 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Industrial Crash Dynamics Prediction via Geometry-Aware Operator Learning with Memory-Efficient Low-Rank Attention
May 26, 2026Automotive crashworthiness optimization remains a safety-critical challenge, requiring the management of large-scale nonlinear structural deformations and energy dissipation through iterative, high-fidelity simulations. While traditional finite element solvers are computationally prohibitive, emerging operator learning frameworks provide rapid surrogate predictions; however, applying them to industrial-scale crash analysis, where complex geometry, contact nonlinearities, and rapidly evolving transient deformation coexist, remains an open challenge. In this paper, we demonstrate that the GeoTransolver framework provides a viable solution for accurate, high-fidelity crash dynamics prediction at industrial scale. Benchmarked on complex bumper beam and full-vehicle crash datasets, GeoTransolver captures multi-scale geometric context and accurately resolves plastic deformation patterns as well as acceleration profiles at critical occupant locations. Beyond the architecture itself, we propose and systematically evaluate a suite of temporal prediction recipes, including one-shot, time-conditional, and autoregressive rollout strategies, demonstrating that the one-shot approach achieves state-of-the-art accuracy with significantly reduced training overhead and inference latency. As a secondary contribution, we introduce a Fast Low-rank Attention Routing Engine (FLARE)-based modification to the GeoTransolver attention backbone that reduces memory overhead by approximately 2x while further improving predictive accuracy for O(N) long-range, high-frequency transients, preserving the geometry-aware cross-attention strengths of the base framework. Our results highlight the practical viability of geometry-aware operator learning for high-fidelity surrogate modeling of complex, safety-critical automotive dynamics.
HiLiftAeroML: High-Fidelity Computational Fluid Dynamics Dataset for High-Lift Aircraft Aerodynamics
May 19, 2026This paper describes the first-ever open-source high-fidelity CFD dataset of a high-lift aircraft for the purpose of AI surrogate model development. The dataset is composed of 1800 samples, arising from 180 geometry variants and 10 angles of attack for the high-lift NASA Common Research Model (CRM) geometry, used within the AIAA High-Lift Prediction Workshop series. One of the novelties of this dataset is the use of a GPU-accelerated high-fidelity explicit, wall-modeled LES approach for each simulation, using solution-adapted grids between 300M and 500M cells. This ensures the greatest possible accuracy given known challenges in steady-state RANS approaches for these portions of the flight envelope. The entire dataset (geometries, time-averaged volume and surface variables and integral forces) are available, free of charge with a permissive open-source license (CC-BY-4.0). By making this data publicly available, we aim to accelerate the research and development of AI surrogate modeling within the aerospace industry.
GeoTransolver: Learning Physics on Irregular Domains Using Multi-scale Geometry Aware Physics Attention Transformer
Dec 24, 2025We present GeoTransolver, a Multiscale Geometry-Aware Physics Attention Transformer for CAE that replaces standard attention with GALE, coupling physics-aware self-attention on learned state slices with cross-attention to a shared geometry/global/boundary-condition context computed from multi-scale ball queries (inspired by DoMINO) and reused in every block. Implemented and released in NVIDIA PhysicsNeMo, GeoTransolver persistently projects geometry, global and boundary condition parameters into physical state spaces to anchor latent computations to domain structure and operating regimes. We benchmark GeoTransolver on DrivAerML, Luminary SHIFT-SUV, and Luminary SHIFT-Wing, comparing against Domino, Transolver (as released in PhysicsNeMo), and literature-reported AB-UPT, and evaluate drag/lift R2 and Relative L1 errors for field variables. GeoTransolver delivers better accuracy, improved robustness to geometry/regime shifts, and favorable data efficiency; we include ablations on DrivAerML and qualitative results such as contour plots and design trends for the best GeoTransolver models. By unifying multiscale geometry-aware context with physics-based attention in a scalable transformer, GeoTransolver advances operator learning for high-fidelity surrogate modeling across complex, irregular domains and non-linear physical regimes.
