 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Discovery in Natural Science Laboratories with AI and Robotics: Perspectives and Challenges from the 2024 IEEE ICRA Workshop, Yokohama, Japan
Jan 12, 2025
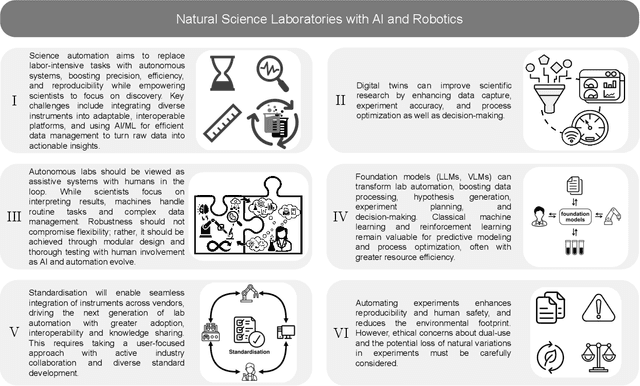
Science laboratory automation enables accelerated discovery in life sciences and materials. However, it requires interdisciplinary collaboration to address challenges such as robust and flexible autonomy, reproducibility, throughput, standardization, the role of human scientists, and ethics. This article highlights these issues, reflecting perspectives from leading experts in laboratory automation across different disciplines of the natural sciences.
Linking the Dynamic PicoProbe Analytical Electron-Optical Beam Line / Microscope to Supercomputers
Aug 25, 2023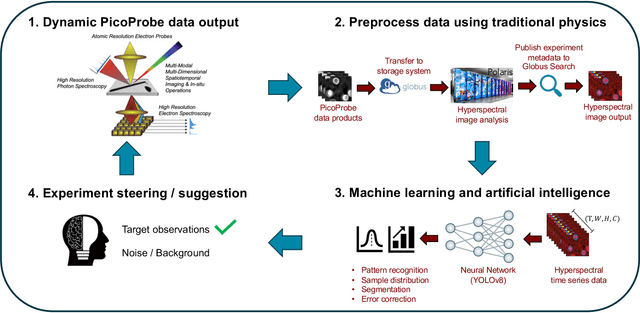
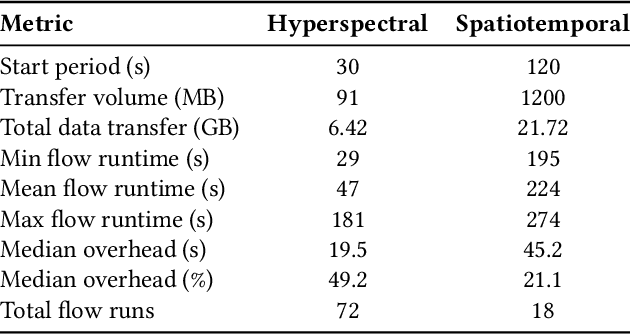
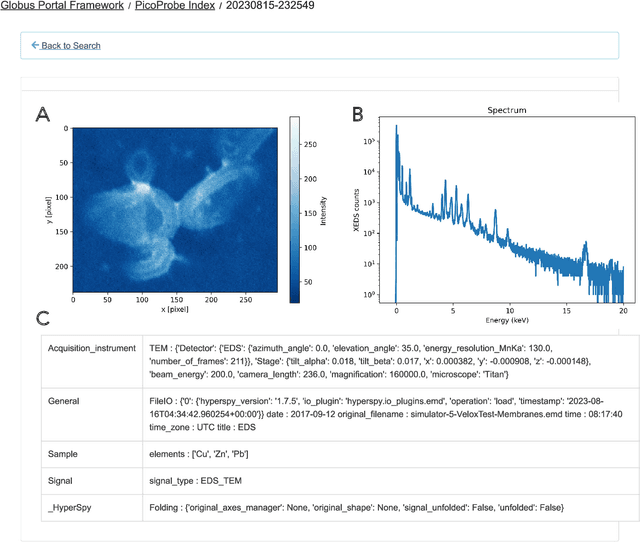
The Dynamic PicoProbe at Argonne National Laboratory is undergoing upgrades that will enable it to produce up to 100s of GB of data per day. While this data is highly important for both fundamental science and industrial applications, there is currently limited on-site infrastructure to handle these high-volume data streams. We address this problem by providing a software architecture capable of supporting large-scale data transfers to the neighboring supercomputers at the Argonne Leadership Computing Facility. To prepare for future scientific workflows, we implement two instructive use cases for hyperspectral and spatiotemporal datasets, which include: (i) off-site data transfer, (ii) machine learning/artificial intelligence and traditional data analysis approaches, and (iii) automatic metadata extraction and cataloging of experimental results. This infrastructure supports expected workloads and also provides domain scientists the ability to reinterrogate data from past experiments to yield additional scientific value and derive new insights.
