 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Assistants to Enhance and Exploit the PETSc Knowledge Base
Jun 25, 2025Generative AI, especially through large language models (LLMs), is transforming how technical knowledge can be accessed, reused, and extended. PETSc, a widely used numerical library for high-performance scientific computing, has accumulated a rich but fragmented knowledge base over its three decades of development, spanning source code, documentation, mailing lists, GitLab issues, Discord conversations, technical papers, and more. Much of this knowledge remains informal and inaccessible to users and new developers. To activate and utilize this knowledge base more effectively, the PETSc team has begun building an LLM-powered system that combines PETSc content with custom LLM tools -- including retrieval-augmented generation (RAG), reranking algorithms, and chatbots -- to assist users, support developers, and propose updates to formal documentation. This paper presents initial experiences designing and evaluating these tools, focusing on system architecture, using RAG and reranking for PETSc-specific information, evaluation methodologies for various LLMs and embedding models, and user interface design. Leveraging the Argonne Leadership Computing Facility resources, we analyze how LLM responses can enhance the development and use of numerical software, with an initial focus on scalable Krylov solvers. Our goal is to establish an extensible framework for knowledge-centered AI in scientific software, enabling scalable support, enriched documentation, and enhanced workflows for research and development. We conclude by outlining directions for expanding this system into a robust, evolving platform that advances software ecosystems to accelerate scientific discovery.
EAIRA: Establishing a Methodology for Evaluating AI Models as Scientific Research Assistants
Feb 27, 2025Recent advancements have positioned AI, and particularly Large Language Models (LLMs), as transformative tools for scientific research, capable of addressing complex tasks that require reasoning, problem-solving, and decision-making. Their exceptional capabilities suggest their potential as scientific research assistants but also highlight the need for holistic, rigorous, and domain-specific evaluation to assess effectiveness in real-world scientific applications. This paper describes a multifaceted methodology for Evaluating AI models as scientific Research Assistants (EAIRA) developed at Argonne National Laboratory. This methodology incorporates four primary classes of evaluations. 1) Multiple Choice Questions to assess factual recall; 2) Open Response to evaluate advanced reasoning and problem-solving skills; 3) Lab-Style Experiments involving detailed analysis of capabilities as research assistants in controlled environments; and 4) Field-Style Experiments to capture researcher-LLM interactions at scale in a wide range of scientific domains and applications. These complementary methods enable a comprehensive analysis of LLM strengths and weaknesses with respect to their scientific knowledge, reasoning abilities, and adaptability. Recognizing the rapid pace of LLM advancements, we designed the methodology to evolve and adapt so as to ensure its continued relevance and applicability. This paper describes the methodology state at the end of February 2025. Although developed within a subset of scientific domains, the methodology is designed to be generalizable to a wide range of scientific domains.
Scaling Distributed Training of Flood-Filling Networks on HPC Infrastructure for Brain Mapping
May 13, 2019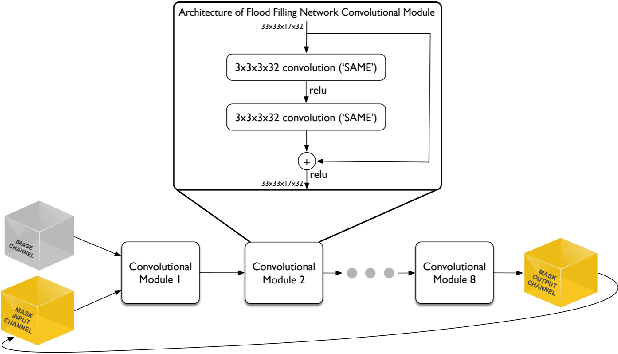

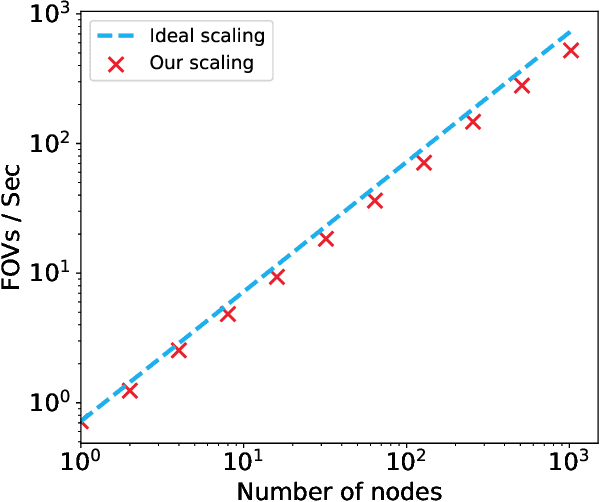
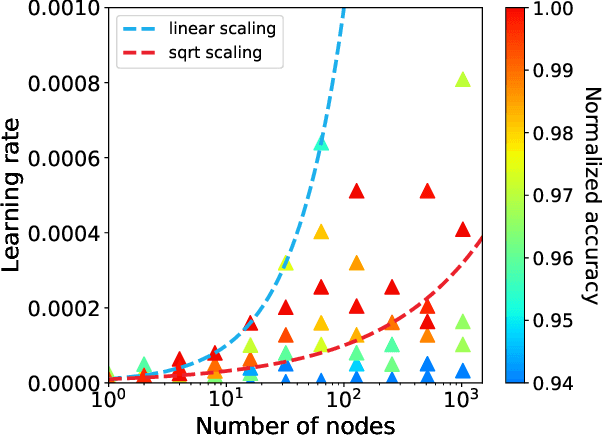
Mapping all the neurons in the brain requires automatic reconstruction of entire cells from volume electron microscopy data. The flood-filling networks (FFN) architecture can achieve leading performance. However, the training of the network is computationally very expensive. In order to reduce the training time, we implemented synchronous and data-parallel distributed training using the Horovod framework on top of the published FFN code. We demonstrated the scaling of FFN training up to 1024 Intel Knights Landing (KNL) nodes at Argonne Leadership Computing Facility. We investigated the training accuracy with different optimizers, learning rates, and optional warm-up periods. We discovered that square root scaling for learning rate works best beyond 16 nodes, which is contrary to the case of smaller number of nodes, where linear learning rate scaling with warm-up performs the best. Our distributed training reaches 95% accuracy in approximately 4.5 hours on 1024 KNL nodes using Adam optimizer.