 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Next Generation AI Users and Developers at NCSA
Jun 20, 2024This article focuses on training work carried out in artificial intelligence (AI) at the National Center for Supercomputing Applications (NCSA) at the University of Illinois Urbana-Champaign via a research experience for undergraduates (REU) program named FoDOMMaT. It also describes why we are interested in AI, and concludes by discussing what we've learned from running this program and its predecessor over six years.
Leveraging Large Language Models to Build and Execute Computational Workflows
Dec 12, 2023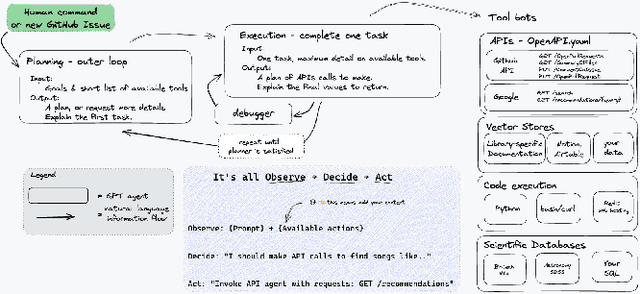
The recent development of large language models (LLMs) with multi-billion parameters, coupled with the creation of user-friendly application programming interfaces (APIs), has paved the way for automatically generating and executing code in response to straightforward human queries. This paper explores how these emerging capabilities can be harnessed to facilitate complex scientific workflows, eliminating the need for traditional coding methods. We present initial findings from our attempt to integrate Phyloflow with OpenAI's function-calling API, and outline a strategy for developing a comprehensive workflow management system based on these concepts.
FAIR AI Models in High Energy Physics
Dec 21, 2022The findable, accessible, interoperable, and reusable (FAIR) data principles have provided a framework for examining, evaluating, and improving how we share data with the aim of facilitating scientific discovery. Efforts have been made to generalize these principles to research software and other digital products. Artificial intelligence (AI) models -- algorithms that have been trained on data rather than explicitly programmed -- are an important target for this because of the ever-increasing pace with which AI is transforming scientific and engineering domains. In this paper, we propose a practical definition of FAIR principles for AI models and create a FAIR AI project