Towards a Modular Architecture for Science Factories
Aug 18, 2023Advances in robotic automation, high-performance computing (HPC), and artificial intelligence (AI) encourage us to conceive of science factories: large, general-purpose computation- and AI-enabled self-driving laboratories (SDLs) with the generality and scale needed both to tackle large discovery problems and to support thousands of scientists. Science factories require modular hardware and software that can be replicated for scale and (re)configured to support many applications. To this end, we propose a prototype modular science factory architecture in which reconfigurable modules encapsulating scientific instruments are linked with manipulators to form workcells, that can themselves be combined to form larger assemblages, and linked with distributed computing for simulation, AI model training and inference, and related tasks. Workflows that perform sets of actions on modules can be specified, and various applications, comprising workflows plus associated computational and data manipulation steps, can be run concurrently. We report on our experiences prototyping this architecture and applying it in experiments involving 15 different robotic apparatus, five applications (one in education, two in biology, two in materials), and a variety of workflows, across four laboratories. We describe the reuse of modules, workcells, and workflows in different applications, the migration of applications between workcells, and the use of digital twins, and suggest directions for future work aimed at yet more generality and scalability. Code and data are available at https://ad-sdl.github.io/wei2023 and in the Supplementary Information
Scaling Distributed Training of Flood-Filling Networks on HPC Infrastructure for Brain Mapping
May 13, 2019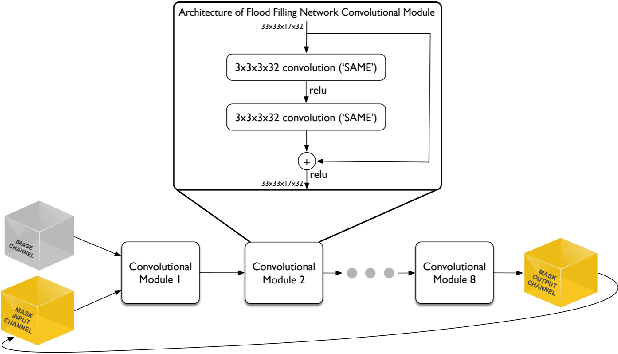

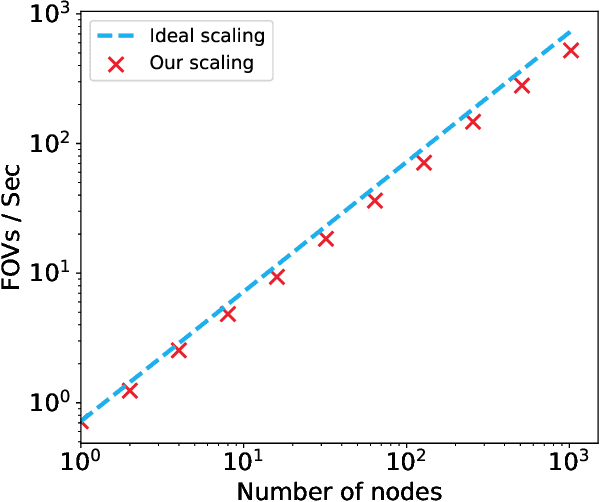
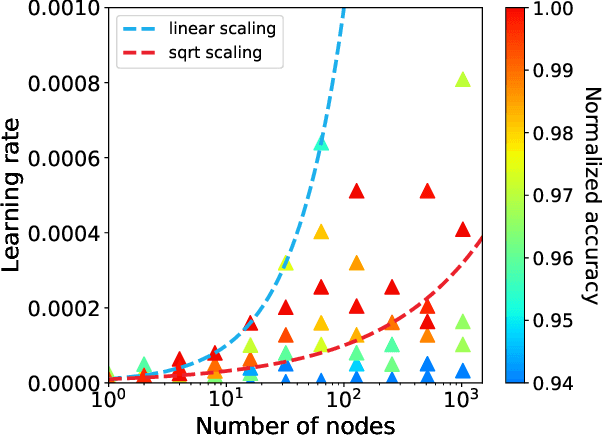
Mapping all the neurons in the brain requires automatic reconstruction of entire cells from volume electron microscopy data. The flood-filling networks (FFN) architecture can achieve leading performance. However, the training of the network is computationally very expensive. In order to reduce the training time, we implemented synchronous and data-parallel distributed training using the Horovod framework on top of the published FFN code. We demonstrated the scaling of FFN training up to 1024 Intel Knights Landing (KNL) nodes at Argonne Leadership Computing Facility. We investigated the training accuracy with different optimizers, learning rates, and optional warm-up periods. We discovered that square root scaling for learning rate works best beyond 16 nodes, which is contrary to the case of smaller number of nodes, where linear learning rate scaling with warm-up performs the best. Our distributed training reaches 95% accuracy in approximately 4.5 hours on 1024 KNL nodes using Adam optimizer.
