 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOOST: BOttleneck-Optimized Scalable Training Framework for Low-Rank Large Language Models
Dec 13, 2025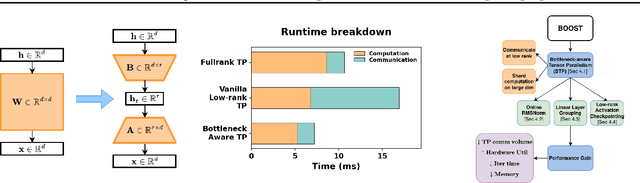

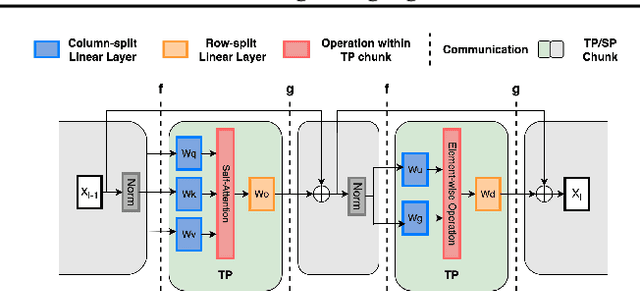
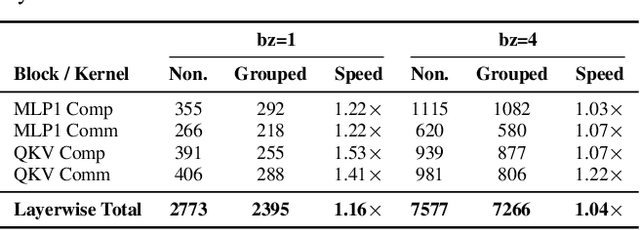
The scale of transformer model pre-training is constrained by the increasing computation and communication cost. Low-rank bottleneck architectures offer a promising solution to significantly reduce the training time and memory footprint with minimum impact on accuracy. Despite algorithmic efficiency, bottleneck architectures scale poorly under standard tensor parallelism. Simply applying 3D parallelism designed for full-rank methods leads to excessive communication and poor GPU utilization. To address this limitation, we propose BOOST, an efficient training framework tailored for large-scale low-rank bottleneck architectures. BOOST introduces a novel Bottleneck-aware Tensor Parallelism, and combines optimizations such as online-RMSNorm, linear layer grouping, and low-rank activation checkpointing to achieve end-to-end training speedup. Evaluations on different low-rank bottleneck architectures demonstrate that BOOST achieves 1.46-1.91$\times$ speedup over full-rank model baselines and 1.87-2.27$\times$ speedup over low-rank model with naively integrated 3D parallelism, with improved GPU utilization and reduced communication overhead.
PagedEviction: Structured Block-wise KV Cache Pruning for Efficient Large Language Model Inference
Sep 04, 2025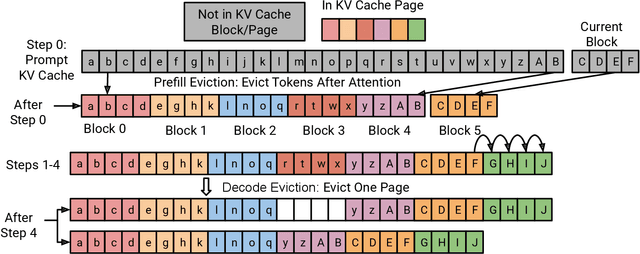



KV caching significantly improves the efficiency of Large Language Model (LLM) inference by storing attention states from previously processed tokens, enabling faster generation of subsequent tokens. However, as sequence length increases, the KV cache quickly becomes a major memory bottleneck. To address this, we propose PagedEviction, a novel fine-grained, structured KV cache pruning strategy that enhances the memory efficiency of vLLM's PagedAttention. Unlike existing approaches that rely on attention-based token importance or evict tokens across different vLLM pages, PagedEviction introduces an efficient block-wise eviction algorithm tailored for paged memory layouts. Our method integrates seamlessly with PagedAttention without requiring any modifications to its CUDA attention kernels. We evaluate PagedEviction across Llama-3.1-8B-Instruct, Llama-3.2-1B-Instruct, and Llama-3.2-3B-Instruct models on the LongBench benchmark suite, demonstrating improved memory usage with better accuracy than baselines on long context tasks.
EAIRA: Establishing a Methodology for Evaluating AI Models as Scientific Research Assistants
Feb 27, 2025Recent advancements have positioned AI, and particularly Large Language Models (LLMs), as transformative tools for scientific research, capable of addressing complex tasks that require reasoning, problem-solving, and decision-making. Their exceptional capabilities suggest their potential as scientific research assistants but also highlight the need for holistic, rigorous, and domain-specific evaluation to assess effectiveness in real-world scientific applications. This paper describes a multifaceted methodology for Evaluating AI models as scientific Research Assistants (EAIRA) developed at Argonne National Laboratory. This methodology incorporates four primary classes of evaluations. 1) Multiple Choice Questions to assess factual recall; 2) Open Response to evaluate advanced reasoning and problem-solving skills; 3) Lab-Style Experiments involving detailed analysis of capabilities as research assistants in controlled environments; and 4) Field-Style Experiments to capture researcher-LLM interactions at scale in a wide range of scientific domains and applications. These complementary methods enable a comprehensive analysis of LLM strengths and weaknesses with respect to their scientific knowledge, reasoning abilities, and adaptability. Recognizing the rapid pace of LLM advancements, we designed the methodology to evolve and adapt so as to ensure its continued relevance and applicability. This paper describes the methodology state at the end of February 2025. Although developed within a subset of scientific domains, the methodology is designed to be generalizable to a wide range of scientific domains.
Deep Optimizer States: Towards Scalable Training of Transformer Models Using Interleaved Offloading
Oct 26, 2024