template that promotes adherence to these principles. We demonstrate how to implement these principles using a concrete example from experimental high energy physics: a graph neural network for identifying Higgs bosons decaying to bottom quarks. We study the robustness of these FAIR AI models and their portability across hardware architectures and software frameworks, and report new insights on the interpretability of AI predictions by studying the interplay between FAIR datasets and AI models. Enabled by publishing FAIR AI models, these studies pave the way toward reliable and automated AI-driven scientific discovery.
A FAIR and AI-ready Higgs Boson Decay Dataset
Aug 04, 2021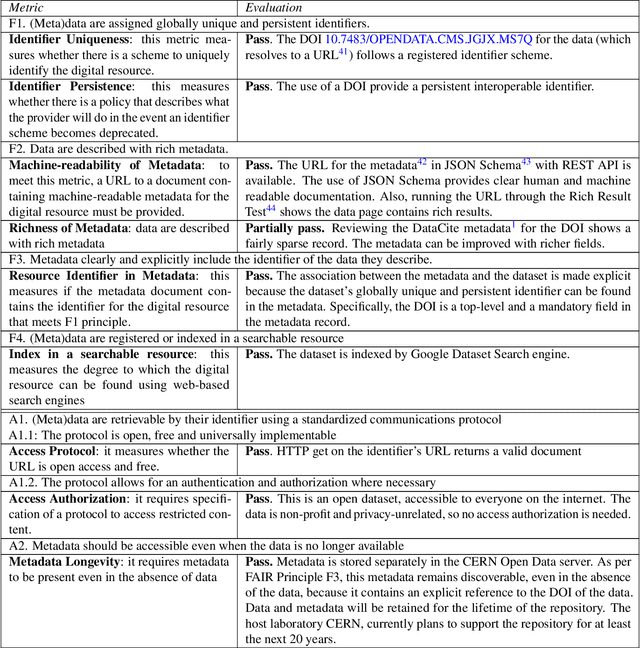
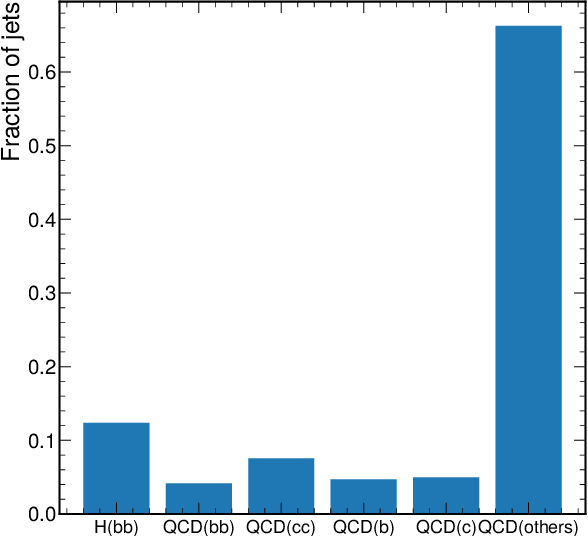
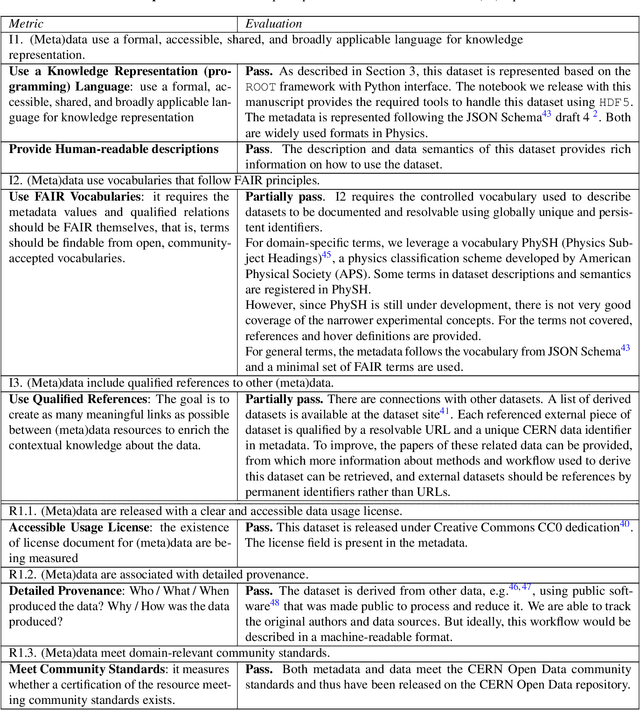
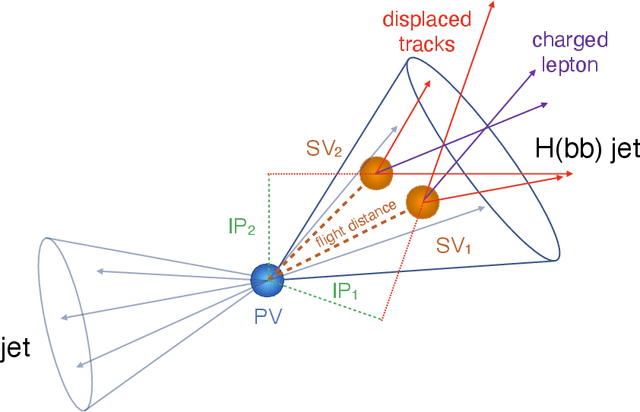
To enable the reusability of massive scientific datasets by humans and machines, researchers aim to create scientific datasets that adhere to the principles of findability, accessibility, interoperability, and reusability (FAIR) for data and artificial intelligence (AI) models. This article provides a domain-agnostic, step-by-step assessment guide to evaluate whether or not a given dataset meets each FAIR principle. We then demonstrate how to use this guide to evaluate the FAIRness of an open simulated dataset produced by the CMS Collaboration at the CERN Large Hadron Collider. This dataset consists of Higgs boson decays and quark and gluon background, and is available through the CERN Open Data Portal. We also use other available tools to assess the FAIRness of this dataset, and incorporate feedback from members of the FAIR community to validate our results. This article is accompanied by a Jupyter notebook to facilitate an understanding and exploration of the dataset, including visualization of its elements. This study marks the first in a planned series of articles that will guide scientists in the creation and quantification of FAIRness in high energy particle physics datasets and AI models.
