 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOFA: Discovering Materials for Carbon Capture with a GenAI- and Simulation-Based Workflow
Jan 18, 2025We present MOFA, an open-source generative AI (GenAI) plus simulation workflow for high-throughput generation of metal-organic frameworks (MOFs) on large-scale high-performance computing (HPC) systems. MOFA addresses key challenges in integrating GPU-accelerated computing for GPU-intensive GenAI tasks, including distributed training and inference, alongside CPU- and GPU-optimized tasks for screening and filtering AI-generated MOFs using molecular dynamics, density functional theory, and Monte Carlo simulations. These heterogeneous tasks are unified within an online learning framework that optimizes the utilization of available CPU and GPU resources across HPC systems. Performance metrics from a 450-node (14,400 AMD Zen 3 CPUs + 1800 NVIDIA A100 GPUs) supercomputer run demonstrate that MOFA achieves high-throughput generation of novel MOF structures, with CO$_2$ adsorption capacities ranking among the top 10 in the hypothetical MOF (hMOF) dataset. Furthermore, the production of high-quality MOFs exhibits a linear relationship with the number of nodes utilized. The modular architecture of MOFA will facilitate its integration into other scientific applications that dynamically combine GenAI with large-scale simulations.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Twins in rotational spectroscopy: Does a rotational spectrum uniquely identify a molecule?
Apr 05, 2024


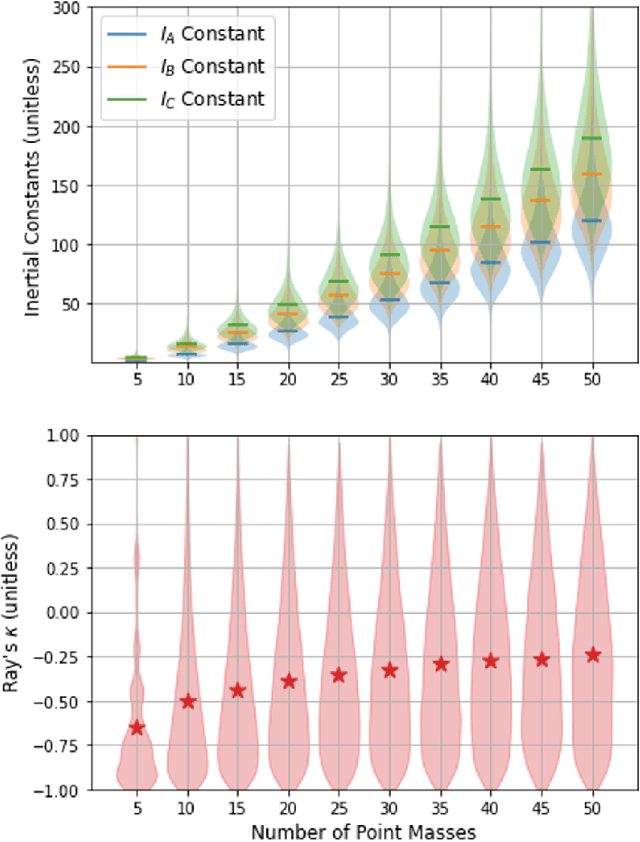
Rotational spectroscopy is the most accurate method for determining structures of molecules in the gas phase. It is often assumed that a rotational spectrum is a unique "fingerprint" of a molecule. The availability of large molecular databases and the development of artificial intelligence methods for spectroscopy makes the testing of this assumption timely. In this paper, we pose the determination of molecular structures from rotational spectra as an inverse problem. Within this framework, we adopt a funnel-based approach to search for molecular twins, which are two or more molecules, which have similar rotational spectra but distinctly different molecular structures. We demonstrate that there are twins within standard levels of computational accuracy by generating rotational constants for many molecules from several large molecular databases, indicating the inverse problem is ill-posed. However, some twins can be distinguished by increasing the accuracy of the theoretical methods or by performing additional experiments.
14 Examples of How LLMs Can Transform Materials Science and Chemistry: A Reflection on a Large Language Model Hackathon
Jun 13, 2023



Chemistry and materials science are complex. Recently, there have been great successes in addressing this complexity using data-driven or computational techniques. Yet, the necessity of input structured in very specific forms and the fact that there is an ever-growing number of tools creates usability and accessibility challenges. Coupled with the reality that much data in these disciplines is unstructured, the effectiveness of these tools is limited. Motivated by recent works that indicated that large language models (LLMs) might help address some of these issues, we organized a hackathon event on the applications of LLMs in chemistry, materials science, and beyond. This article chronicles the projects built as part of this hackathon. Participants employed LLMs for various applications, including predicting properties of molecules and materials, designing novel interfaces for tools, extracting knowledge from unstructured data, and developing new educational applications. The diverse topics and the fact that working prototypes could be generated in less than two days highlight that LLMs will profoundly impact the future of our fields. The rich collection of ideas and projects also indicates that the applications of LLMs are not limited to materials science and chemistry but offer potential benefits to a wide range of scientific disciplines.
