 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlight: A FaaS-Based Framework for Complex and Hierarchical Federated Learning
Sep 24, 2024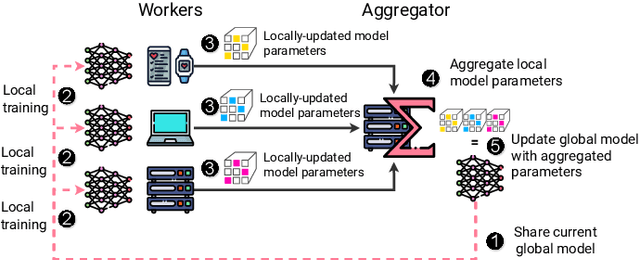

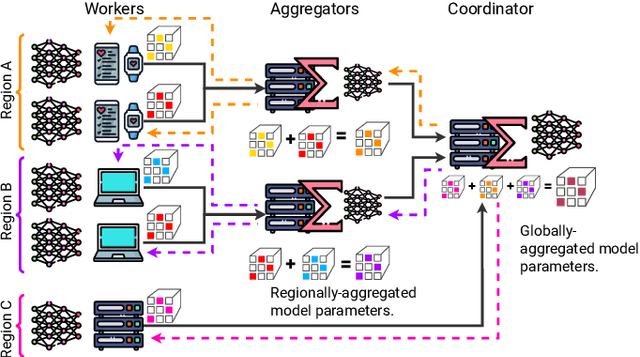
Federated Learning (FL) is a decentralized machine learning paradigm where models are trained on distributed devices and are aggregated at a central server. Existing FL frameworks assume simple two-tier network topologies where end devices are directly connected to the aggregation server. While this is a practical mental model, it does not exploit the inherent topology of real-world distributed systems like the Internet-of-Things. We present Flight, a novel FL framework that supports complex hierarchical multi-tier topologies, asynchronous aggregation, and decouples the control plane from the data plane. We compare the performance of Flight against Flower, a state-of-the-art FL framework. Our results show that Flight scales beyond Flower, supporting up to 2048 simultaneous devices, and reduces FL makespan across several models. Finally, we show that Flight's hierarchical FL model can reduce communication overheads by more than 60%.
Employing Artificial Intelligence to Steer Exascale Workflows with Colmena
Aug 26, 2024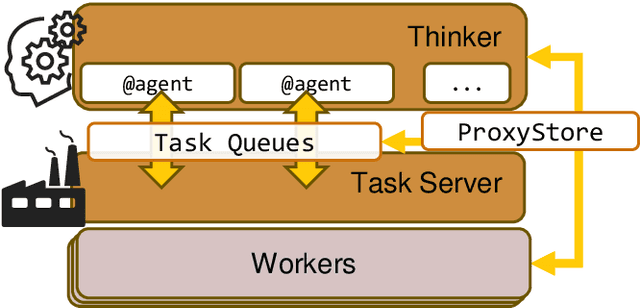
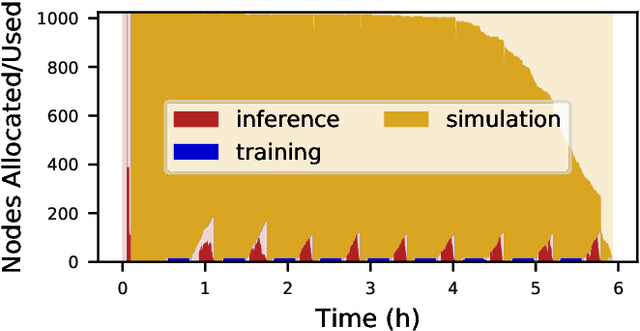
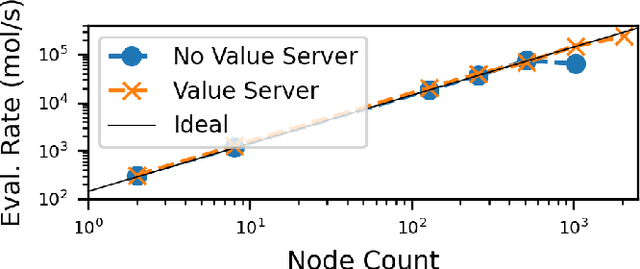
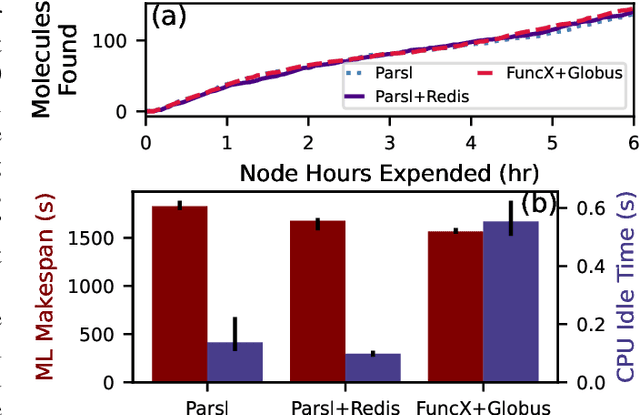
Computational workflows are a common class of application on supercomputers, yet the loosely coupled and heterogeneous nature of workflows often fails to take full advantage of their capabilities. We created Colmena to leverage the massive parallelism of a supercomputer by using Artificial Intelligence (AI) to learn from and adapt a workflow as it executes. Colmena allows scientists to define how their application should respond to events (e.g., task completion) as a series of cooperative agents. In this paper, we describe the design of Colmena, the challenges we overcame while deploying applications on exascale systems, and the science workflows we have enhanced through interweaving AI. The scaling challenges we discuss include developing steering strategies that maximize node utilization, introducing data fabrics that reduce communication overhead of data-intensive tasks, and implementing workflow tasks that cache costly operations between invocations. These innovations coupled with a variety of application patterns accessible through our agent-based steering model have enabled science advances in chemistry, biophysics, and materials science using different types of AI. Our vision is that Colmena will spur creative solutions that harness AI across many domains of scientific computing.
Trillion Parameter AI Serving Infrastructure for Scientific Discovery: A Survey and Vision
