 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILArNet: Public Dataset for Particle Imaging Liquid Argon Detectors in High Energy Physics
Jun 03, 2020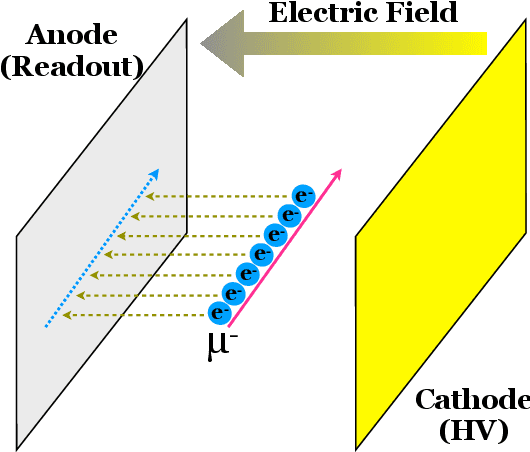
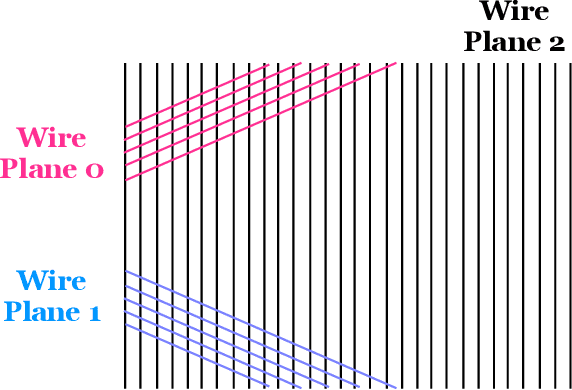

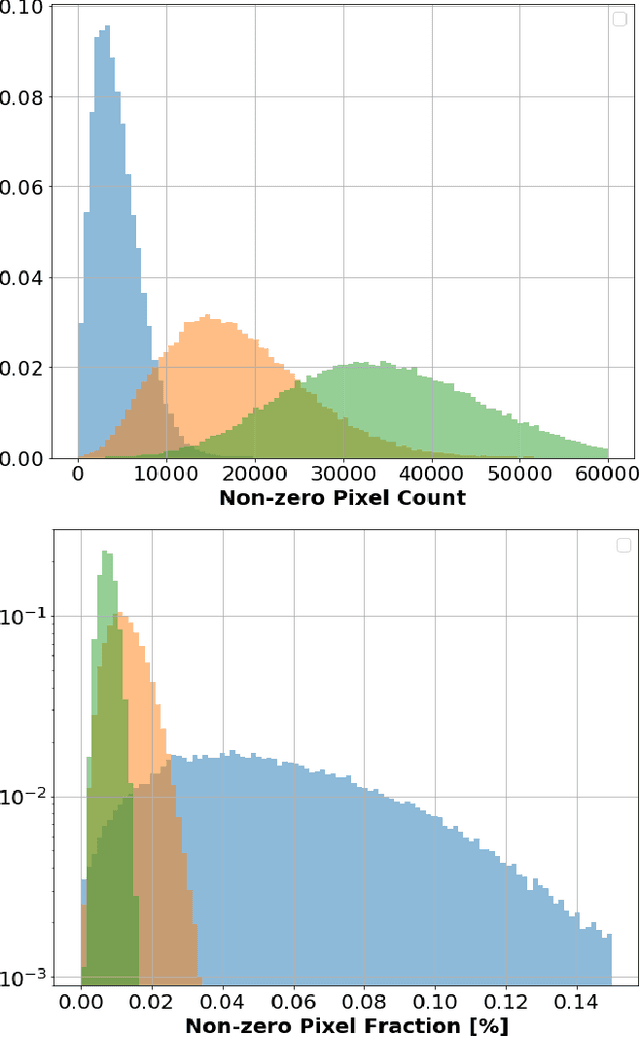
Rapid advancement of machine learning solutions has often coincided with the production of a test public data set. Such datasets reduce the largest barrier to entry for tackling a problem -- procuring data -- while also providing a benchmark to compare different solutions. Furthermore, large datasets have been used to train high-performing feature finders which are then used in new approaches to problems beyond that initially defined. In order to encourage the rapid development in the analysis of data collected using liquid argon time projection chambers, a class of particle detectors used in high energy physics experiments, we have produced the PILArNet, first 2D and 3D open dataset to be used for a couple of key analysis tasks. The initial dataset presented in this paper contains 300,000 samples simulated and recorded in three different volume sizes. The dataset is stored efficiently in sparse 2D and 3D matrix format with auxiliary information about simulated particles in the volume, and is made available for public research use. In this paper we describe the dataset, tasks, and the method used to procure the sample.