 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking the Dynamic PicoProbe Analytical Electron-Optical Beam Line / Microscope to Supercomputers
Aug 25, 2023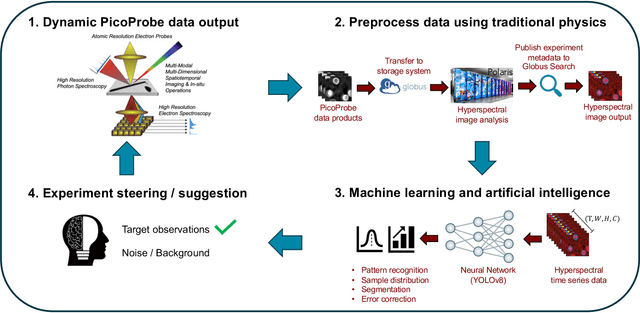
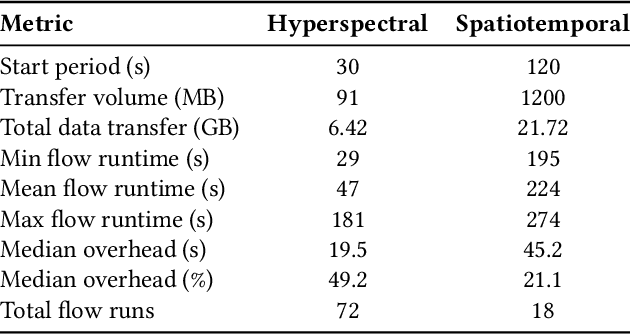
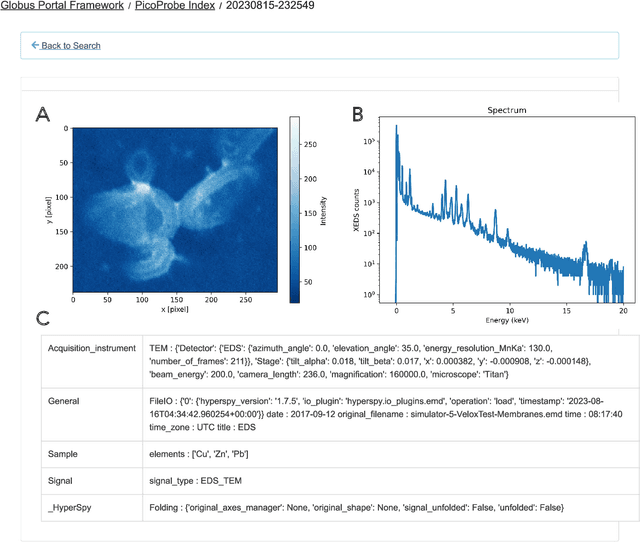
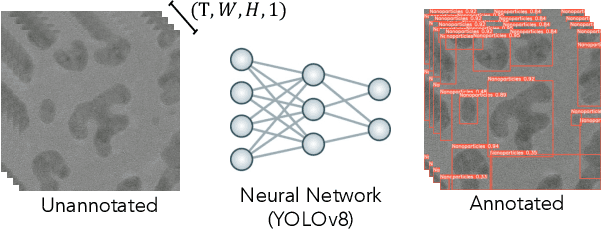
The Dynamic PicoProbe at Argonne National Laboratory is undergoing upgrades that will enable it to produce up to 100s of GB of data per day. While this data is highly important for both fundamental science and industrial applications, there is currently limited on-site infrastructure to handle these high-volume data streams. We address this problem by providing a software architecture capable of supporting large-scale data transfers to the neighboring supercomputers at the Argonne Leadership Computing Facility. To prepare for future scientific workflows, we implement two instructive use cases for hyperspectral and spatiotemporal datasets, which include: (i) off-site data transfer, (ii) machine learning/artificial intelligence and traditional data analysis approaches, and (iii) automatic metadata extraction and cataloging of experimental results. This infrastructure supports expected workloads and also provides domain scientists the ability to reinterrogate data from past experiments to yield additional scientific value and derive new insights.