 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-assisted Automated Workflow for Real-time X-ray Ptychography Data Analysis via Federated Resources
Apr 09, 2023
We present an end-to-end automated workflow that uses large-scale remote compute resources and an embedded GPU platform at the edge to enable AI/ML-accelerated real-time analysis of data collected for x-ray ptychography. Ptychography is a lensless method that is being used to image samples through a simultaneous numerical inversion of a large number of diffraction patterns from adjacent overlapping scan positions. This acquisition method can enable nanoscale imaging with x-rays and electrons, but this often requires very large experimental datasets and commensurately high turnaround times, which can limit experimental capabilities such as real-time experimental steering and low-latency monitoring. In this work, we introduce a software system that can automate ptychography data analysis tasks. We accelerate the data analysis pipeline by using a modified version of PtychoNN -- an ML-based approach to solve phase retrieval problem that shows two orders of magnitude speedup compared to traditional iterative methods. Further, our system coordinates and overlaps different data analysis tasks to minimize synchronization overhead between different stages of the workflow. We evaluate our workflow system with real-world experimental workloads from the 26ID beamline at Advanced Photon Source and ThetaGPU cluster at Argonne Leadership Computing Resources.
Deep learning at the edge enables real-time streaming ptychographic imaging
Sep 20, 2022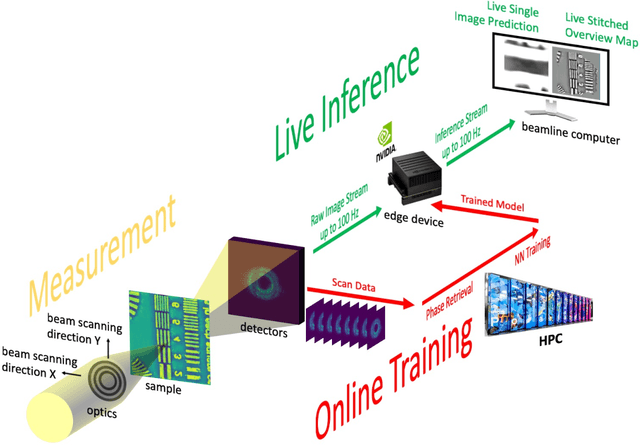
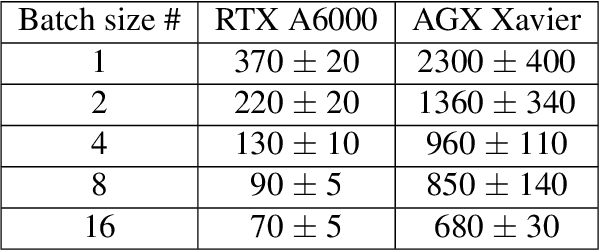
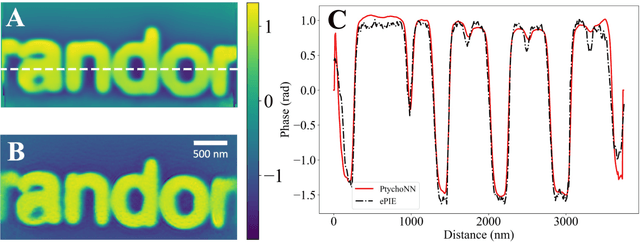

Coherent microscopy techniques provide an unparalleled multi-scale view of materials across scientific and technological fields, from structural materials to quantum devices, from integrated circuits to biological cells. Driven by the construction of brighter sources and high-rate detectors, coherent X-ray microscopy methods like ptychography are poised to revolutionize nanoscale materials characterization. However, associated significant increases in data and compute needs mean that conventional approaches no longer suffice for recovering sample images in real-time from high-speed coherent imaging experiments. Here, we demonstrate a workflow that leverages artificial intelligence at the edge and high-performance computing to enable real-time inversion on X-ray ptychography data streamed directly from a detector at up to 2 kHz. The proposed AI-enabled workflow eliminates the sampling constraints imposed by traditional ptychography, allowing low dose imaging using orders of magnitude less data than required by traditional methods.
