 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting New Concept-Object Associations in Astronomy by Mining the Literature
Feb 15, 2026We construct a concept-object knowledge graph from the full astro-ph corpus through July 2025. Using an automated pipeline, we extract named astrophysical objects from OCR-processed papers, resolve them to SIMBAD identifiers, and link them to scientific concepts annotated in the source corpus. We then test whether historical graph structure can forecast new concept-object associations before they appear in print. Because the concepts are derived from clustering and therefore overlap semantically, we apply an inference-time concept-similarity smoothing step uniformly to all methods. Across four temporal cutoffs on a physically meaningful subset of concepts, an implicit-feedback matrix factorization model (alternating least squares, ALS) with smoothing outperforms the strongest neighborhood baseline (KNN using text-embedding concept similarity) by 16.8% on NDCG@100 (0.144 vs 0.123) and 19.8% on Recall@100 (0.175 vs 0.146), and exceeds the best recency heuristic by 96% and 88%, respectively. These results indicate that historical literature encodes predictive structure not captured by global heuristics or local neighborhood voting, suggesting a path toward tools that could help triage follow-up targets for scarce telescope time.
Opportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration
Jan 20, 2026The Vera C. Rubin Observatory's Legacy Survey of Space and Time (LSST) will produce unprecedented volumes of heterogeneous astronomical data (images, catalogs, and alerts) that challenge traditional analysis pipelines. The LSST Dark Energy Science Collaboration (DESC) aims to derive robust constraints on dark energy and dark matter from these data, requiring methods that are statistically powerful, scalable, and operationally reliable. Artificial intelligence and machine learning (AI/ML) are already embedded across DESC science workflows, from photometric redshifts and transient classification to weak lensing inference and cosmological simulations. Yet their utility for precision cosmology hinges on trustworthy uncertainty quantification, robustness to covariate shift and model misspecification, and reproducible integration within scientific pipelines. This white paper surveys the current landscape of AI/ML across DESC's primary cosmological probes and cross-cutting analyses, revealing that the same core methodologies and fundamental challenges recur across disparate science cases. Since progress on these cross-cutting challenges would benefit multiple probes simultaneously, we identify key methodological research priorities, including Bayesian inference at scale, physics-informed methods, validation frameworks, and active learning for discovery. With an eye on emerging techniques, we also explore the potential of the latest foundation model methodologies and LLM-driven agentic AI systems to reshape DESC workflows, provided their deployment is coupled with rigorous evaluation and governance. Finally, we discuss critical software, computing, data infrastructure, and human capital requirements for the successful deployment of these new methodologies, and consider associated risks and opportunities for broader coordination with external actors.
AstroMLab 4: Benchmark-Topping Performance in Astronomy Q&A with a 70B-Parameter Domain-Specialized Reasoning Model
May 23, 2025General-purpose large language models, despite their broad capabilities, often struggle with specialized domain knowledge, a limitation particularly pronounced in more accessible, lower-parameter versions. This gap hinders their deployment as effective agents in demanding fields such as astronomy. Building on our prior work with AstroSage-8B, this study introduces AstroSage-70B, a significantly larger and more advanced domain-specialized natural-language AI assistant. It is designed for research and education across astronomy, astrophysics, space science, astroparticle physics, cosmology, and astronomical instrumentation. Developed from the Llama-3.1-70B foundation, AstroSage-70B underwent extensive continued pre-training on a vast corpus of astronomical literature, followed by supervised fine-tuning and model merging. Beyond its 70-billion parameter scale, this model incorporates refined datasets, judiciously chosen learning hyperparameters, and improved training procedures, achieving state-of-the-art performance on complex astronomical tasks. Notably, we integrated reasoning chains into the SFT dataset, enabling AstroSage-70B to either answer the user query immediately, or first emit a human-readable thought process. Evaluated on the AstroMLab-1 benchmark -- comprising 4,425 questions from literature withheld during training -- AstroSage-70B achieves state-of-the-art performance. It surpasses all other tested open-weight and proprietary models, including leading systems like o3, Gemini-2.5-Pro, Claude-3.7-Sonnet, Deepseek-R1, and Qwen-3-235B, even those with API costs two orders of magnitude higher. This work demonstrates that domain specialization, when applied to large-scale models, can enable them to outperform generalist counterparts in specialized knowledge areas like astronomy, thereby advancing the frontier of AI capabilities in the field.
