 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Distributed Training of Flood-Filling Networks on HPC Infrastructure for Brain Mapping
Paper and Code
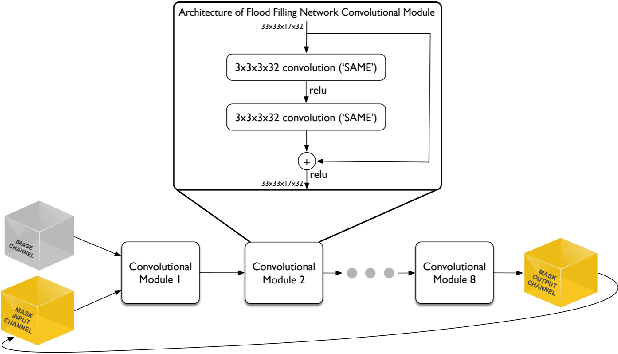

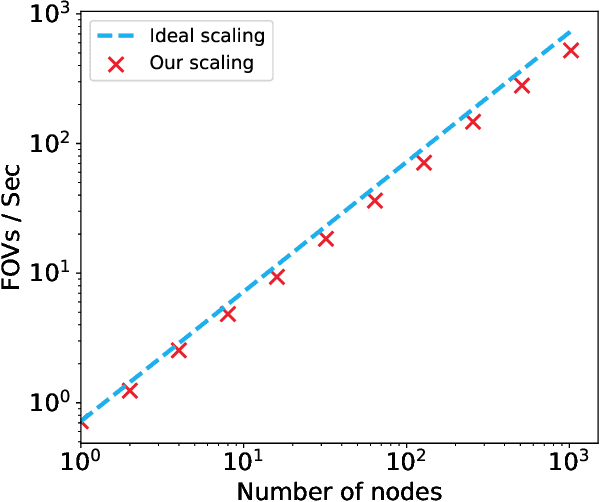
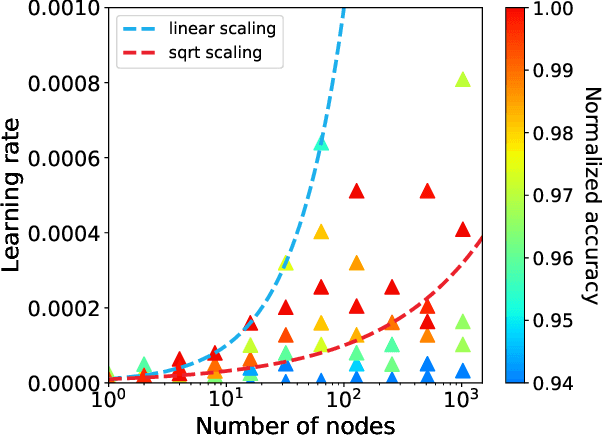
Mapping all the neurons in the brain requires automatic reconstruction of entire cells from volume electron microscopy data. The flood-filling networks (FFN) architecture can achieve leading performance. However, the training of the network is computationally very expensive. In order to reduce the training time, we implemented synchronous and data-parallel distributed training using the Horovod framework on top of the published FFN code. We demonstrated the scaling of FFN training up to 1024 Intel Knights Landing (KNL) nodes at Argonne Leadership Computing Facility. We investigated the training accuracy with different optimizers, learning rates, and optional warm-up periods. We discovered that square root scaling for learning rate works best beyond 16 nodes, which is contrary to the case of smaller number of nodes, where linear learning rate scaling with warm-up performs the best. Our distributed training reaches 95% accuracy in approximately 4.5 hours on 1024 KNL nodes using Adam optimizer.