 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Turbulent Magnetohydrodynamics: A Hybrid Operator-Diffusion Framework
Jul 02, 2025We present a hybrid machine learning framework that combines Physics-Informed Neural Operators (PINOs) with score-based generative diffusion models to simulate the full spatio-temporal evolution of two-dimensional, incompressible, resistive magnetohydrodynamic (MHD) turbulence across a broad range of Reynolds numbers ($\mathrm{Re}$). The framework leverages the equation-constrained generalization capabilities of PINOs to predict coherent, low-frequency dynamics, while a conditional diffusion model stochastically corrects high-frequency residuals, enabling accurate modeling of fully developed turbulence. Trained on a comprehensive ensemble of high-fidelity simulations with $\mathrm{Re} \in \{100, 250, 500, 750, 1000, 3000, 10000\}$, the approach achieves state-of-the-art accuracy in regimes previously inaccessible to deterministic surrogates. At $\mathrm{Re}=1000$ and $3000$, the model faithfully reconstructs the full spectral energy distributions of both velocity and magnetic fields late into the simulation, capturing non-Gaussian statistics, intermittent structures, and cross-field correlations with high fidelity. At extreme turbulence levels ($\mathrm{Re}=10000$), it remains the first surrogate capable of recovering the high-wavenumber evolution of the magnetic field, preserving large-scale morphology and enabling statistically meaningful predictions.
MOFA: Discovering Materials for Carbon Capture with a GenAI- and Simulation-Based Workflow
Jan 18, 2025We present MOFA, an open-source generative AI (GenAI) plus simulation workflow for high-throughput generation of metal-organic frameworks (MOFs) on large-scale high-performance computing (HPC) systems. MOFA addresses key challenges in integrating GPU-accelerated computing for GPU-intensive GenAI tasks, including distributed training and inference, alongside CPU- and GPU-optimized tasks for screening and filtering AI-generated MOFs using molecular dynamics, density functional theory, and Monte Carlo simulations. These heterogeneous tasks are unified within an online learning framework that optimizes the utilization of available CPU and GPU resources across HPC systems. Performance metrics from a 450-node (14,400 AMD Zen 3 CPUs + 1800 NVIDIA A100 GPUs) supercomputer run demonstrate that MOFA achieves high-throughput generation of novel MOF structures, with CO$_2$ adsorption capacities ranking among the top 10 in the hypothetical MOF (hMOF) dataset. Furthermore, the production of high-quality MOFs exhibits a linear relationship with the number of nodes utilized. The modular architecture of MOFA will facilitate its integration into other scientific applications that dynamically combine GenAI with large-scale simulations.
AI-driven Conservative-to-Primitive Conversion in Hybrid Piecewise Polytropic and Tabulated Equations of State
Dec 10, 2024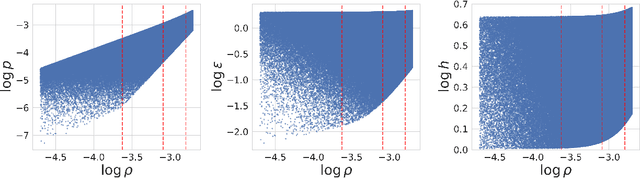


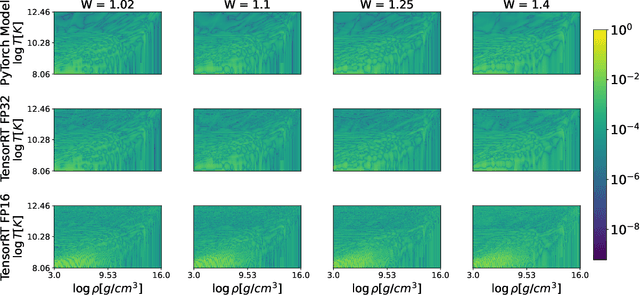
We present a novel AI-based approach to accelerate conservative-to-primitive inversion in relativistic hydrodynamics simulations, focusing on hybrid piecewise polytropic and tabulated equations of state. Traditional root-finding methods are computationally intensive, particularly in large-scale simulations. To address this, we employ feedforward neural networks (NNC2PS and NNC2PL), trained in PyTorch and optimized for GPU inference using NVIDIA TensorRT, achieving significant speedups with minimal loss in accuracy. The NNC2PS model achieves $L_1$ and $L_\infty$ errors of $4.54 \times 10^{-7}$ and $3.44 \times 10^{-6}$, respectively, with the NNC2PL model yielding even lower error values. TensorRT optimization ensures high accuracy, with FP16 quantization offering 7x faster performance than traditional root-finding methods. Our AI models outperform conventional CPU solvers, demonstrating enhanced inference times, particularly for large datasets. We release the scientific software developed for this work, enabling the validation and extension of our findings. These results highlight the potential of AI, combined with GPU optimization, to significantly improve the efficiency and scalability of numerical relativity simulations.
