 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrillion Parameter AI Serving Infrastructure for Scientific Discovery: A Survey and Vision
Feb 05, 2024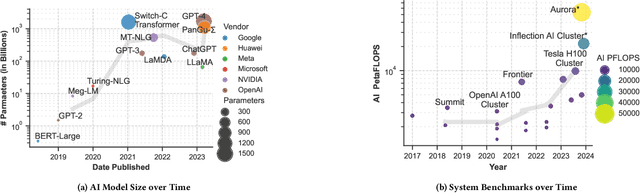
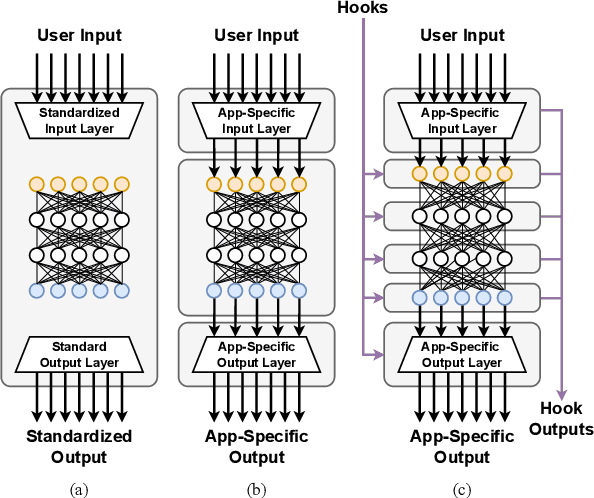
Deep learning methods are transforming research, enabling new techniques, and ultimately leading to new discoveries. As the demand for more capable AI models continues to grow, we are now entering an era of Trillion Parameter Models (TPM), or models with more than a trillion parameters -- such as Huawei's PanGu-$\Sigma$. We describe a vision for the ecosystem of TPM users and providers that caters to the specific needs of the scientific community. We then outline the significant technical challenges and open problems in system design for serving TPMs to enable scientific research and discovery. Specifically, we describe the requirements of a comprehensive software stack and interfaces to support the diverse and flexible requirements of researchers.
OpenHLS: High-Level Synthesis for Low-Latency Deep Neural Networks for Experimental Science
Feb 15, 2023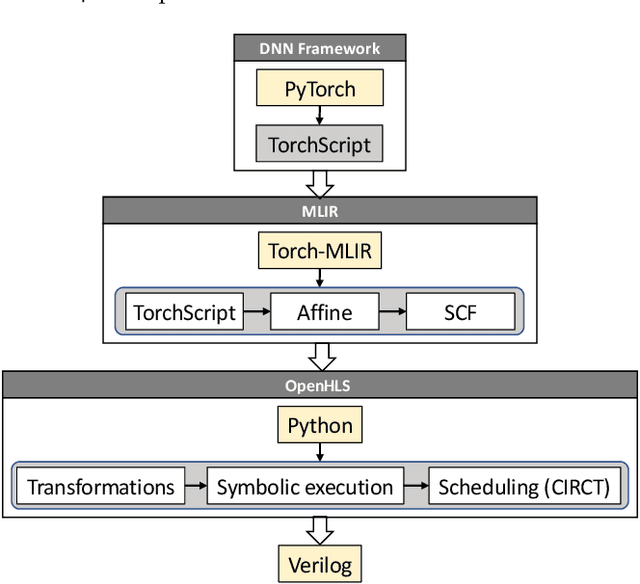

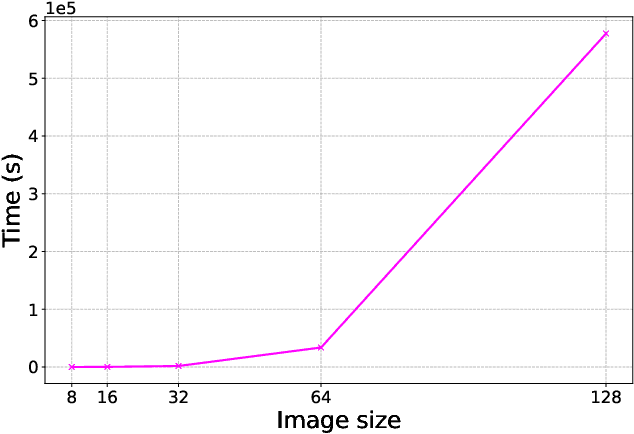

In many experiment-driven scientific domains, such as high-energy physics, material science, and cosmology, high data rate experiments impose hard constraints on data acquisition systems: collected data must either be indiscriminately stored for post-processing and analysis, thereby necessitating large storage capacity, or accurately filtered in real-time, thereby necessitating low-latency processing. Deep neural networks, effective in other filtering tasks, have not been widely employed in such data acquisition systems, due to design and deployment difficulties. We present an open source, lightweight, compiler framework, without any proprietary dependencies, OpenHLS, based on high-level synthesis techniques, for translating high-level representations of deep neural networks to low-level representations, suitable for deployment