. Our Base and searched fine-tuned models on LLaMA-3.2-11B-Vision-Instruct can be found \href{https://huggingface.co/collections/krishnateja95/llama-32-11b-vision-instruct-langvision-lora-nas-6786cac480357a6a6fcc59ee}{\textcolor{blue}{here}} and the code for LangVision-LoRA-NAS can be found \href{https://github.com/krishnateja95/LangVision-NAS}{\textcolor{blue}{here}}.
AI Assistants to Enhance and Exploit the PETSc Knowledge Base
Jun 25, 2025Generative AI, especially through large language models (LLMs), is transforming how technical knowledge can be accessed, reused, and extended. PETSc, a widely used numerical library for high-performance scientific computing, has accumulated a rich but fragmented knowledge base over its three decades of development, spanning source code, documentation, mailing lists, GitLab issues, Discord conversations, technical papers, and more. Much of this knowledge remains informal and inaccessible to users and new developers. To activate and utilize this knowledge base more effectively, the PETSc team has begun building an LLM-powered system that combines PETSc content with custom LLM tools -- including retrieval-augmented generation (RAG), reranking algorithms, and chatbots -- to assist users, support developers, and propose updates to formal documentation. This paper presents initial experiences designing and evaluating these tools, focusing on system architecture, using RAG and reranking for PETSc-specific information, evaluation methodologies for various LLMs and embedding models, and user interface design. Leveraging the Argonne Leadership Computing Facility resources, we analyze how LLM responses can enhance the development and use of numerical software, with an initial focus on scalable Krylov solvers. Our goal is to establish an extensible framework for knowledge-centered AI in scientific software, enabling scalable support, enriched documentation, and enhanced workflows for research and development. We conclude by outlining directions for expanding this system into a robust, evolving platform that advances software ecosystems to accelerate scientific discovery.