 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCQ: General-Purpose Deep-Surrogate Framework for Lossy Compression Quality Prediction
Dec 24, 2025Error-bounded lossy compression techniques have become vital for scientific data management and analytics, given the ever-increasing volume of data generated by modern scientific simulations and instruments. Nevertheless, assessing data quality post-compression remains computationally expensive due to the intensive nature of metric calculations. In this work, we present a general-purpose deep-surrogate framework for lossy compression quality prediction (DeepCQ), with the following key contributions: 1) We develop a surrogate model for compression quality prediction that is generalizable to different error-bounded lossy compressors, quality metrics, and input datasets; 2) We adopt a novel two-stage design that decouples the computationally expensive feature-extraction stage from the light-weight metrics prediction, enabling efficient training and modular inference; 3) We optimize the model performance on time-evolving data using a mixture-of-experts design. Such a design enhances the robustness when predicting across simulation timesteps, especially when the training and test data exhibit significant variation. We validate the effectiveness of DeepCQ on four real-world scientific applications. Our results highlight the framework's exceptional predictive accuracy, with prediction errors generally under 10\% across most settings, significantly outperforming existing methods. Our framework empowers scientific users to make informed decisions about data compression based on their preferred data quality, thereby significantly reducing I/O and computational overhead in scientific data analysis.
AdaParse: An Adaptive Parallel PDF Parsing and Resource Scaling Engine
Apr 23, 2025Language models for scientific tasks are trained on text from scientific publications, most distributed as PDFs that require parsing. PDF parsing approaches range from inexpensive heuristics (for simple documents) to computationally intensive ML-driven systems (for complex or degraded ones). The choice of the "best" parser for a particular document depends on its computational cost and the accuracy of its output. To address these issues, we introduce an Adaptive Parallel PDF Parsing and Resource Scaling Engine (AdaParse), a data-driven strategy for assigning an appropriate parser to each document. We enlist scientists to select preferred parser outputs and incorporate this information through direct preference optimization (DPO) into AdaParse, thereby aligning its selection process with human judgment. AdaParse then incorporates hardware requirements and predicted accuracy of each parser to orchestrate computational resources efficiently for large-scale parsing campaigns. We demonstrate that AdaParse, when compared to state-of-the-art parsers, improves throughput by $17\times$ while still achieving comparable accuracy (0.2 percent better) on a benchmark set of 1000 scientific documents. AdaParse's combination of high accuracy and parallel scalability makes it feasible to parse large-scale scientific document corpora to support the development of high-quality, trillion-token-scale text datasets. The implementation is available at https://github.com/7shoe/AdaParse/
EAIRA: Establishing a Methodology for Evaluating AI Models as Scientific Research Assistants
Feb 27, 2025Recent advancements have positioned AI, and particularly Large Language Models (LLMs), as transformative tools for scientific research, capable of addressing complex tasks that require reasoning, problem-solving, and decision-making. Their exceptional capabilities suggest their potential as scientific research assistants but also highlight the need for holistic, rigorous, and domain-specific evaluation to assess effectiveness in real-world scientific applications. This paper describes a multifaceted methodology for Evaluating AI models as scientific Research Assistants (EAIRA) developed at Argonne National Laboratory. This methodology incorporates four primary classes of evaluations. 1) Multiple Choice Questions to assess factual recall; 2) Open Response to evaluate advanced reasoning and problem-solving skills; 3) Lab-Style Experiments involving detailed analysis of capabilities as research assistants in controlled environments; and 4) Field-Style Experiments to capture researcher-LLM interactions at scale in a wide range of scientific domains and applications. These complementary methods enable a comprehensive analysis of LLM strengths and weaknesses with respect to their scientific knowledge, reasoning abilities, and adaptability. Recognizing the rapid pace of LLM advancements, we designed the methodology to evolve and adapt so as to ensure its continued relevance and applicability. This paper describes the methodology state at the end of February 2025. Although developed within a subset of scientific domains, the methodology is designed to be generalizable to a wide range of scientific domains.
LSHBloom: Memory-efficient, Extreme-scale Document Deduplication
Nov 06, 2024Deduplication is a major focus for assembling and curating training datasets for large language models (LLM) -- detecting and eliminating additional instances of the same content -- in large collections of technical documents. Unrestrained, duplicates in the training dataset increase training costs and lead to undesirable properties such as memorization in trained models or cheating on evaluation. Contemporary approaches to document-level deduplication are often extremely expensive in both runtime and memory. We propose LSHBloom, an extension to MinhashLSH, which replaces the expensive LSHIndex with lightweight Bloom filters. LSHBloom demonstrates the same deduplication performance as MinhashLSH with only a marginal increase in false positives (as low as 1e-5 in our experiments); demonstrates competitive runtime (270\% faster than MinhashLSH on peS2o); and, crucially, uses just 0.6\% of the disk space required by MinhashLSH to deduplicate peS2o. We demonstrate that this space advantage scales with increased dataset size -- at the extreme scale of several billion documents, LSHBloom promises a 250\% speedup and a 54$\times$ space advantage over traditional MinHashLSH scaling deduplication of text datasets to many billions of documents.