to near-sensor devices such as field-programmable gate arrays. We evaluate OpenHLS on various workloads and present a case-study implementation of a deep neural network for Bragg peak detection in the context of high-energy diffraction microscopy. We show OpenHLS is able to produce an implementation of the network with a throughput 4.8 $\mu$s/sample, which is approximately a 4$\times$ improvement over the existing implementation
Memory Planning for Deep Neural Networks
Feb 23, 2022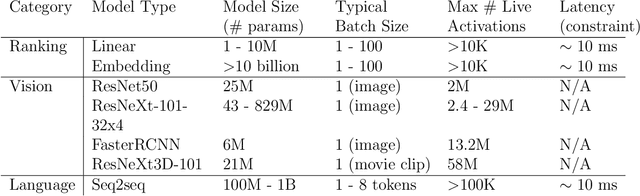
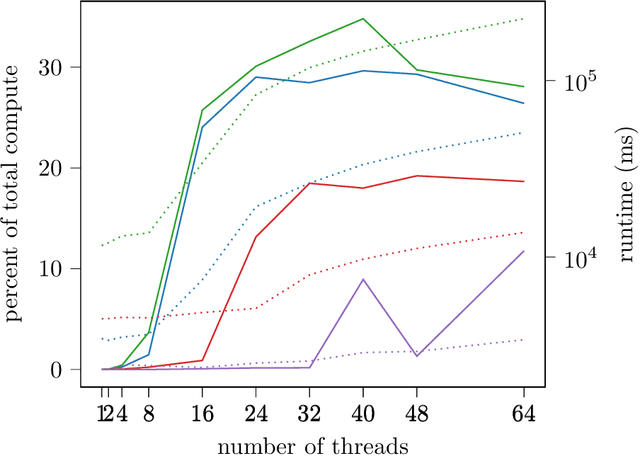
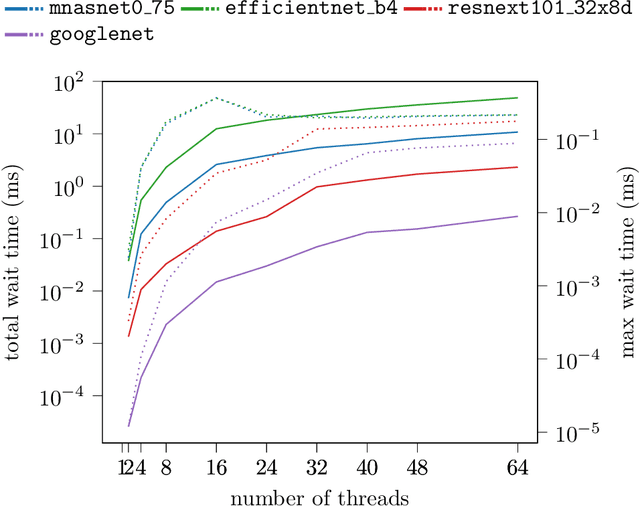
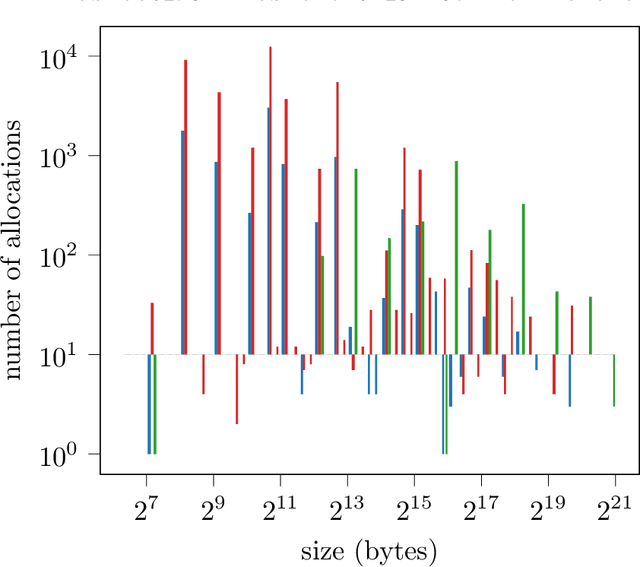
We study memory allocation patterns in DNNs during inference, in the context of large-scale systems. We observe that such memory allocation patterns, in the context of multi-threading, are subject to high latencies, due to \texttt{mutex} contention in the system memory allocator. Latencies incurred due to such \texttt{mutex} contention produce undesirable bottlenecks in user-facing services. Thus, we propose a "memorization" based technique, \texttt{MemoMalloc}, for optimizing overall latency, with only moderate increases in peak memory usage. Specifically, our technique consists of a runtime component, which captures all allocations and uniquely associates them with their high-level source operation, and a static analysis component, which constructs an efficient allocation "plan". We present an implementation of \texttt{MemoMalloc} in the PyTorch deep learning framework and evaluate memory consumption and execution performance on a wide range of DNN architectures. We find that \texttt{MemoMalloc} outperforms state-of-the-art general purpose memory allocators, with respect to DNN inference latency, by as much as 40\%.
Ultrafast Focus Detection for Automated Microscopy
Aug 26, 2021