SpinAPS: A High-Performance Spintronic Accelerator for Probabilistic Spiking Neural Networks
Aug 05, 2020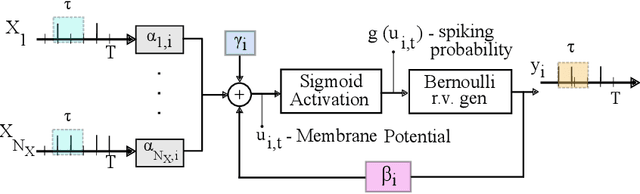

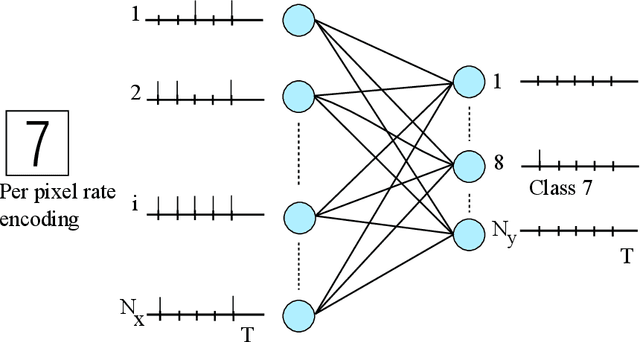
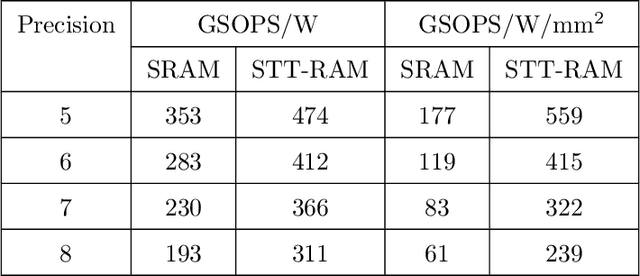
We discuss a high-performance and high-throughput hardware accelerator for probabilistic Spiking Neural Networks (SNNs) based on Generalized Linear Model (GLM) neurons, that uses binary STT-RAM devices as synapses and digital CMOS logic for neurons. The inference accelerator, termed "SpinAPS" for Spintronic Accelerator for Probabilistic SNNs, implements a principled direct learning rule for first-to-spike decoding without the need for conversion from pre-trained ANNs. The proposed solution is shown to achieve comparable performance with an equivalent ANN on handwritten digit and human activity recognition benchmarks. The inference engine, SpinAPS, is shown through software emulation tools to achieve 4x performance improvement in terms of GSOPS/W/mm2 when compared to an equivalent SRAM-based design. The architecture leverages probabilistic spiking neural networks that employ first-to-spike decoding rule to make inference decisions at low latencies, achieving 75% of the test performance in as few as 4 algorithmic time steps on the handwritten digit benchmark. The accelerator also exhibits competitive performance with other memristor-based DNN/SNN accelerators and state-of-the-art GPUs.