EAIRA: Establishing a Methodology for Evaluating AI Models as Scientific Research Assistants
Feb 27, 2025Recent advancements have positioned AI, and particularly Large Language Models (LLMs), as transformative tools for scientific research, capable of addressing complex tasks that require reasoning, problem-solving, and decision-making. Their exceptional capabilities suggest their potential as scientific research assistants but also highlight the need for holistic, rigorous, and domain-specific evaluation to assess effectiveness in real-world scientific applications. This paper describes a multifaceted methodology for Evaluating AI models as scientific Research Assistants (EAIRA) developed at Argonne National Laboratory. This methodology incorporates four primary classes of evaluations. 1) Multiple Choice Questions to assess factual recall; 2) Open Response to evaluate advanced reasoning and problem-solving skills; 3) Lab-Style Experiments involving detailed analysis of capabilities as research assistants in controlled environments; and 4) Field-Style Experiments to capture researcher-LLM interactions at scale in a wide range of scientific domains and applications. These complementary methods enable a comprehensive analysis of LLM strengths and weaknesses with respect to their scientific knowledge, reasoning abilities, and adaptability. Recognizing the rapid pace of LLM advancements, we designed the methodology to evolve and adapt so as to ensure its continued relevance and applicability. This paper describes the methodology state at the end of February 2025. Although developed within a subset of scientific domains, the methodology is designed to be generalizable to a wide range of scientific domains.
AstroMLab 1: Who Wins Astronomy Jeopardy!?
Jul 15, 2024We present a comprehensive evaluation of proprietary and open-weights large language models using the first astronomy-specific benchmarking dataset. This dataset comprises 4,425 multiple-choice questions curated from the Annual Review of Astronomy and Astrophysics, covering a broad range of astrophysical topics. Our analysis examines model performance across various astronomical subfields and assesses response calibration, crucial for potential deployment in research environments. Claude-3.5-Sonnet outperforms competitors by up to 4.6 percentage points, achieving 85.0% accuracy. For proprietary models, we observed a universal reduction in cost every 3-to-12 months to achieve similar score in this particular astronomy benchmark. Open-source models have rapidly improved, with LLaMA-3-70b (80.6%) and Qwen-2-72b (77.7%) now competing with some of the best proprietary models. We identify performance variations across topics, with non-English-focused models generally struggling more in exoplanet-related fields, stellar astrophysics, and instrumentation related questions. These challenges likely stem from less abundant training data, limited historical context, and rapid recent developments in these areas. This pattern is observed across both open-weights and proprietary models, with regional dependencies evident, highlighting the impact of training data diversity on model performance in specialized scientific domains. Top-performing models demonstrate well-calibrated confidence, with correlations above 0.9 between confidence and correctness, though they tend to be slightly underconfident. The development for fast, low-cost inference of open-weights models presents new opportunities for affordable deployment in astronomy. The rapid progress observed suggests that LLM-driven research in astronomy may become feasible in the near future.
Application of probabilistic modeling and automated machine learning framework for high-dimensional stress field
Mar 15, 2023



Modern computational methods, involving highly sophisticated mathematical formulations, enable several tasks like modeling complex physical phenomenon, predicting key properties and design optimization. The higher fidelity in these computer models makes it computationally intensive to query them hundreds of times for optimization and one usually relies on a simplified model albeit at the cost of losing predictive accuracy and precision. Towards this, data-driven surrogate modeling methods have shown a lot of promise in emulating the behavior of the expensive computer models. However, a major bottleneck in such methods is the inability to deal with high input dimensionality and the need for relatively large datasets. With such problems, the input and output quantity of interest are tensors of high dimensionality. Commonly used surrogate modeling methods for such problems, suffer from requirements like high number of computational evaluations that precludes one from performing other numerical tasks like uncertainty quantification and statistical analysis. In this work, we propose an end-to-end approach that maps a high-dimensional image like input to an output of high dimensionality or its key statistics. Our approach uses two main framework that perform three steps: a) reduce the input and output from a high-dimensional space to a reduced or low-dimensional space, b) model the input-output relationship in the low-dimensional space, and c) enable the incorporation of domain-specific physical constraints as masks. In order to accomplish the task of reducing input dimensionality we leverage principal component analysis, that is coupled with two surrogate modeling methods namely: a) Bayesian hybrid modeling, and b) DeepHyper's deep neural networks. We demonstrate the applicability of the approach on a problem of a linear elastic stress field data.