Recent advances in scientific instruments have resulted in dramatic increase in the volumes and velocities of data being generated in every-day laboratories. Scanning electron microscopy is one such example where technological advancements are now overwhelming scientists with critical data for montaging, alignment, and image segmentation -- key practices for many scientific domains, including, for example, neuroscience, where they are used to derive the anatomical relationships of the brain. These instruments now necessitate equally advanced computing resources and techniques to realize their full potential. Here we present a fast out-of-focus detection algorithm for electron microscopy images collected serially and demonstrate that it can be used to provide near-real time quality control for neurology research. Our technique, Multi-scale Histologic Feature Detection, adapts classical computer vision techniques and is based on detecting various fine-grained histologic features. We further exploit the inherent parallelism in the technique by employing GPGPU primitives in order to accelerate characterization. Tests are performed that demonstrate near-real-time detection of out-of-focus conditions. We deploy these capabilities as a funcX function and show that it can be applied as data are collected using an automated pipeline . We discuss extensions that enable scaling out to support multi-beam microscopes and integration with existing focus systems for purposes of implementing auto-focus.
Confluence of Artificial Intelligence and High Performance Computing for Accelerated, Scalable and Reproducible Gravitational Wave Detection
Dec 15, 2020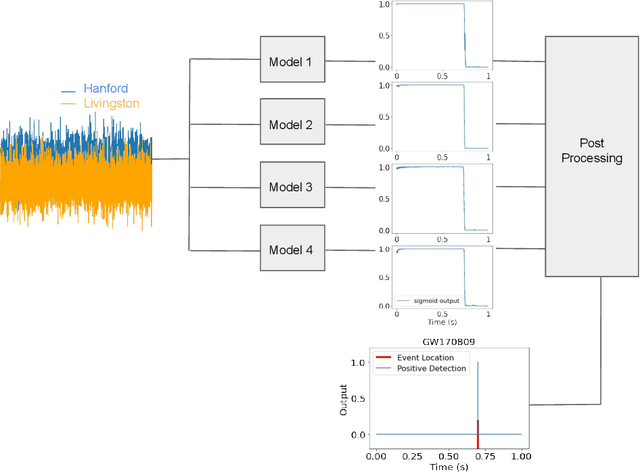
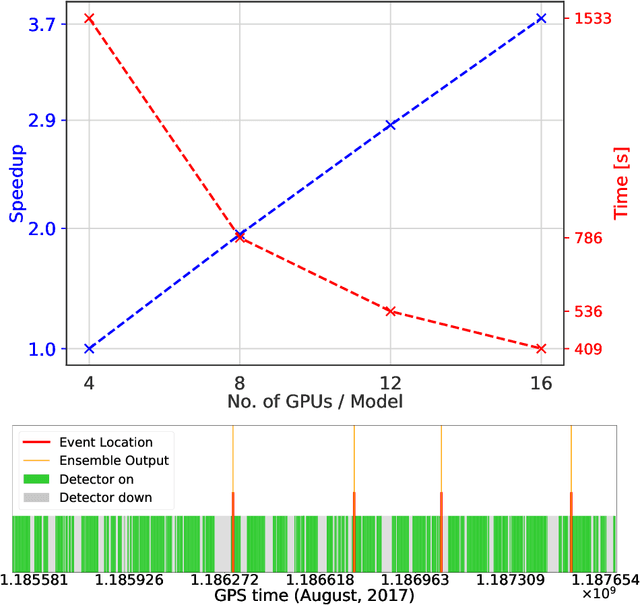
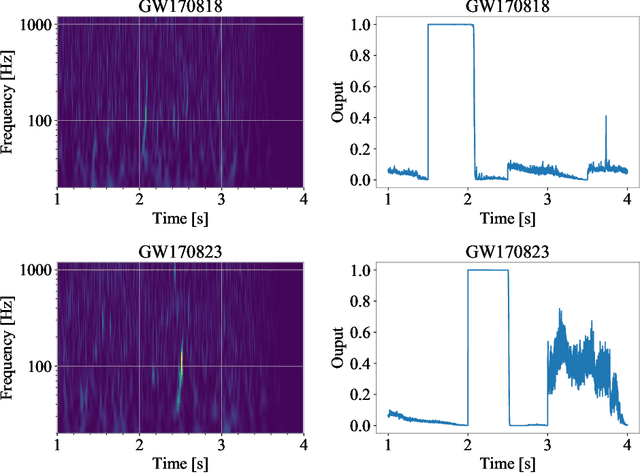
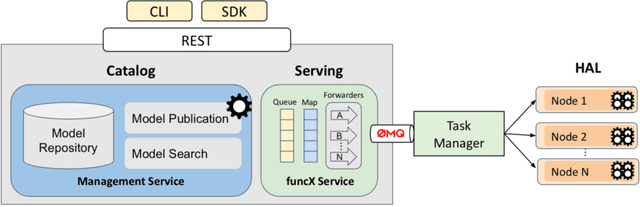
Finding new ways to use artificial intelligence (AI) to accelerate the analysis of gravitational wave data, and ensuring the developed models are easily reusable promises to unlock new opportunities in multi-messenger astrophysics (MMA), and to enable wider use, rigorous validation, and sharing of developed models by the community. In this work, we demonstrate