Feb 05, 2024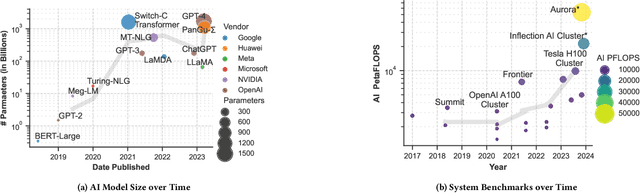
Deep learning methods are transforming research, enabling new techniques, and ultimately leading to new discoveries. As the demand for more capable AI models continues to grow, we are now entering an era of Trillion Parameter Models (TPM), or models with more than a trillion parameters -- such as Huawei's PanGu-$\Sigma$. We describe a vision for the ecosystem of TPM users and providers that caters to the specific needs of the scientific community. We then outline the significant technical challenges and open problems in system design for serving TPMs to enable scientific research and discovery. Specifically, we describe the requirements of a comprehensive software stack and interfaces to support the diverse and flexible requirements of researchers.
Linking the Dynamic PicoProbe Analytical Electron-Optical Beam Line / Microscope to Supercomputers
Aug 25, 2023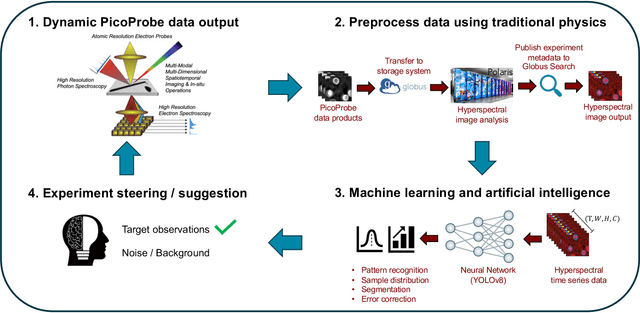
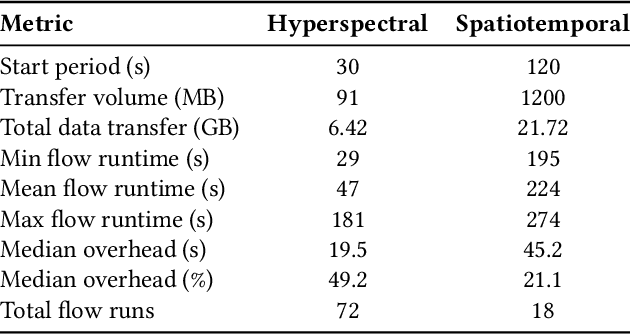
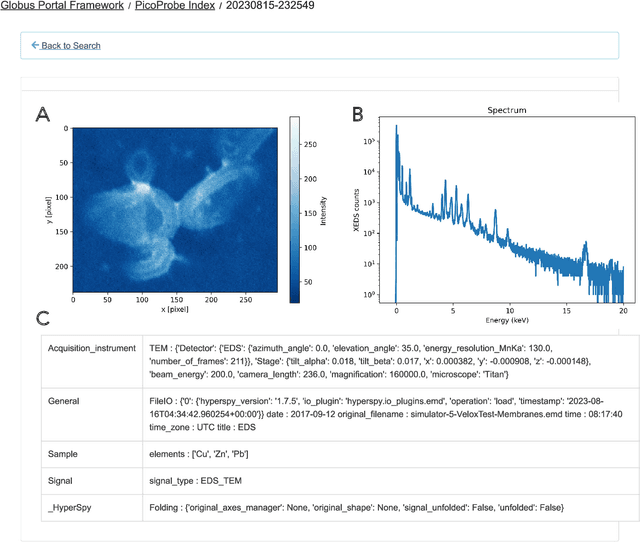
The Dynamic PicoProbe at Argonne National Laboratory is undergoing upgrades that will enable it to produce up to 100s of GB of data per day. While this data is highly important for both fundamental science and industrial applications, there is currently limited on-site infrastructure to handle these high-volume data streams. We address this problem by providing a software architecture capable of supporting large-scale data transfers to the neighboring supercomputers at the Argonne Leadership Computing Facility. To prepare for future scientific workflows, we implement two instructive use cases for hyperspectral and spatiotemporal datasets, which include: (i) off-site data transfer, (ii) machine learning/artificial intelligence and traditional data analysis approaches, and (iii) automatic metadata extraction and cataloging of experimental results. This infrastructure supports expected workloads and also provides domain scientists the ability to reinterrogate data from past experiments to yield additional scientific value and derive new insights.
APPFLx: Providing Privacy-Preserving Cross-Silo Federated Learning as a Service
Aug 17, 2023



Cross-silo privacy-preserving federated learning (PPFL) is a powerful tool to collaboratively train robust and generalized machine learning (ML) models without sharing sensitive (e.g., healthcare of financial) local data. To ease and accelerate the adoption of PPFL, we introduce APPFLx, a ready-to-use platform that provides privacy-preserving cross-silo federated learning as a service. APPFLx employs Globus authentication to allow users to easily and securely invite trustworthy collaborators for PPFL, implements several synchronous and asynchronous FL algorithms, streamlines the FL experiment launch process, and enables tracking and visualizing the life cycle of FL experiments, allowing domain experts and ML practitioners to easily orchestrate and evaluate cross-silo FL under one platform. APPFLx is available online at https://appflx.link