Interpretable Uncertainty Quantification in AI for HEP
Aug 08, 2022Estimating uncertainty is at the core of performing scientific measurements in HEP: a measurement is not useful without an estimate of its uncertainty. The goal of uncertainty quantification (UQ) is inextricably linked to the question, "how do we physically and statistically interpret these uncertainties?" The answer to this question depends not only on the computational task we aim to undertake, but also on the methods we use for that task. For artificial intelligence (AI) applications in HEP, there are several areas where interpretable methods for UQ are essential, including inference, simulation, and control/decision-making. There exist some methods for each of these areas, but they have not yet been demonstrated to be as trustworthy as more traditional approaches currently employed in physics (e.g., non-AI frequentist and Bayesian methods). Shedding light on the questions above requires additional understanding of the interplay of AI systems and uncertainty quantification. We briefly discuss the existing methods in each area and relate them to tasks across HEP. We then discuss recommendations for avenues to pursue to develop the necessary techniques for reliable widespread usage of AI with UQ over the next decade.
Global field reconstruction from sparse sensors with Voronoi tessellation-assisted deep learning
Jan 03, 2021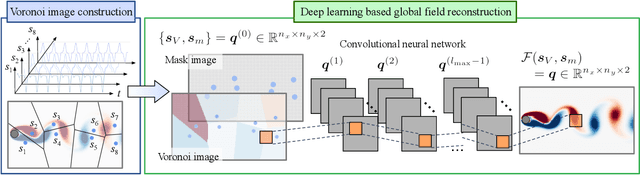
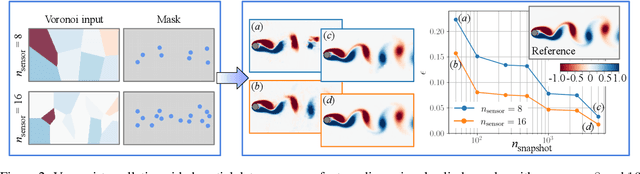

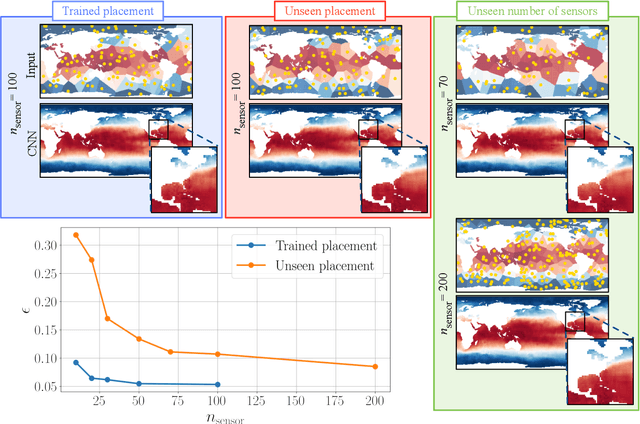
Achieving accurate and robust global situational awareness of a complex time-evolving field from a limited number of sensors has been a longstanding challenge. This reconstruction problem is especially difficult when sensors are sparsely positioned in a seemingly random or unorganized manner, which is often encountered in a range of scientific and engineering problems. Moreover, these sensors can be in motion and can become online or offline over time. The key leverage in addressing this scientific issue is the wealth of data accumulated from the sensors. As a solution to this problem, we propose a data-driven spatial field recovery technique founded on a structured grid-based deep-learning approach for arbitrary positioned sensors of any numbers. It should be noted that the na\"ive use of machine learning becomes prohibitively expensive for global field reconstruction and is furthermore not adaptable to an arbitrary number of sensors. In the present work, we consider the use of Voronoi tessellation to obtain a structured-grid representation from sensor locations enabling the computationally tractable use of convolutional neural networks. One of the central features of the present method is its compatibility with deep-learning based super-resolution reconstruction techniques for structured sensor data that are established for image processing. The proposed reconstruction technique is demonstrated for unsteady wake flow, geophysical data, and three-dimensional turbulence. The current framework is able to handle an arbitrary number of moving sensors, and thereby overcomes a major limitation with existing reconstruction methods. The presented technique opens a new pathway towards the practical use of neural networks for real-time global field estimation.