DataStates-LLM: Lazy Asynchronous Checkpointing for Large Language Models
Jun 15, 2024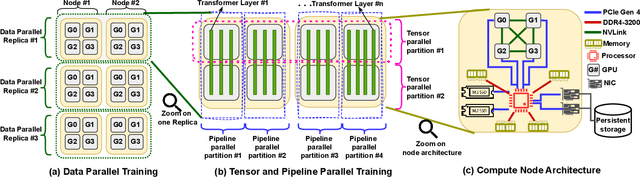

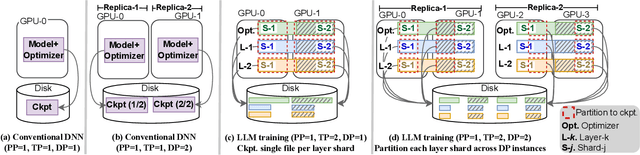
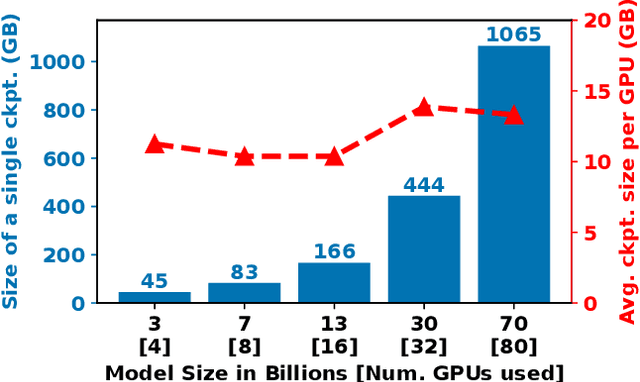
LLMs have seen rapid adoption in all domains. They need to be trained on high-end high-performance computing (HPC) infrastructures and ingest massive amounts of input data. Unsurprisingly, at such a large scale, unexpected events (e.g., failures of components, instability of the software, undesirable learning patterns, etc.), are frequent and typically impact the training in a negative fashion. Thus, LLMs need to be checkpointed frequently so that they can be rolled back to a stable state and subsequently fine-tuned. However, given the large sizes of LLMs, a straightforward checkpointing solution that directly writes the model parameters and optimizer state to persistent storage (e.g., a parallel file system), incurs significant I/O overheads. To address this challenge, in this paper we study how to reduce the I/O overheads for enabling fast and scalable checkpointing for LLMs that can be applied at high frequency (up to the granularity of individual iterations) without significant impact on the training process. Specifically, we introduce a lazy asynchronous multi-level approach that takes advantage of the fact that the tensors making up the model and optimizer state shards remain immutable for extended periods of time, which makes it possible to copy their content in the background with minimal interference during the training process. We evaluate our approach at scales of up to 180 GPUs using different model sizes, parallelism settings, and checkpointing frequencies. The results show up to 48$\times$ faster checkpointing and 2.2$\times$ faster end-to-end training runtime compared with the state-of-art checkpointing approaches.
