 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of Representation Learning Methods in Particle Physics Foundation Models
Nov 16, 2025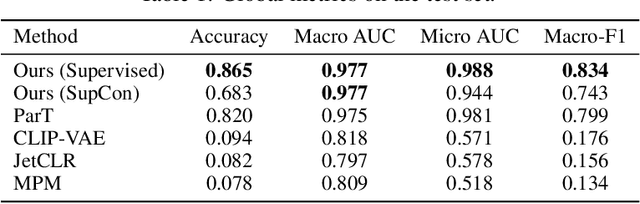
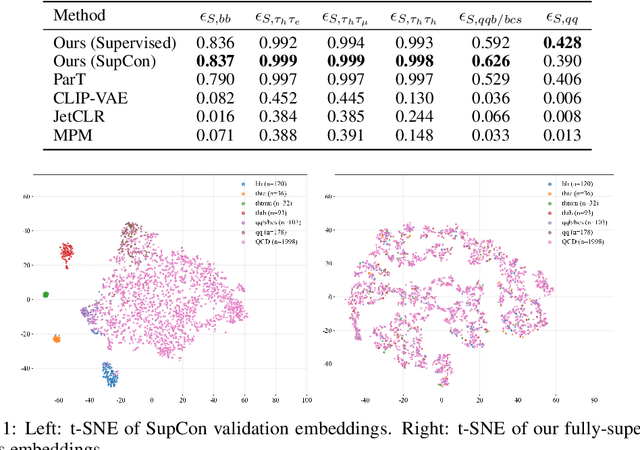
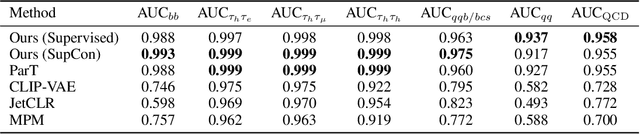
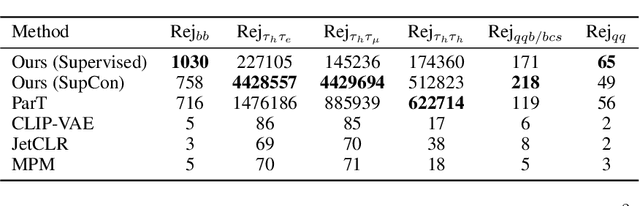
We present a systematic evaluation of representation learning objectives for particle physics within a unified framework. Our study employs a shared transformer-based particle-cloud encoder with standardized preprocessing, matched sampling, and a consistent evaluation protocol on a jet classification dataset. We compare contrastive (supervised and self-supervised), masked particle modeling, and generative reconstruction objectives under a common training regimen. In addition, we introduce targeted supervised architectural modifications that achieve state-of-the-art performance on benchmark evaluations. This controlled comparison isolates the contributions of the learning objective, highlights their respective strengths and limitations, and provides reproducible baselines. We position this work as a reference point for the future development of foundation models in particle physics, enabling more transparent and robust progress across the community.
RINO: Renormalization Group Invariance with No Labels
Sep 10, 2025A common challenge with supervised machine learning (ML) in high energy physics (HEP) is the reliance on simulations for labeled data, which can often mismodel the underlying collision or detector response. To help mitigate this problem of domain shift, we propose RINO (Renormalization Group Invariance with No Labels), a self-supervised learning approach that can instead pretrain models directly on collision data, learning embeddings invariant to renormalization group flow scales. In this work, we pretrain a transformer-based model on jets originating from quantum chromodynamic (QCD) interactions from the JetClass dataset, emulating real QCD-dominated experimental data, and then finetune on the JetNet dataset -- emulating simulations -- for the task of identifying jets originating from top quark decays. RINO demonstrates improved generalization from the JetNet training data to JetClass data compared to supervised training on JetNet from scratch, demonstrating the potential for RINO pretraining on real collision data followed by fine-tuning on small, high-quality MC datasets, to improve the robustness of ML models in HEP.