Transformers and large language models~(LLMs) have seen rapid adoption in all domains. Their sizes have exploded to hundreds of billions of parameters and keep increasing. Under these circumstances, the training of transformers is very expensive and often hits a ``memory wall'', i.e., even when using 3D parallelism (pipeline, tensor, data) and aggregating the memory of many GPUs, it is still not enough to hold the necessary data structures (model parameters, optimizer state, gradients, activations) in GPU memory. To compensate, state-of-the-art approaches offload the optimizer state, at least partially, to the host memory and perform hybrid CPU-GPU computations. However, the management of the combined host-GPU memory is often suboptimal and results in poor overlapping between data movements and computations. This leads to missed opportunities to simultaneously leverage the interconnect bandwidth and computational capabilities of CPUs and GPUs. In this paper, we leverage a key observation that the interleaving of the forward, backward and update phases generate fluctuations in the GPU memory utilization, which can be exploited to dynamically move a part of the optimizer state between the host and the GPU memory at each iteration. To this end, we design and implement \proj, a novel technique to split the LLM into subgroups, whose update phase is scheduled on either the CPU or the GPU based on our proposed performance model that addresses the trade-off between data movement cost, acceleration on the GPUs vs the CPUs, and competition for shared resources. We integrate our approach with DeepSpeed and demonstrate 2.5$\times$ faster iterations over state-of-the-art approaches using extensive experiments.
DataStates-LLM: Lazy Asynchronous Checkpointing for Large Language Models
Jun 15, 2024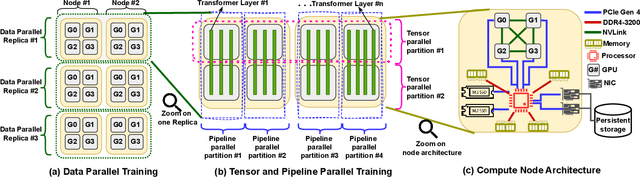

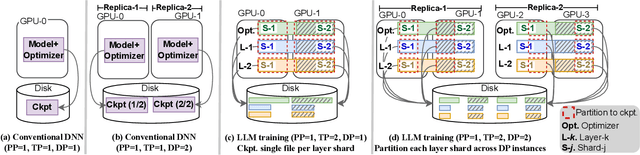
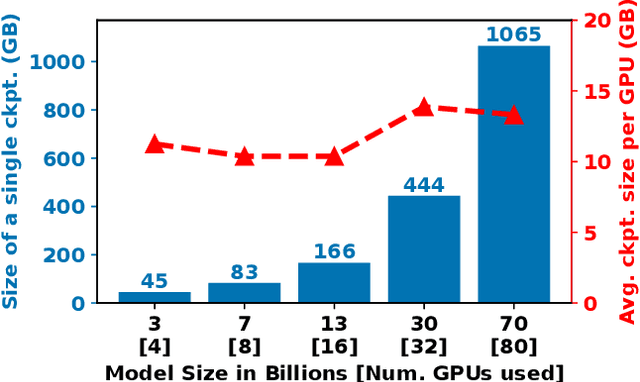
LLMs have seen rapid adoption in all domains. They need to be trained on high-end high-performance computing (HPC) infrastructures and ingest massive amounts of input data. Unsurprisingly, at such a large scale, unexpected events (e.g., failures of components, instability of the software, undesirable learning patterns, etc.), are frequent and typically impact the training in a negative fashion. Thus, LLMs need to be checkpointed frequently so that they can be rolled back to a stable state and subsequently fine-tuned. However, given the large sizes of LLMs, a straightforward checkpointing solution that directly writes the model parameters and optimizer state to persistent storage (e.g., a parallel file system), incurs significant I/O overheads. To address this challenge, in this paper we study how to reduce the I/O overheads for enabling fast and scalable checkpointing for LLMs that can be applied at high frequency (up to the granularity of individual iterations) without significant impact on the training process. Specifically, we introduce a lazy asynchronous multi-level approach that takes advantage of the fact that the tensors making up the model and optimizer state shards remain immutable for extended periods of time, which makes it possible to copy their content in the background with minimal interference during the training process. We evaluate our approach at scales of up to 180 GPUs using different model sizes, parallelism settings, and checkpointing frequencies. The results show up to 48$\times$ faster checkpointing and 2.2$\times$ faster end-to-end training runtime compared with the state-of-art checkpointing approaches.
Understanding Patterns of Deep Learning ModelEvolution in Network Architecture Search
Sep 22, 2023Network Architecture Search and specifically Regularized Evolution is a common way to refine the structure of a deep learning model.However, little is known about how models empirically evolve over time which has design implications for designing caching policies, refining the search algorithm for particular applications, and other important use cases.In this work, we algorithmically analyze and quantitatively characterize the patterns of model evolution for a set of models from the Candle project and the Nasbench-201 search space.We show how the evolution of the model structure is influenced by the regularized evolution algorithm. We describe how evolutionary patterns appear in distributed settings and opportunities for caching and improved scheduling. Lastly, we describe the conditions that affect when particular model architectures rise and fall in popularity based on their frequency of acting as a donor in a sliding window.