Understanding The Effectiveness of Lossy Compression in Machine Learning Training Sets
Mar 23, 2024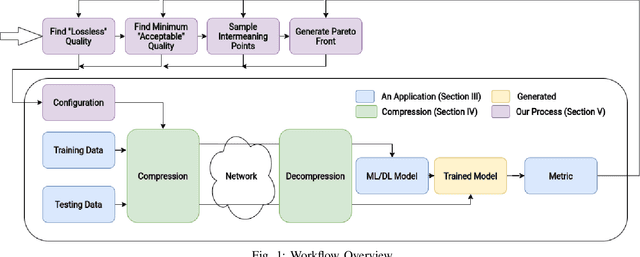
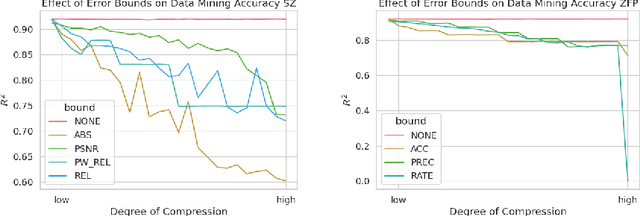
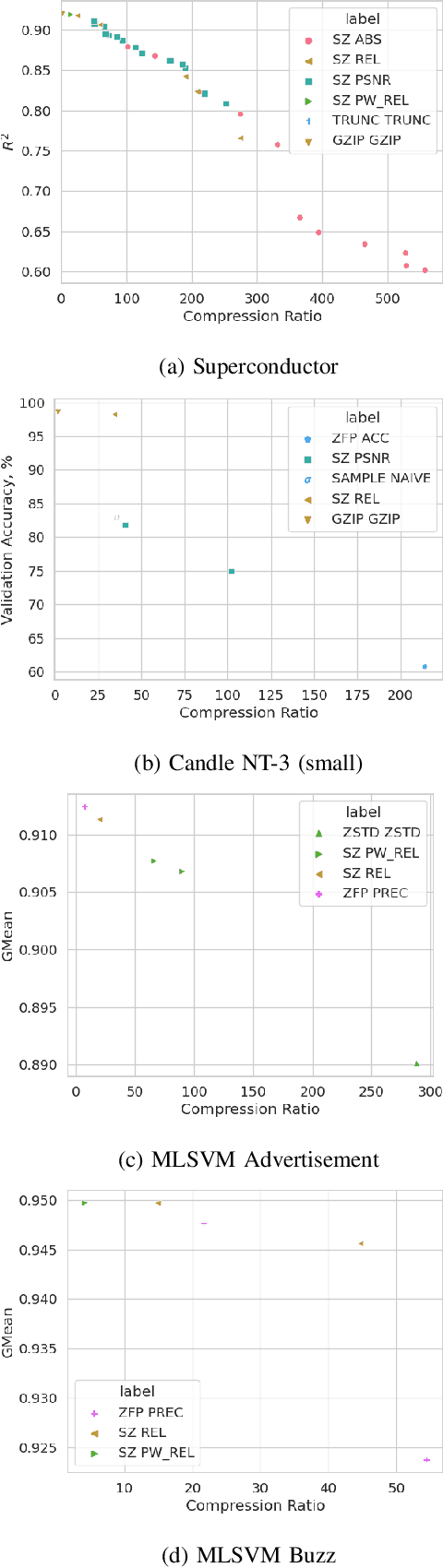
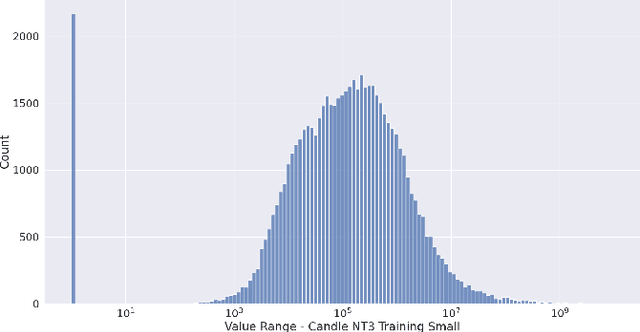
Learning and Artificial Intelligence (ML/AI) techniques have become increasingly prevalent in high performance computing (HPC). However, these methods depend on vast volumes of floating point data for training and validation which need methods to share the data on a wide area network (WAN) or to transfer it from edge devices to data centers. Data compression can be a solution to these problems, but an in-depth understanding of how lossy compression affects model quality is needed. Prior work largely considers a single application or compression method. We designed a systematic methodology for evaluating data reduction techniques for ML/AI, and we use it to perform a very comprehensive evaluation with 17 data reduction methods on 7 ML/AI applications to show modern lossy compression methods can achieve a 50-100x compression ratio improvement for a 1% or less loss in quality. We identify critical insights that guide the future use and design of lossy compressors for ML/AI.
Understanding Patterns of Deep Learning ModelEvolution in Network Architecture Search
Sep 22, 2023Network Architecture Search and specifically Regularized Evolution is a common way to refine the structure of a deep learning model.However, little is known about how models empirically evolve over time which has design implications for designing caching policies, refining the search algorithm for particular applications, and other important use cases.In this work, we algorithmically analyze and quantitatively characterize the patterns of model evolution for a set of models from the Candle project and the Nasbench-201 search space.We show how the evolution of the model structure is influenced by the regularized evolution algorithm. We describe how evolutionary patterns appear in distributed settings and opportunities for caching and improved scheduling. Lastly, we describe the conditions that affect when particular model architectures rise and fall in popularity based on their frequency of acting as a donor in a sliding window.