Stochastic Deep Learning in Memristive Networks
Nov 09, 2017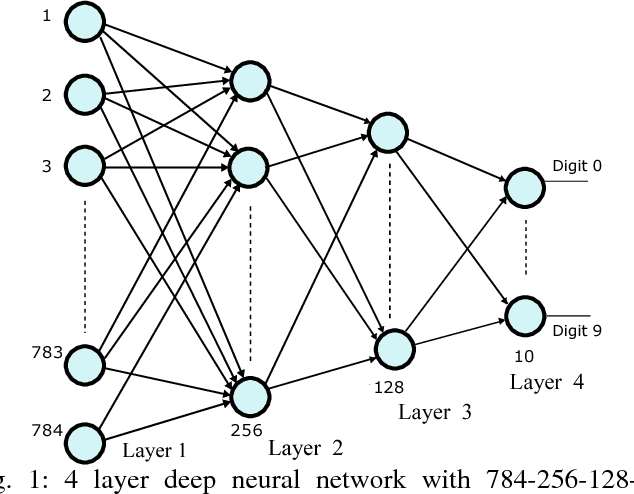
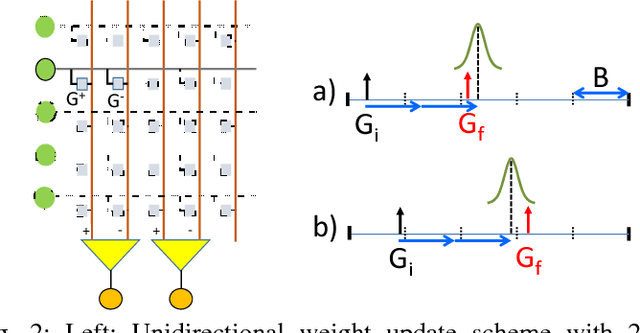
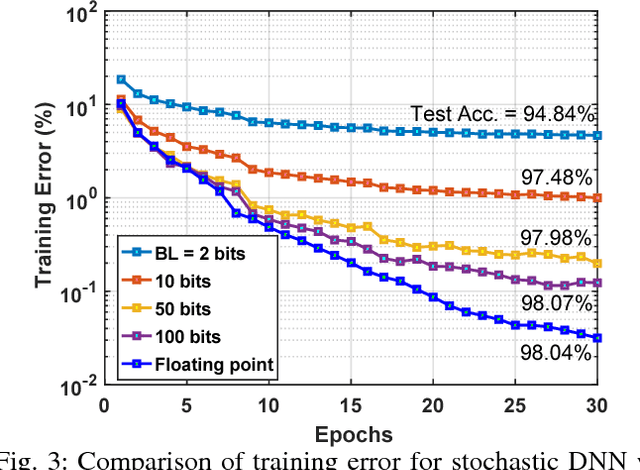
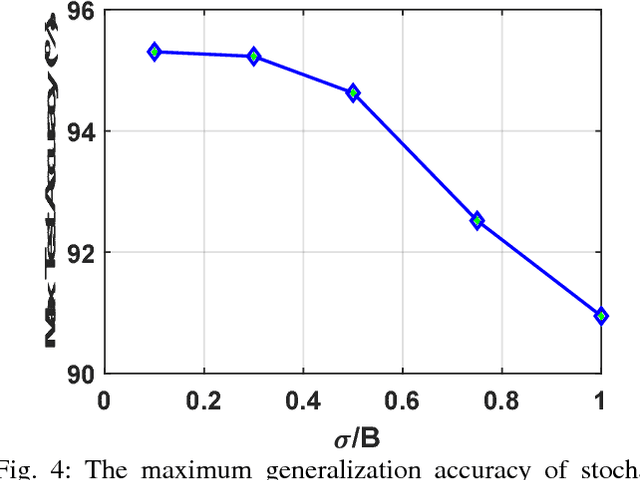
We study the performance of stochastically trained deep neural networks (DNNs) whose synaptic weights are implemented using emerging memristive devices that exhibit limited dynamic range, resolution, and variability in their programming characteristics. We show that a key device parameter to optimize the learning efficiency of DNNs is the variability in its programming characteristics. DNNs with such memristive synapses, even with dynamic range as low as $15$ and only $32$ discrete levels, when trained based on stochastic updates suffer less than $3\%$ loss in accuracy compared to floating point software baseline. We also study the performance of stochastic memristive DNNs when used as inference engines with noise corrupted data and find that if the device variability can be minimized, the relative degradation in performance for the Stochastic DNN is better than that of the software baseline. Hence, our study presents a new optimization corner for memristive devices for building large noise-immune deep learning systems.