The eBible Corpus: Data and Model Benchmarks for Bible Translation for Low-Resource Languages
Apr 19, 2023
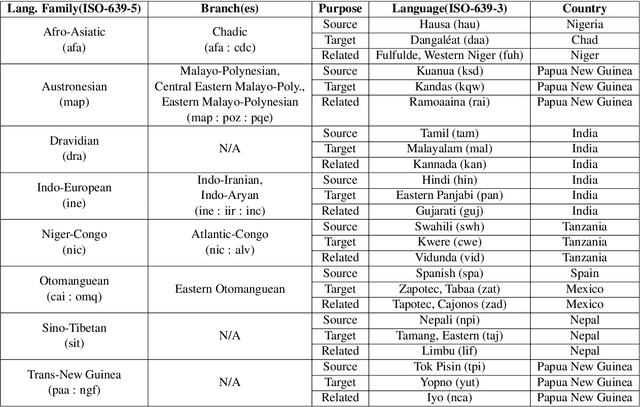
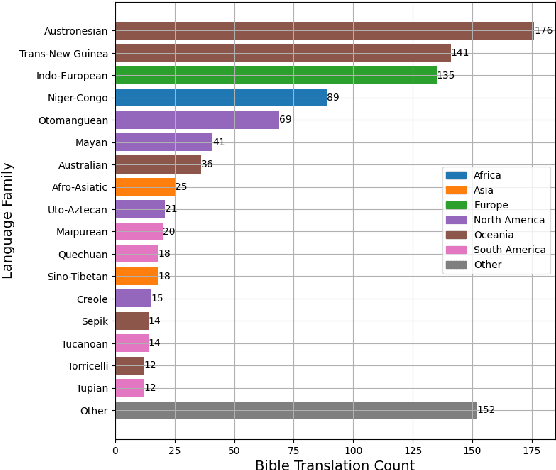
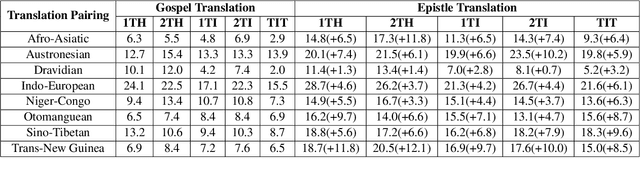
Efficiently and accurately translating a corpus into a low-resource language remains a challenge, regardless of the strategies employed, whether manual, automated, or a combination of the two. Many Christian organizations are dedicated to the task of translating the Holy Bible into languages that lack a modern translation. Bible translation (BT) work is currently underway for over 3000 extremely low resource languages. We introduce the eBible corpus: a dataset containing 1009 translations of portions of the Bible with data in 833 different languages across 75 language families. In addition to a BT benchmarking dataset, we introduce model performance benchmarks built on the No Language Left Behind (NLLB) neural machine translation (NMT) models. Finally, we describe several problems specific to the domain of BT and consider how the established data and model benchmarks might be used for future translation efforts. For a BT task trained with NLLB, Austronesian and Trans-New Guinea language families achieve 35.1 and 31.6 BLEU scores respectively, which spurs future innovations for NMT for low-resource languages in Papua New Guinea.