AI ensemble for signal detection of higher order gravitational wave modes of quasi-circular, spinning, non-precessing binary black hole mergers
Sep 29, 2023


We introduce spatiotemporal-graph models that concurrently process data from the twin advanced LIGO detectors and the advanced Virgo detector. We trained these AI classifiers with 2.4 million \texttt{IMRPhenomXPHM} waveforms that describe quasi-circular, spinning, non-precessing binary black hole mergers with component masses $m_{\{1,2\}}\in[3M_\odot, 50 M_\odot]$, and individual spins $s^z_{\{1,2\}}\in[-0.9, 0.9]$; and which include the $(\ell, |m|) = \{(2, 2), (2, 1), (3, 3), (3, 2), (4, 4)\}$ modes, and mode mixing effects in the $\ell = 3, |m| = 2$ harmonics. We trained these AI classifiers within 22 hours using distributed training over 96 NVIDIA V100 GPUs in the Summit supercomputer. We then used transfer learning to create AI predictors that estimate the total mass of potential binary black holes identified by all AI classifiers in the ensemble. We used this ensemble, 3 AI classifiers and 2 predictors, to process a year-long test set in which we injected 300,000 signals. This year-long test set was processed within 5.19 minutes using 1024 NVIDIA A100 GPUs in the Polaris supercomputer (for AI inference) and 128 CPU nodes in the ThetaKNL supercomputer (for post-processing of noise triggers), housed at the Argonne Leadership Supercomputing Facility. These studies indicate that our AI ensemble provides state-of-the-art signal detection accuracy, and reports 2 misclassifications for every year of searched data. This is the first AI ensemble designed to search for and find higher order gravitational wave mode signals.
FedCompass: Efficient Cross-Silo Federated Learning on Heterogeneous Client Devices using a Computing Power Aware Scheduler
Sep 26, 2023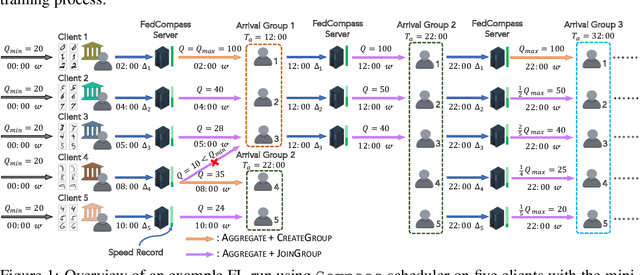

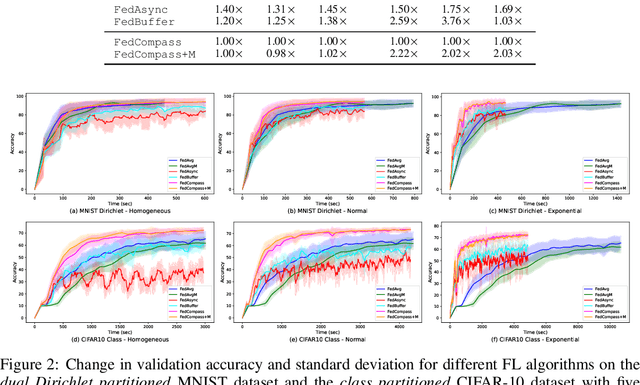

Cross-silo federated learning offers a promising solution to collaboratively train robust and generalized AI models without compromising the privacy of local datasets, e.g., healthcare, financial, as well as scientific projects that lack a centralized data facility. Nonetheless, because of the disparity of computing resources among different clients (i.e., device heterogeneity), synchronous federated learning algorithms suffer from degraded efficiency when waiting for straggler clients. Similarly, asynchronous federated learning algorithms experience degradation in the convergence rate and final model accuracy on non-identically and independently distributed (non-IID) heterogeneous datasets due to stale local models and client drift. To address these limitations in cross-silo federated learning with heterogeneous clients and data, we propose FedCompass, an innovative semi-asynchronous federated learning algorithm with a computing power aware scheduler on the server side, which adaptively assigns varying amounts of training tasks to different clients