Confluence of Artificial Intelligence and High Performance Computing for Accelerated, Scalable and Reproducible Gravitational Wave Detection
Dec 15, 2020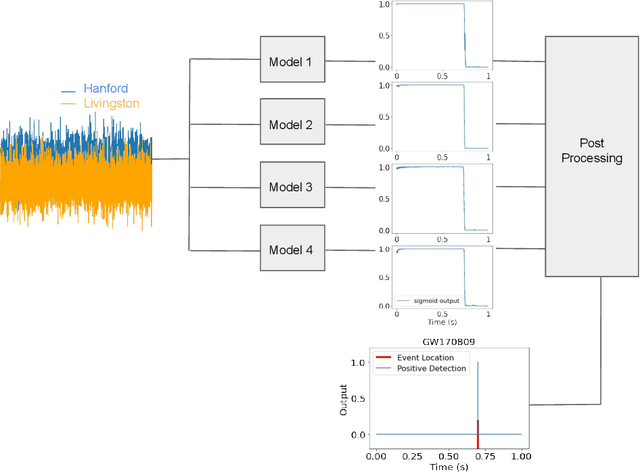
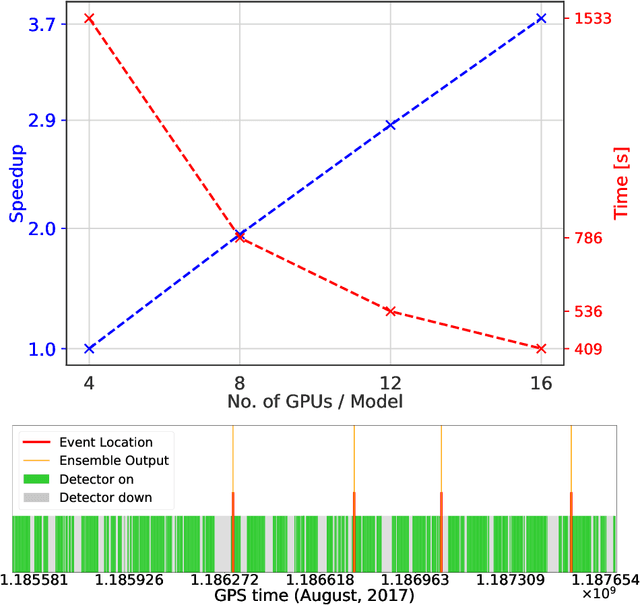
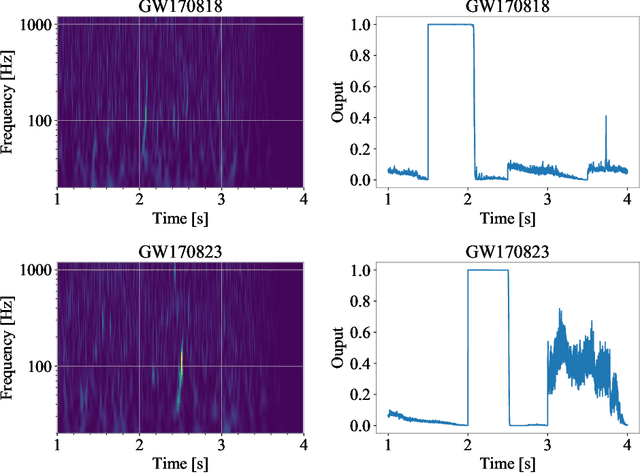
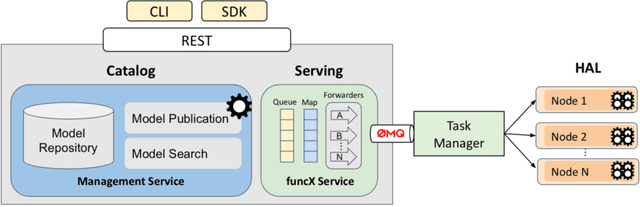
Finding new ways to use artificial intelligence (AI) to accelerate the analysis of gravitational wave data, and ensuring the developed models are easily reusable promises to unlock new opportunities in multi-messenger astrophysics (MMA), and to enable wider use, rigorous validation, and sharing of developed models by the community. In this work, we demonstrate how connecting recently deployed DOE and NSF-sponsored cyberinfrastructure allows for new ways to publish models, and to subsequently deploy these models into applications using computing platforms ranging from laptops to high performance computing clusters. We develop a workflow that connects the Data and Learning Hub for Science (DLHub), a repository for publishing machine learning models, with the Hardware Accelerated Learning (HAL) deep learning computing cluster, using funcX as a universal distributed computing service. We then use this workflow to search for binary black hole gravitational wave signals in open source advanced LIGO data. We find that using this workflow, an ensemble of four openly available deep learning models can be run on HAL and process the entire month of August 2017 of advanced LIGO data in just seven minutes, identifying all four binary black hole mergers previously identified in this dataset, and reporting no misclassifications. This approach, which combines advances in AI, distributed computing, and scientific data infrastructure opens new pathways to conduct reproducible, accelerated, data-driven gravitational wave detection.