PILArNet: Public Dataset for Particle Imaging Liquid Argon Detectors in High Energy Physics
Jun 03, 2020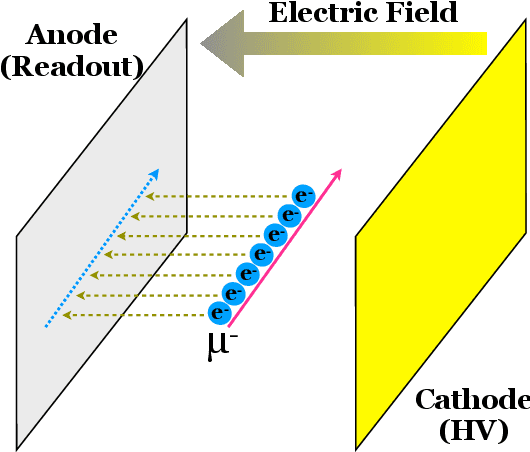
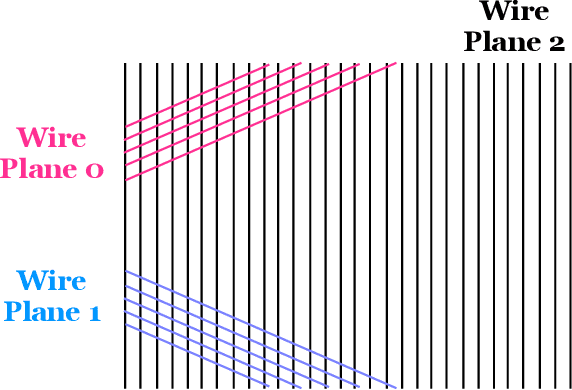

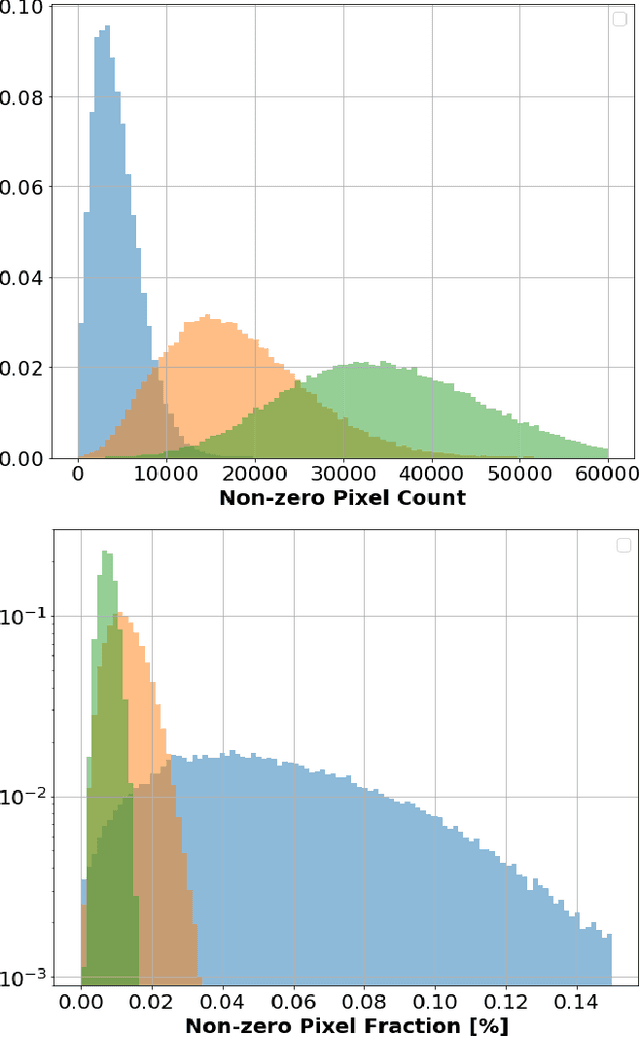
Rapid advancement of machine learning solutions has often coincided with the production of a test public data set. Such datasets reduce the largest barrier to entry for tackling a problem -- procuring data -- while also providing a benchmark to compare different solutions. Furthermore, large datasets have been used to train high-performing feature finders which are then used in new approaches to problems beyond that initially defined. In order to encourage the rapid development in the analysis of data collected using liquid argon time projection chambers, a class of particle detectors used in high energy physics experiments, we have produced the PILArNet, first 2D and 3D open dataset to be used for a couple of key analysis tasks. The initial dataset presented in this paper contains 300,000 samples simulated and recorded in three different volume sizes. The dataset is stored efficiently in sparse 2D and 3D matrix format with auxiliary information about simulated particles in the volume, and is made available for public research use. In this paper we describe the dataset, tasks, and the method used to procure the sample.