using the knowledge of the computing power of individual clients. FedCompass ensures that multiple locally trained models from clients are received almost simultaneously as a group for aggregation, effectively reducing the staleness of local models. At the same time, the overall training process remains asynchronous, eliminating prolonged waiting periods from straggler clients. Using diverse non-IID heterogeneous distributed datasets, we demonstrate that FedCompass achieves faster convergence and higher accuracy than other asynchronous algorithms while remaining more efficient than synchronous algorithms when performing federated learning on heterogeneous clients.
APPFLx: Providing Privacy-Preserving Cross-Silo Federated Learning as a Service
Aug 17, 2023



Cross-silo privacy-preserving federated learning (PPFL) is a powerful tool to collaboratively train robust and generalized machine learning (ML) models without sharing sensitive (e.g., healthcare of financial) local data. To ease and accelerate the adoption of PPFL, we introduce APPFLx, a ready-to-use platform that provides privacy-preserving cross-silo federated learning as a service. APPFLx employs Globus authentication to allow users to easily and securely invite trustworthy collaborators for PPFL, implements several synchronous and asynchronous FL algorithms, streamlines the FL experiment launch process, and enables tracking and visualizing the life cycle of FL experiments, allowing domain experts and ML practitioners to easily orchestrate and evaluate cross-silo FL under one platform. APPFLx is available online at https://appflx.link
APACE: AlphaFold2 and advanced computing as a service for accelerated discovery in biophysics
Aug 15, 2023The prediction of protein 3D structure from amino acid sequence is a computational grand challenge in biophysics, and plays a key role in robust protein structure prediction algorithms, from drug discovery to genome interpretation. The advent of AI models, such as AlphaFold, is revolutionizing applications that depend on robust protein structure prediction algorithms. To maximize the impact, and ease the usability, of these novel AI tools we introduce APACE, AlphaFold2 and advanced computing as a service, a novel computational framework that effectively handles this AI model and its TB-size database to conduct accelerated protein structure prediction analyses in modern supercomputing environments. We deployed APACE in the Delta supercomputer, and quantified its performance for accurate protein structure predictions using four exemplar proteins: 6AWO, 6OAN, 7MEZ, and 6D6U. Using up to 200 ensembles, distributed across 50 nodes in Delta, equivalent to 200 A100 NVIDIA GPUs, we found that APACE is up to two orders of magnitude faster than off-the-shelf AlphaFold2 implementations, reducing time-to-solution from weeks to minutes. This computational approach may be readily linked with robotics laboratories to automate and accelerate scientific discovery.