Latent-space time evolution of non-intrusive reduced-order models using Gaussian process emulation
Jul 23, 2020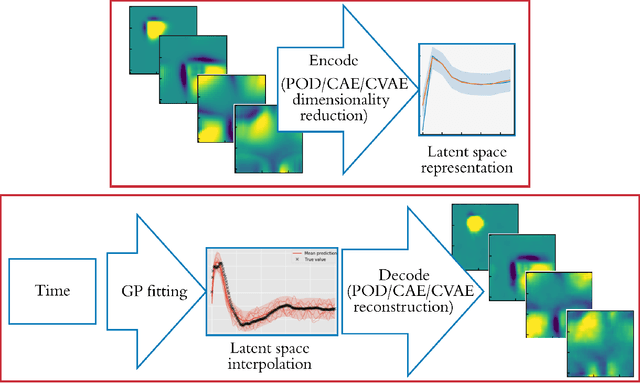
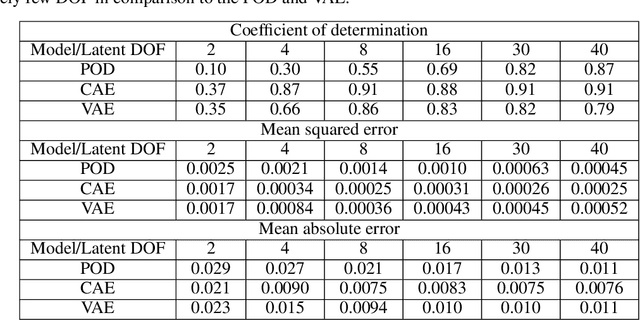
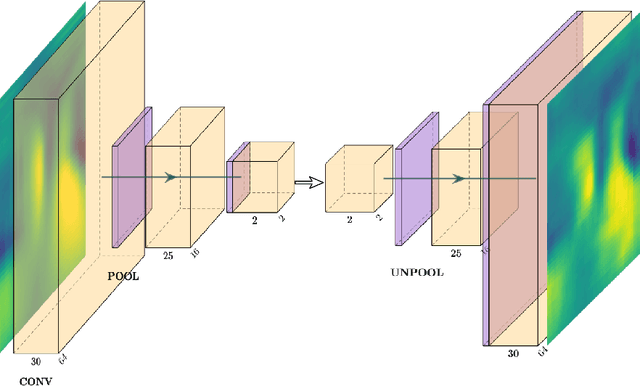
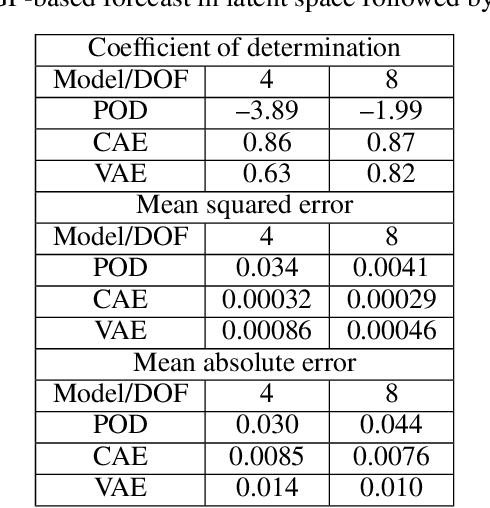
Non-intrusive reduced-order models (ROMs) have recently generated considerable interest for constructing computationally efficient counterparts of nonlinear dynamical systems emerging from various domain sciences. They provide a low-dimensional emulation framework for systems that may be intrinsically high-dimensional. This is accomplished by utilizing a construction algorithm that is purely data-driven. It is no surprise, therefore, that the algorithmic advances of machine learning have led to non-intrusive ROMs with greater accuracy and computational gains. However, in bypassing the utilization of an equation-based evolution, it is often seen that the interpretability of the ROM framework suffers. This becomes more problematic when black-box deep learning methods are used which are notorious for lacking robustness outside the physical regime of the observed data. In this article, we propose the use of a novel latent space interpolation algorithm based on Gaussian process regression. Notably, this reduced-order evolution of the system is parameterized by control parameters to allow for interpolation in space. The use of this procedure also allows for a continuous interpretation of time which allows for temporal interpolation. The latter aspect provides information, with quantified uncertainty, about full-state evolution at a finer resolution than that utilized for training the ROMs. We assess the viability of this algorithm for an advection-dominated system given by the inviscid shallow water equations.