Scaling Distributed Training of Flood-Filling Networks on HPC Infrastructure for Brain Mapping
May 13, 2019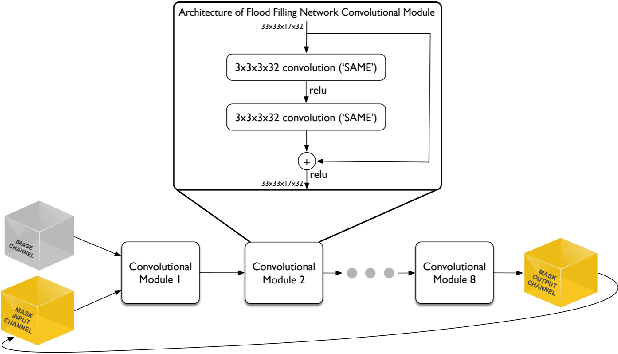

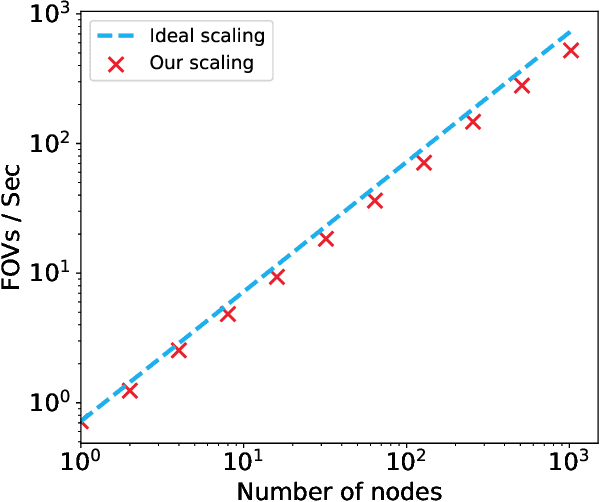
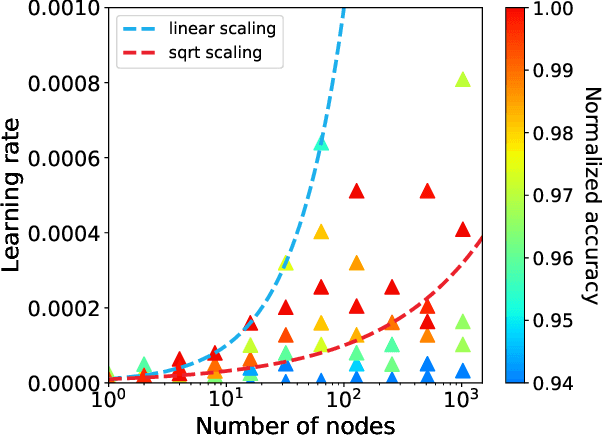
Mapping all the neurons in the brain requires automatic reconstruction of entire cells from volume electron microscopy data. The flood-filling networks (FFN) architecture can achieve leading performance. However, the training of the network is computationally very expensive. In order to reduce the training time, we implemented synchronous and data-parallel distributed training using the Horovod framework on top of the published FFN code. We demonstrated the scaling of FFN training up to 1024 Intel Knights Landing (KNL) nodes at Argonne Leadership Computing Facility. We investigated the training accuracy with different optimizers, learning rates, and optional warm-up periods. We discovered that square root scaling for learning rate works best beyond 16 nodes, which is contrary to the case of smaller number of nodes, where linear learning rate scaling with warm-up performs the best. Our distributed training reaches 95% accuracy in approximately 4.5 hours on 1024 KNL nodes using Adam optimizer.