Physics-inspired spatiotemporal-graph AI ensemble for gravitational wave detection
Jun 27, 2023We introduce a novel method for gravitational wave detection that combines: 1) hybrid dilated convolution neural networks to accurately model both short- and long-range temporal sequential information of gravitational wave signals; and 2) graph neural networks to capture spatial correlations among gravitational wave observatories to consistently describe and identify the presence of a signal in a detector network. These spatiotemporal-graph AI models are tested for signal detection of gravitational waves emitted by quasi-circular, non-spinning and quasi-circular, spinning, non-precessing binary black hole mergers. For the latter case, we needed a dataset of 1.2 million modeled waveforms to densely sample this signal manifold. Thus, we reduced time-to-solution by training several AI models in the Polaris supercomputer at the Argonne Leadership Supercomputing Facility within 1.7 hours by distributing the training over 256 NVIDIA A100 GPUs, achieving optimal classification performance. This approach also exhibits strong scaling up to 512 NVIDIA A100 GPUs. We then created ensembles of AI models to process data from a three detector network, namely, the advanced LIGO Hanford and Livingston detectors, and the advanced Virgo detector. An ensemble of 2 AI models achieves state-of-the-art performance for signal detection, and reports seven misclassifications per decade of searched data, whereas an ensemble of 4 AI models achieves optimal performance for signal detection with two misclassifications for every decade of searched data. Finally, when we distributed AI inference over 128 GPUs in the Polaris supercomputer and 128 nodes in the Theta supercomputer, our AI ensemble is capable of processing a decade of gravitational wave data from a three detector network within 3.5 hours.
GHP-MOFassemble: Diffusion modeling, high throughput screening, and molecular dynamics for rational discovery of novel metal-organic frameworks for carbon capture at scale
Jun 14, 2023We introduce GHP-MOFassemble, a Generative artificial intelligence (AI), High Performance framework to accelerate the rational design of metal-organic frameworks (MOFs) with high CO2 capacity and synthesizable linkers. Our framework combines a diffusion model, a class of generative AI, to generate novel linkers that are assembled with one of three pre-selected nodes into MOFs in a primitive cubic (pcu) topology. The CO2 capacities of these AI-generated MOFs are predicted using a modified version of the crystal graph convolutional neural network model. We then use the LAMMPS code to perform molecular dynamics simulations to relax the AI-generated MOF structures, and identify those that converge to stable structures, and maintain their porous properties throughout the simulations. Among 120,000 pcu MOF candidates generated by the GHP-MOFassemble framework, with three distinct metal nodes (Cu paddlewheel, Zn paddlewheel, Zn tetramer), a total of 102 structures completed molecular dynamics simulations at 1 bar with predicted CO2 capacity higher than 2 mmol/g at 0.1 bar, which corresponds to the top 5% of hMOFs in the hypothetical MOF (hMOF) dataset in the MOFX-DB database. Among these candidates, 18 have change in density lower than 1% during molecular dynamics simulations, indicating their stability. We also found that the top five GHP-MOFassemble's MOF structures have CO2 capacities higher than 96.9% of hMOF structures. This new approach combines generative AI, graph modeling, large-scale molecular dynamics simulations, and extreme scale computing to open up new pathways for the accelerated discovery of novel MOF structures at scale.
Magnetohydrodynamics with Physics Informed Neural Operators
Feb 13, 2023We present the first application of physics informed neural operators, which use tensor Fourier neural operators as their backbone, to model 2D incompressible magnetohydrodynamics simulations. Our results indicate that physics informed AI can accurately model the physics of magnetohydrodynamics simulations that describe laminar flows with Reynolds numbers $Re\leq250$. We also quantify the applicability of our AI surrogates for turbulent flows, and explore how magnetohydrodynamics simulations and AI surrogates store magnetic and kinetic energy across wavenumbers. Based on these studies, we propose a variety of approaches to create AI surrogates that provide a computationally efficient and high fidelity description of magnetohydrodynamics simulations for a broad range of Reynolds numbers. Neural operators and scientific software to produce simulation data to train, validate and test our physics informed neural operators are released with this manuscript.