Convergence of Artificial Intelligence and High Performance Computing on NSF-supported Cyberinfrastructure
Mar 18, 2020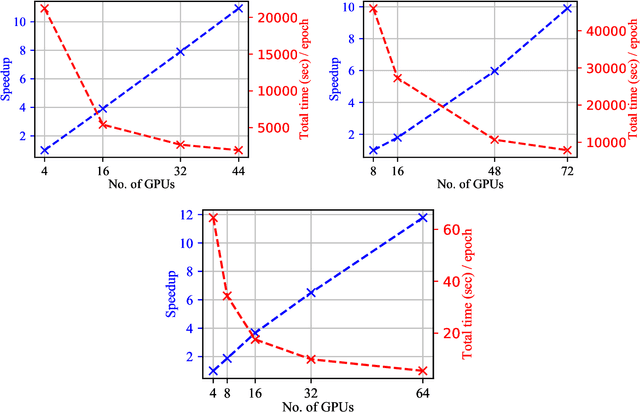
Significant investments to upgrade or construct large-scale scientific facilities demand commensurate investments in R&D to design algorithms and computing approaches to enable scientific and engineering breakthroughs in the big data era. The remarkable success of Artificial Intelligence (AI) algorithms to turn big-data challenges in industry and technology into transformational digital solutions that drive a multi-billion dollar industry, which play an ever increasing role shaping human social patterns, has promoted AI as the most sought after signal processing tool in big-data research. As AI continues to evolve into a computing tool endowed with statistical and mathematical rigor, and which encodes domain expertise to inform and inspire AI architectures and optimization algorithms, it has become apparent that single-GPU solutions for training, validation, and testing are no longer sufficient. This realization has been driving the confluence of AI and high performance computing (HPC) to reduce time-to-insight and to produce robust, reliable, trustworthy, and computationally efficient AI solutions. In this white paper, we present a summary of recent developments in this field, and discuss avenues to accelerate and streamline the use of HPC platforms to design accelerated AI algorithms.
Enabling real-time multi-messenger astrophysics discoveries with deep learning
Nov 26, 2019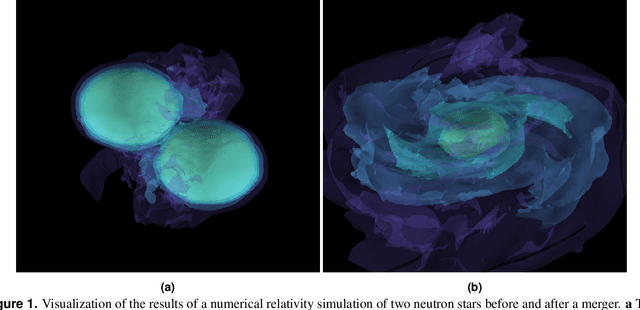
Multi-messenger astrophysics is a fast-growing, interdisciplinary field that combines data, which vary in volume and speed of data processing, from many different instruments that probe the Universe using different cosmic messengers: electromagnetic waves, cosmic rays, gravitational waves and neutrinos. In this Expert Recommendation, we review the key challenges of real-time observations of gravitational wave sources and their electromagnetic and astroparticle counterparts, and make a number of recommendations to maximize their potential for scientific discovery. These recommendations refer to the design of scalable and computationally efficient machine learning algorithms; the cyber-infrastructure to numerically simulate astrophysical sources, and to process and interpret multi-messenger astrophysics data; the management of gravitational wave detections to trigger real-time alerts for electromagnetic and astroparticle follow-ups; a vision to harness future developments of machine learning and cyber-infrastructure resources to cope with the big-data requirements; and the need to build a community of experts to realize the goals of multi-messenger astrophysics.