Learning Symmetry-Independent Jet Representations via Jet-Based Joint Embedding Predictive Architecture
Dec 05, 2024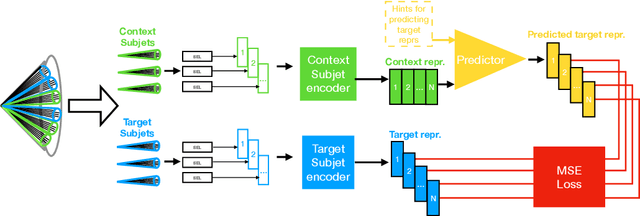
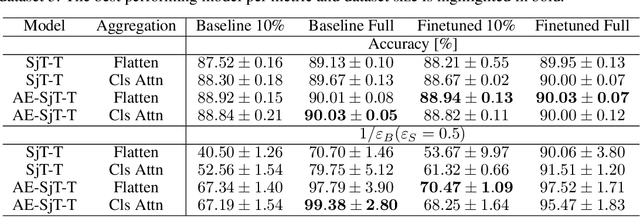
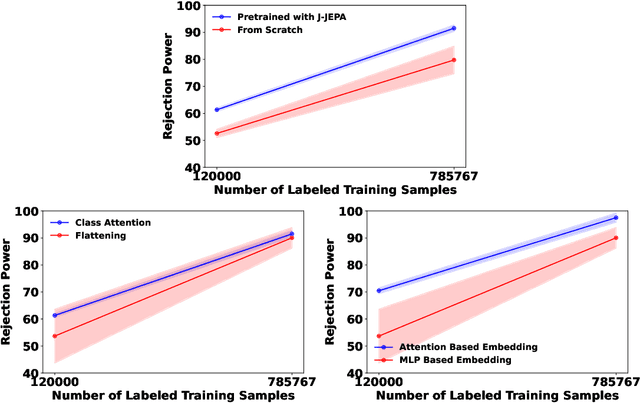
In high energy physics, self-supervised learning (SSL) methods have the potential to aid in the creation of machine learning models without the need for labeled datasets for a variety of tasks, including those related to jets -- narrow sprays of particles produced by quarks and gluons in high energy particle collisions. This study introduces an approach to learning jet representations without hand-crafted augmentations using a jet-based joint embedding predictive architecture (J-JEPA), which aims to predict various physical targets from an informative context. As our method does not require hand-crafted augmentation like other common SSL techniques, J-JEPA avoids introducing biases that could harm downstream tasks. Since different tasks generally require invariance under different augmentations, this training without hand-crafted augmentation enables versatile applications, offering a pathway toward a cross-task foundation model. We finetune the representations learned by J-JEPA for jet tagging and benchmark them against task-specific representations.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024
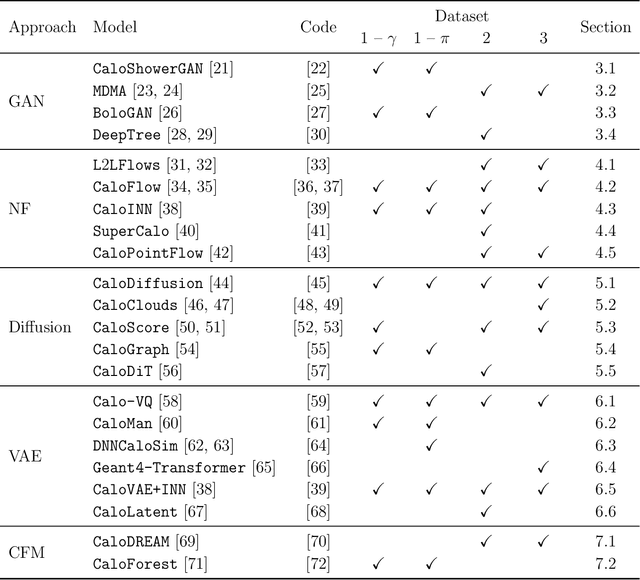
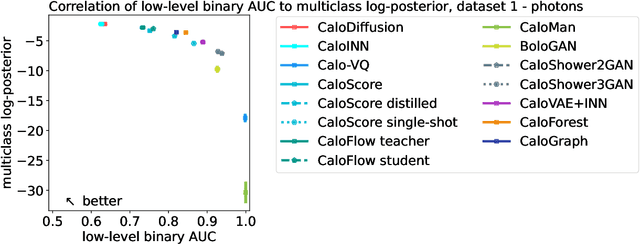
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Induced Generative Adversarial Particle Transformers
Dec 08, 2023In high energy physics (HEP), machine learning methods have emerged as an effective way to accurately simulate particle collisions at the Large Hadron Collider (LHC). The message-passing generative adversarial network (MPGAN) was the first model to simulate collisions as point, or ``particle'', clouds, with state-of-the-art results, but suffered from quadratic time complexity. Recently, generative adversarial particle transformers (GAPTs) were introduced to address this drawback; however, results did not surpass MPGAN. We introduce induced GAPT (iGAPT) which, by integrating ``induced particle-attention blocks'' and conditioning on global jet attributes, not only offers linear time complexity but is also able to capture intricate jet substructure, surpassing MPGAN in many metrics. Our experiments demonstrate the potential of iGAPT to simulate complex HEP data accurately and efficiently.
FAIR AI Models in High Energy Physics