Quantifying mesoscale neuroanatomy using X-ray microtomography
Jul 26, 2016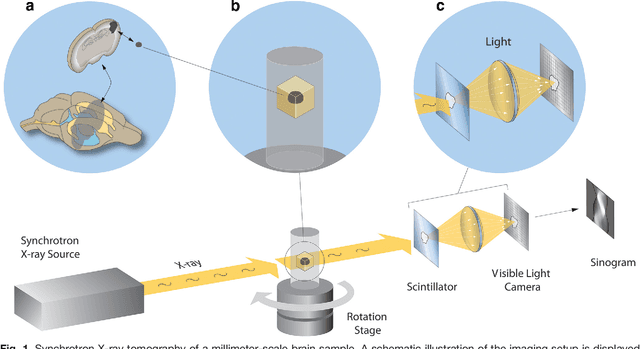
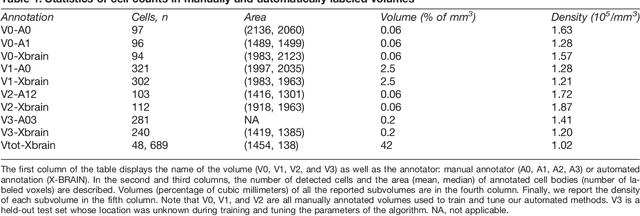
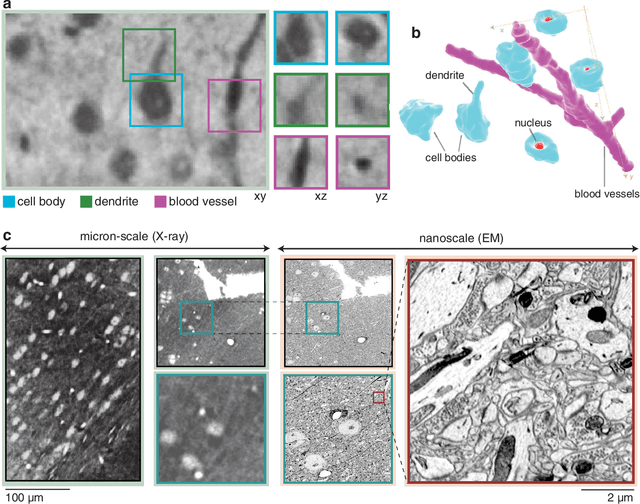
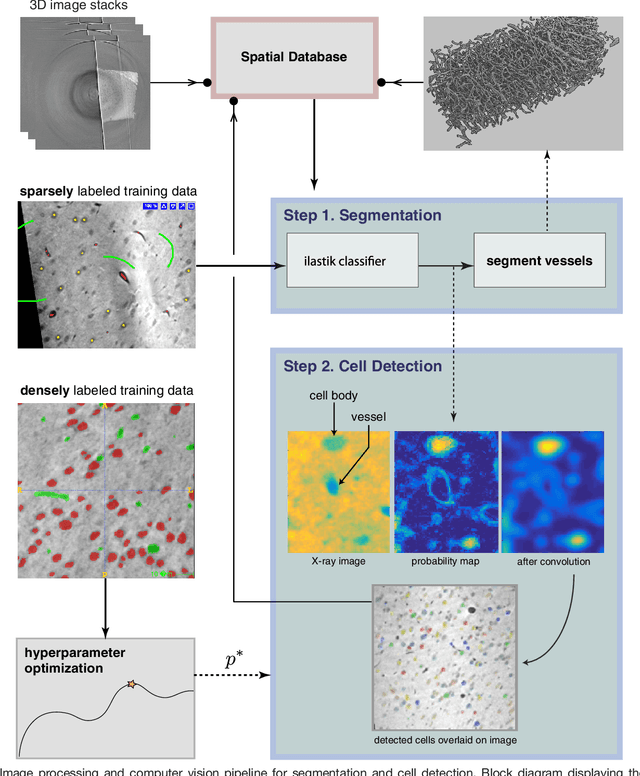
Methods for resolving the 3D microstructure of the brain typically start by thinly slicing and staining the brain, and then imaging each individual section with visible light photons or electrons. In contrast, X-rays can be used to image thick samples, providing a rapid approach for producing large 3D brain maps without sectioning. Here we demonstrate the use of synchrotron X-ray microtomography ($\mu$CT) for producing mesoscale $(1~\mu m^3)$ resolution brain maps from millimeter-scale volumes of mouse brain. We introduce a pipeline for $\mu$CT-based brain mapping that combines methods for sample preparation, imaging, automated segmentation of image volumes into cells and blood vessels, and statistical analysis of the resulting brain structures. Our results demonstrate that X-ray tomography promises rapid quantification of large brain volumes, complementing other brain mapping and connectomics efforts.