AI-assisted Automated Workflow for Real-time X-ray Ptychography Data Analysis via Federated Resources
Apr 09, 2023
We present an end-to-end automated workflow that uses large-scale remote compute resources and an embedded GPU platform at the edge to enable AI/ML-accelerated real-time analysis of data collected for x-ray ptychography. Ptychography is a lensless method that is being used to image samples through a simultaneous numerical inversion of a large number of diffraction patterns from adjacent overlapping scan positions. This acquisition method can enable nanoscale imaging with x-rays and electrons, but this often requires very large experimental datasets and commensurately high turnaround times, which can limit experimental capabilities such as real-time experimental steering and low-latency monitoring. In this work, we introduce a software system that can automate ptychography data analysis tasks. We accelerate the data analysis pipeline by using a modified version of PtychoNN -- an ML-based approach to solve phase retrieval problem that shows two orders of magnitude speedup compared to traditional iterative methods. Further, our system coordinates and overlaps different data analysis tasks to minimize synchronization overhead between different stages of the workflow. We evaluate our workflow system with real-world experimental workloads from the 26ID beamline at Advanced Photon Source and ThetaGPU cluster at Argonne Leadership Computing Resources.
Cloud Services Enable Efficient AI-Guided Simulation Workflows across Heterogeneous Resources
Mar 15, 2023Applications that fuse machine learning and simulation can benefit from the use of multiple computing resources, with, for example, simulation codes running on highly parallel supercomputers and AI training and inference tasks on specialized accelerators. Here, we present our experiences deploying two AI-guided simulation workflows across such heterogeneous systems. A unique aspect of our approach is our use of cloud-hosted management services to manage challenging aspects of cross-resource authentication and authorization, function-as-a-service (FaaS) function invocation, and data transfer. We show that these methods can achieve performance parity with systems that rely on direct connection between resources. We achieve parity by integrating the FaaS system and data transfer capabilities with a system that passes data by reference among managers and workers, and a user-configurable steering algorithm to hide data transfer latencies. We anticipate that this ease of use can enable routine use of heterogeneous resources in computational science.