Dec 21, 2022The findable, accessible, interoperable, and reusable (FAIR) data principles have provided a framework for examining, evaluating, and improving how we share data with the aim of facilitating scientific discovery. Efforts have been made to generalize these principles to research software and other digital products. Artificial intelligence (AI) models -- algorithms that have been trained on data rather than explicitly programmed -- are an important target for this because of the ever-increasing pace with which AI is transforming scientific and engineering domains. In this paper, we propose a practical definition of FAIR principles for AI models and create a FAIR AI project template that promotes adherence to these principles. We demonstrate how to implement these principles using a concrete example from experimental high energy physics: a graph neural network for identifying Higgs bosons decaying to bottom quarks. We study the robustness of these FAIR AI models and their portability across hardware architectures and software frameworks, and report new insights on the interpretability of AI predictions by studying the interplay between FAIR datasets and AI models. Enabled by publishing FAIR AI models, these studies pave the way toward reliable and automated AI-driven scientific discovery.
Lorentz Group Equivariant Autoencoders
Dec 14, 2022There has been significant work recently in developing machine learning models in high energy physics (HEP), for tasks such as classification, simulation, and anomaly detection. Typically, these models are adapted from those designed for datasets in computer vision or natural language processing without necessarily incorporating inductive biases suited to HEP data, such as respecting its inherent symmetries. Such inductive biases can make the model more performant and interpretable, and reduce the amount of training data needed. To that end, we develop the Lorentz group autoencoder (LGAE), an autoencoder model equivariant with respect to the proper, orthochronous Lorentz group $\mathrm{SO}^+(3,1)$, with a latent space living in the representations of the group. We present our architecture and several experimental results on jets at the LHC and find it significantly outperforms a non-Lorentz-equivariant graph neural network baseline on compression and reconstruction, and anomaly detection. We also demonstrate the advantage of such an equivariant model in analyzing the latent space of the autoencoder, which can have a significant impact on the explainability of anomalies found by such black-box machine learning models.