how connecting recently deployed DOE and NSF-sponsored cyberinfrastructure allows for new ways to publish models, and to subsequently deploy these models into applications using computing platforms ranging from laptops to high performance computing clusters. We develop a workflow that connects the Data and Learning Hub for Science (DLHub), a repository for publishing machine learning models, with the Hardware Accelerated Learning (HAL) deep learning computing cluster, using funcX as a universal distributed computing service. We then use this workflow to search for binary black hole gravitational wave signals in open source advanced LIGO data. We find that using this workflow, an ensemble of four openly available deep learning models can be run on HAL and process the entire month of August 2017 of advanced LIGO data in just seven minutes, identifying all four binary black hole mergers previously identified in this dataset, and reporting no misclassifications. This approach, which combines advances in AI, distributed computing, and scientific data infrastructure opens new pathways to conduct reproducible, accelerated, data-driven gravitational wave detection.
Comparing the costs of abstraction for DL frameworks
Dec 13, 2020
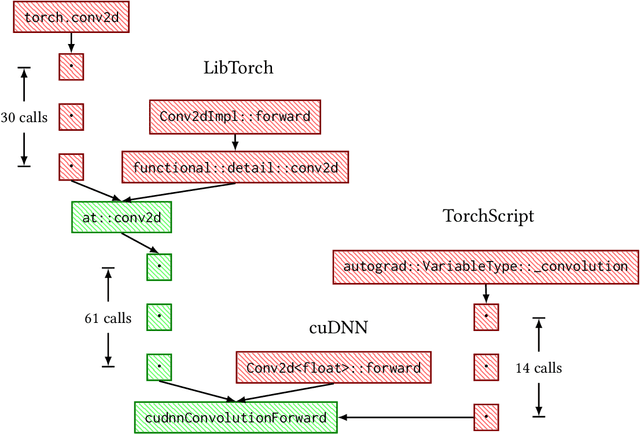
High level abstractions for implementing, training, and testing Deep Learning (DL) models abound. Such frameworks function primarily by abstracting away the implementation details of arbitrary neural architectures, thereby enabling researchers and engineers to focus on design. In principle, such frameworks could be "zero-cost abstractions"; in practice, they incur translation and indirection overheads. We study at which points exactly in the engineering life-cycle of a DL model the highest costs are paid and whether they can be mitigated. We train, test, and evaluate a representative DL model using PyTorch, LibTorch, TorchScript, and cuDNN on representative datasets, comparing accuracy, execution time and memory efficiency.