OpenHLS: High-Level Synthesis for Low-Latency Deep Neural Networks for Experimental Science
Feb 15, 2023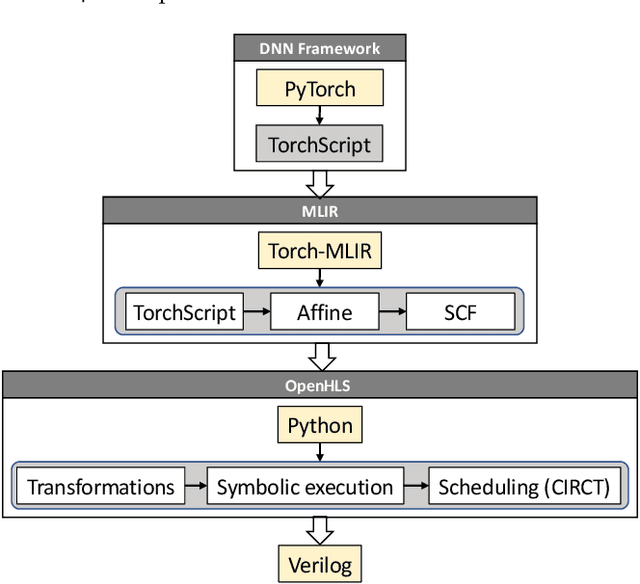

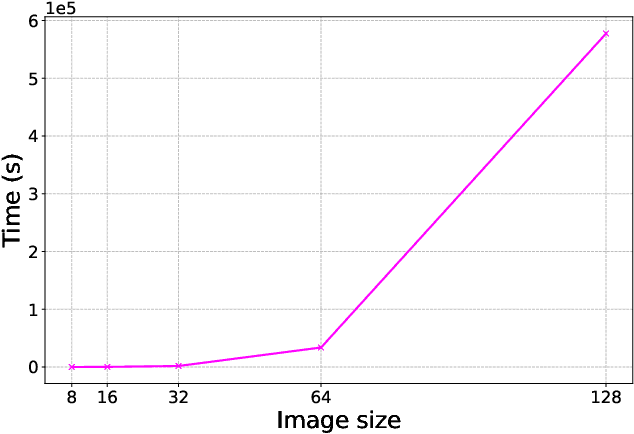

In many experiment-driven scientific domains, such as high-energy physics, material science, and cosmology, high data rate experiments impose hard constraints on data acquisition systems: collected data must either be indiscriminately stored for post-processing and analysis, thereby necessitating large storage capacity, or accurately filtered in real-time, thereby necessitating low-latency processing. Deep neural networks, effective in other filtering tasks, have not been widely employed in such data acquisition systems, due to design and deployment difficulties. We present an open source, lightweight, compiler framework, without any proprietary dependencies, OpenHLS, based on high-level synthesis techniques, for translating high-level representations of deep neural networks to low-level representations, suitable for deployment to near-sensor devices such as field-programmable gate arrays. We evaluate OpenHLS on various workloads and present a case-study implementation of a deep neural network for Bragg peak detection in the context of high-energy diffraction microscopy. We show OpenHLS is able to produce an implementation of the network with a throughput 4.8 $\mu$s/sample, which is approximately a 4$\times$ improvement over the existing implementation
Deep learning at the edge enables real-time streaming ptychographic imaging
Sep 20, 2022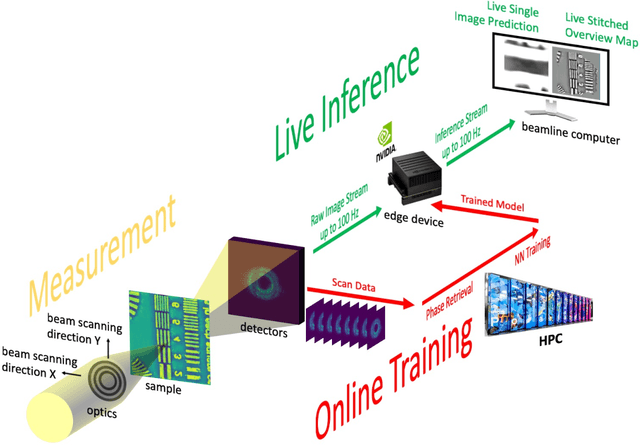
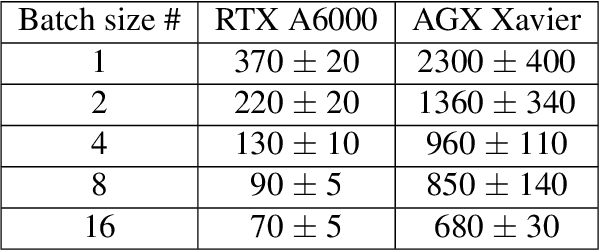
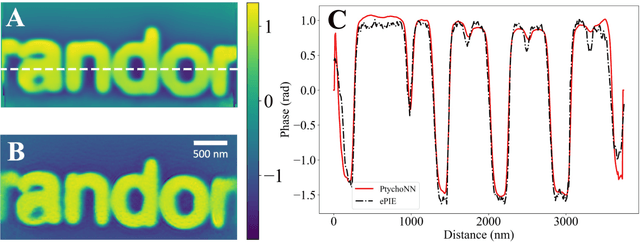

Coherent microscopy techniques provide an unparalleled multi-scale view of materials across scientific and technological fields, from structural materials to quantum devices, from integrated circuits to biological cells. Driven by the construction of brighter sources and high-rate detectors, coherent X-ray microscopy methods like ptychography are poised to revolutionize nanoscale materials characterization. However, associated significant increases in data and compute needs mean that