Modular Deep Learning Analysis of Galaxy-Scale Strong Lensing Images
Nov 10, 2019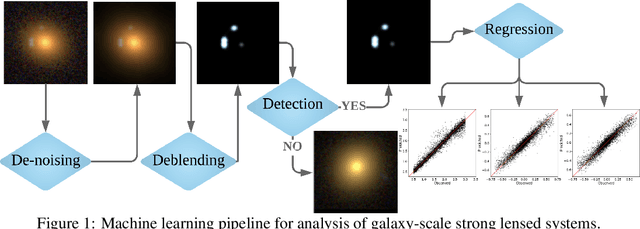
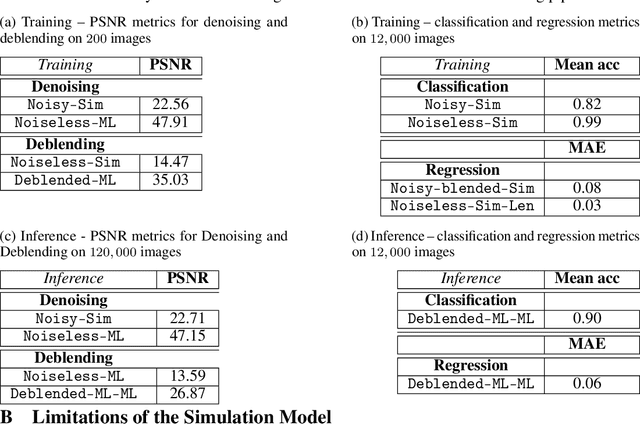

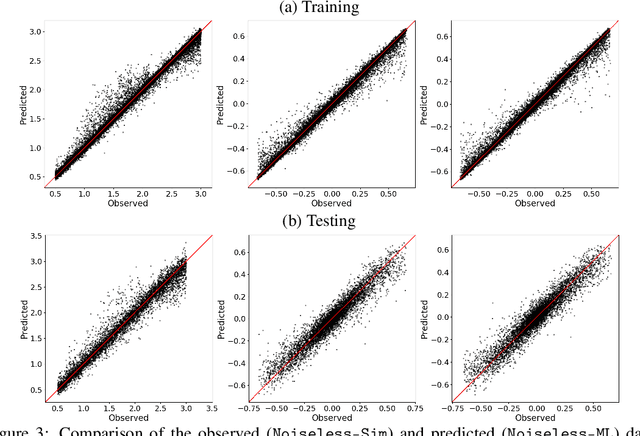
Strong gravitational lensing of astrophysical sources by foreground galaxies is a powerful cosmological tool. While such lens systems are relatively rare in the Universe, the number of detectable galaxy-scale strong lenses is expected to grow dramatically with next-generation optical surveys, numbering in the hundreds of thousands, out of tens of billions of candidate images. Automated and efficient approaches will be necessary in order to find and analyze these strong lens systems. To this end, we implement a novel, modular, end-to-end deep learning pipeline for denoising, deblending, searching, and modeling galaxy-galaxy strong lenses (GGSLs). To train and quantify the performance of our pipeline, we create a dataset of 1 million synthetic strong lensing images using state-of-the-art simulations for next-generation sky surveys. When these pretrained modules were used as a pipeline for inference, we found that the classification (searching GGSL) accuracy improved significantly---from 82% with the baseline to 90%, while the regression (modeling GGSL) accuracy improved by 25% over the baseline.