On the Evaluation of Generative Models in High Energy Physics
Nov 18, 2022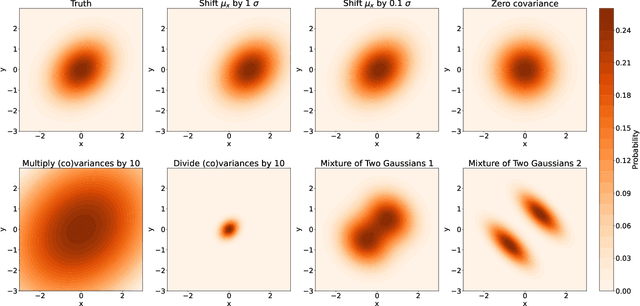
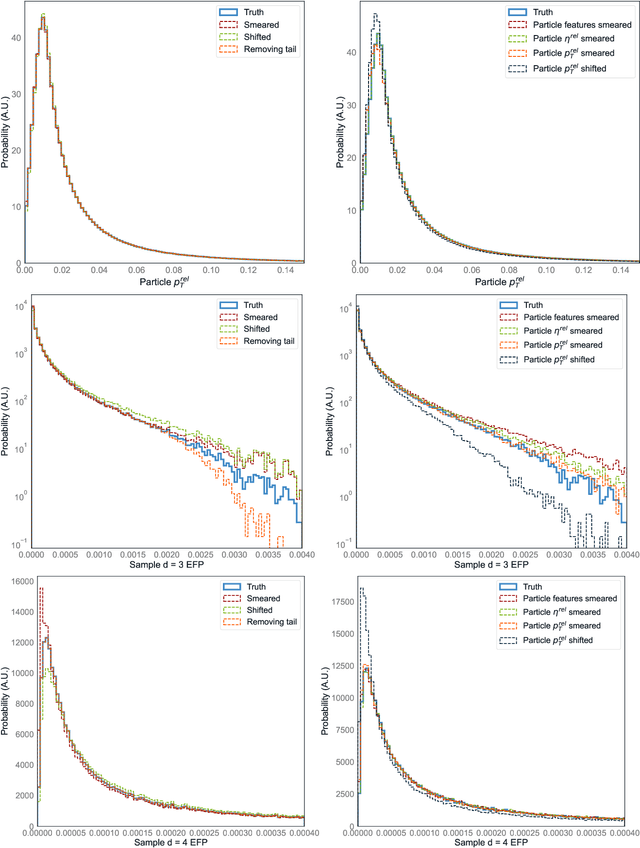
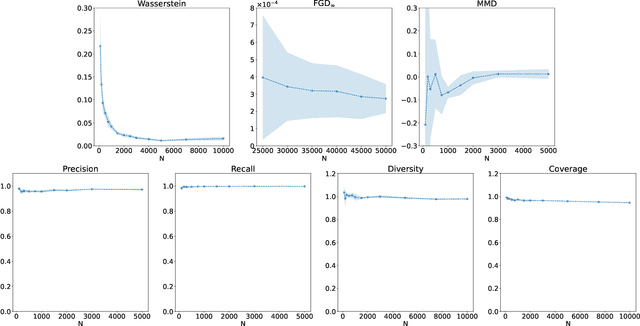
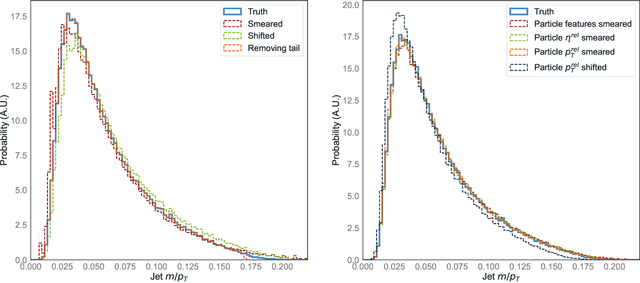
There has been a recent explosion in research into machine-learning-based generative modeling to tackle computational challenges for simulations in high energy physics (HEP). In order to use such alternative simulators in practice, we need well defined metrics to compare different generative models and evaluate their discrepancy from the true distributions. We present the first systematic review and investigation into evaluation metrics and their sensitivity to failure modes of generative models, using the framework of two-sample goodness-of-fit testing, and their relevance and viability for HEP. Inspired by previous work in both physics and computer vision, we propose two new metrics, the Fr\'echet and kernel physics distances (FPD and KPD), and perform a variety of experiments measuring their performance on simple Gaussian-distributed, and simulated high energy jet datasets. We find FPD, in particular, to be the most sensitive metric to all alternative jet distributions tested and recommend its adoption, along with the KPD and Wasserstein distances between individual feature distributions, for evaluating generative models in HEP. We finally demonstrate the efficacy of these proposed metrics in evaluating and comparing a novel attention-based generative adversarial particle transformer to the state-of-the-art message-passing generative adversarial network jet simulation model.