Towards Online Steering of Flame Spray Pyrolysis Nanoparticle Synthesis
Oct 16, 2020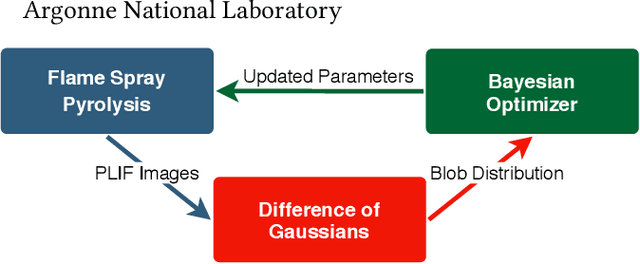
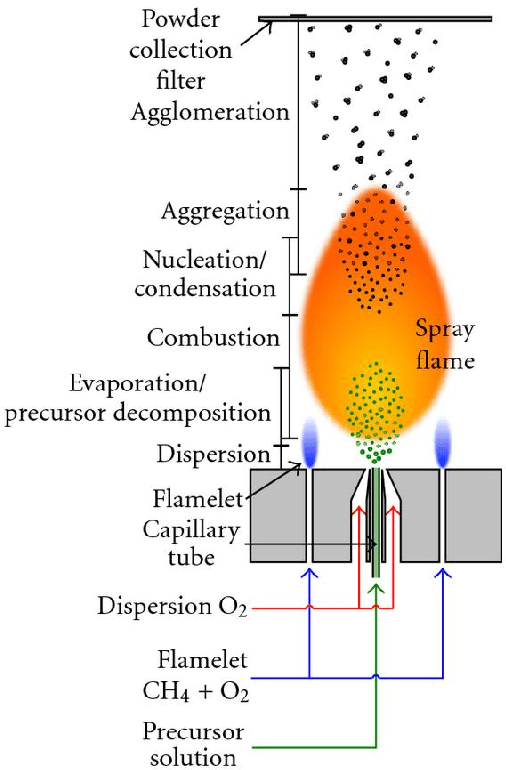

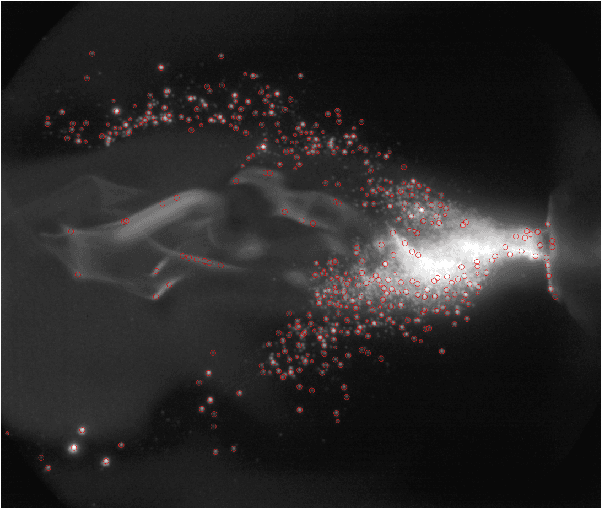
Flame Spray Pyrolysis (FSP) is a manufacturing technique to mass produce engineered nanoparticles for applications in catalysis, energy materials, composites, and more. FSP instruments are highly dependent on a number of adjustable parameters, including fuel injection rate, fuel-oxygen mixtures, and temperature, which can greatly affect the quality, quantity, and properties of the yielded nanoparticles. Optimizing FSP synthesis requires monitoring, analyzing, characterizing, and modifying experimental conditions.Here, we propose a hybrid CPU-GPU Difference of Gaussians (DoG)method for characterizing the volume distribution of unburnt solution, so as to enable near-real-time optimization and steering of FSP experiments. Comparisons against standard implementations show our method to be an order of magnitude more efficient. This surrogate signal can be deployed as a component of an online end-to-end pipeline that maximizes the synthesis yield.