conventional approaches no longer suffice for recovering sample images in real-time from high-speed coherent imaging experiments. Here, we demonstrate a workflow that leverages artificial intelligence at the edge and high-performance computing to enable real-time inversion on X-ray ptychography data streamed directly from a detector at up to 2 kHz. The proposed AI-enabled workflow eliminates the sampling constraints imposed by traditional ptychography, allowing low dose imaging using orders of magnitude less data than required by traditional methods.
Globus Automation Services: Research process automation across the space-time continuum
Aug 19, 2022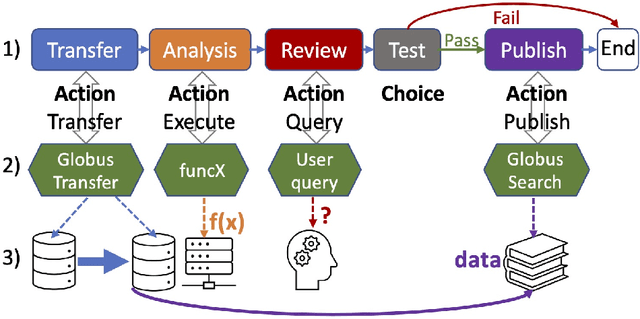
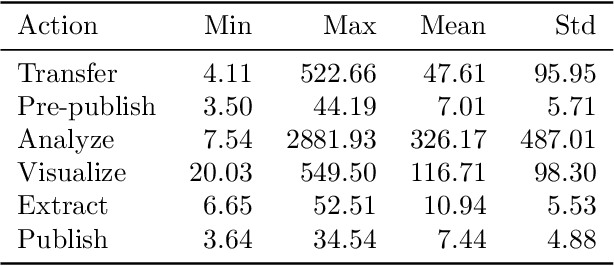
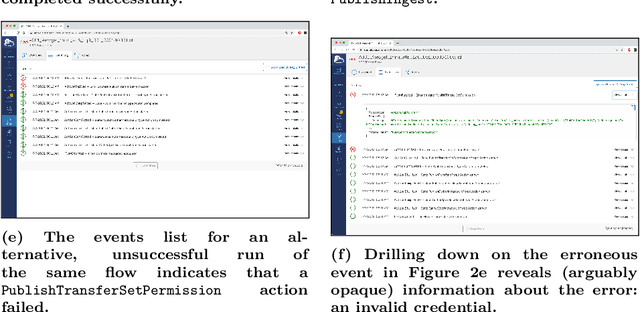
Research process automation--the reliable, efficient, and reproducible execution of linked sets of actions on scientific instruments, computers, data stores, and other resources--has emerged as an essential element of modern science. We report here on new services within the Globus research data management platform that enable the specification of diverse research processes as reusable sets of actions, flows, and the execution of such flows in heterogeneous research environments. To support flows with broad spatial extent (e.g., from scientific instrument to remote data center) and temporal extent (from seconds to weeks), these Globus automation services feature: 1) cloud hosting for reliable execution of even long-lived flows despite sporadic failures; 2) a declarative notation, and extensible asynchronous action provider API, for defining and executing a wide variety of actions and flow specifications involving arbitrary resources; 3) authorization delegation mechanisms for secure invocation of actions. These services permit researchers to outsource and automate the management of a broad range of research tasks to a reliable, scalable, and secure cloud platform. We present use cases for Globus automation services, describe the design and implementation of the services, present microbenchmark studies, and review experiences applying the services in a range of applications