Do graph neural networks learn traditional jet substructure?
Nov 17, 2022



At the CERN LHC, the task of jet tagging, whose goal is to infer the origin of a jet given a set of final-state particles, is dominated by machine learning methods. Graph neural networks have been used to address this task by treating jets as point clouds with underlying, learnable, edge connections between the particles inside. We explore the decision-making process for one such state-of-the-art network, ParticleNet, by looking for relevant edge connections identified using the layerwise-relevance propagation technique. As the model is trained, we observe changes in the distribution of relevant edges connecting different intermediate clusters of particles, known as subjets. The resulting distribution of subjet connections is different for signal jets originating from top quarks, whose subjets typically correspond to its three decay products, and background jets originating from lighter quarks and gluons. This behavior indicates that the model is using traditional jet substructure observables, such as the number of prongs -- energetic particle clusters -- within a jet, when identifying jets.
Particle-based Fast Jet Simulation at the LHC with Variational Autoencoders
Mar 01, 2022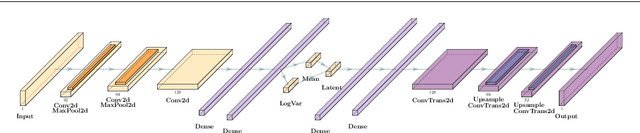
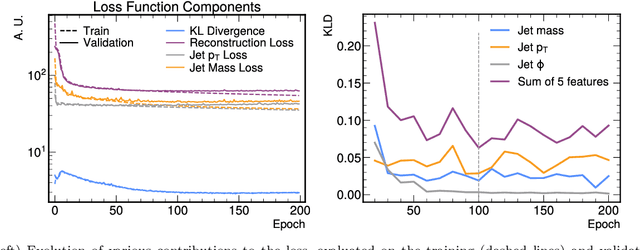
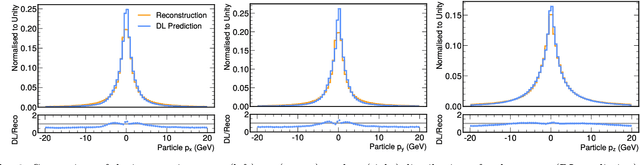
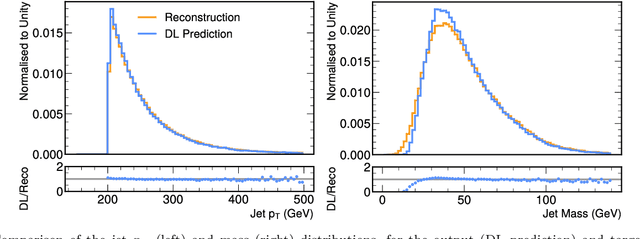
We study how to use Deep Variational Autoencoders for a fast simulation of jets of particles at the LHC. We represent jets as a list of constituents, characterized by their momenta. Starting from a simulation of the jet before detector effects, we train a Deep Variational Autoencoder to return the corresponding list of constituents after detection. Doing so, we bypass both the time-consuming detector simulation and the collision reconstruction steps of a traditional processing chain, speeding up significantly the events generation workflow. Through model optimization and hyperparameter tuning, we achieve state-of-the-art precision on the jet four-momentum, while providing an accurate description of the constituents momenta, and an inference time comparable to that of a rule-based fast simulation.