* Invited Expert Recommendation for Nature Reviews Physics. The art work produced by E. A. Huerta and Shawn Rosofsky for this article was used by Carl Conway to design the cover of the October 2019 issue of Nature Reviews Physics
Deep Learning for Multi-Messenger Astrophysics: A Gateway for Discovery in the Big Data Era
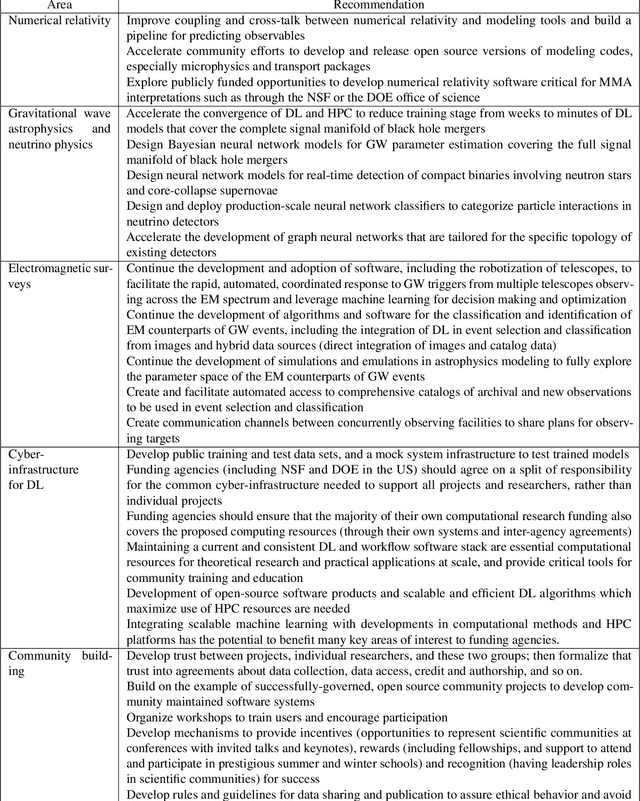
Feb 01, 2019This report provides an overview of recent work that harnesses the Big Data Revolution and Large Scale Computing to address grand computational challenges in Multi-Messenger Astrophysics, with a particular emphasis on real-time discovery campaigns. Acknowledging the transdisciplinary nature of Multi-Messenger Astrophysics, this document has been prepared by members of the physics, astronomy, computer science, data science, software and cyberinfrastructure communities who attended the NSF-, DOE- and NVIDIA-funded "Deep Learning for Multi-Messenger Astrophysics: Real-time Discovery at Scale" workshop, hosted at the National Center for Supercomputing Applications, October 17-19, 2018. Highlights of this report include unanimous agreement that it is critical to accelerate the development and deployment of novel, signal-processing algorithms that use the synergy between artificial intelligence (AI) and high performance computing to maximize the potential for scientific discovery with Multi-Messenger Astrophysics. We discuss key aspects to realize this endeavor, namely (i) the design and exploitation of scalable and computationally efficient AI algorithms for Multi-Messenger Astrophysics; (ii) cyberinfrastructure requirements to numerically simulate astrophysical sources, and to process and interpret Multi-Messenger Astrophysics data; (iii) management of gravitational wave detections and triggers to enable electromagnetic and astro-particle follow-ups; (iv) a vision to harness future developments of machine and deep learning and cyberinfrastructure resources to cope with the scale of discovery in the Big Data Era; (v) and the need to build a community that brings domain experts together with data scientists on equal footing to maximize and accelerate discovery in the nascent field of Multi-Messenger Astrophysics.