3D Convolutional Neural Networks for Dendrite Segmentation Using Fine-Tuning and Hyperparameter Optimization
May 02, 2022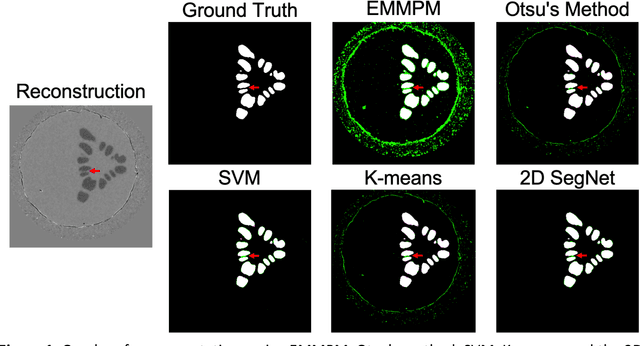
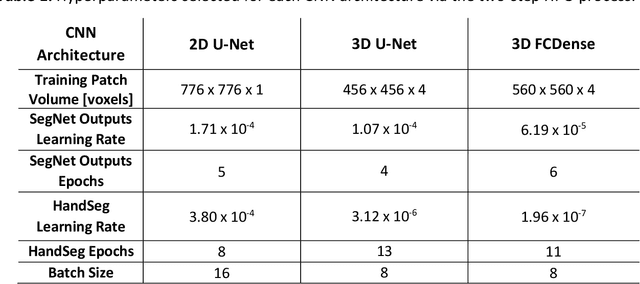

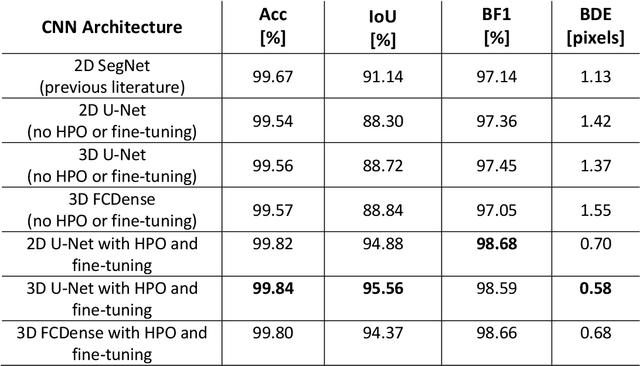
Dendritic microstructures are ubiquitous in nature and are the primary solidification morphologies in metallic materials. Techniques such as x-ray computed tomography (XCT) have provided new insights into dendritic phase transformation phenomena. However, manual identification of dendritic morphologies in microscopy data can be both labor intensive and potentially ambiguous. The analysis of 3D datasets is particularly challenging due to their large sizes (terabytes) and the presence of artifacts scattered within the imaged volumes. In this study, we trained 3D convolutional neural networks (CNNs) to segment 3D datasets. Three CNN architectures were investigated, including a new 3D version of FCDense. We show that using hyperparameter optimization (HPO) and fine-tuning techniques, both 2D and 3D CNN architectures can be trained to outperform the previous state of the art. The 3D U-Net architecture trained in this study produced the best segmentations according to quantitative metrics (pixel-wise accuracy of 99.84% and a boundary displacement error of 0.58 pixels), while 3D FCDense produced the smoothest boundaries and best segmentations according to visual inspection. The trained 3D CNNs are able to segment entire 852 x 852 x 250 voxel 3D volumes in only ~60 seconds, thus hastening the progress towards a deeper understanding of phase transformation phenomena such as dendritic solidification.
Towards Online Steering of Flame Spray Pyrolysis Nanoparticle Synthesis
Oct 16, 2020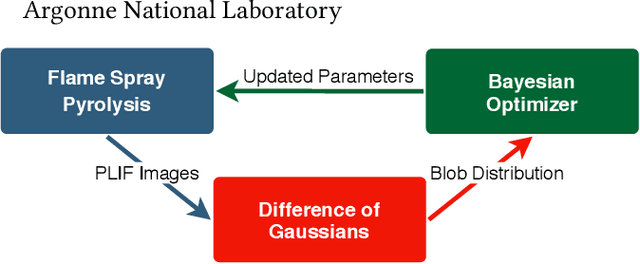
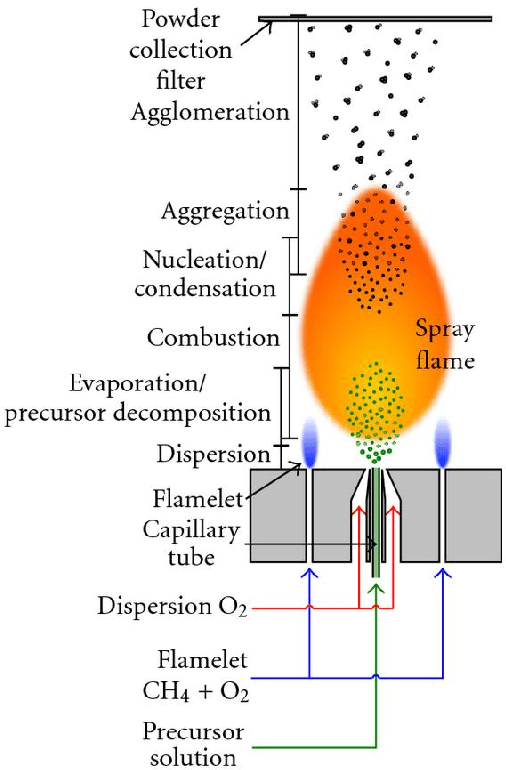

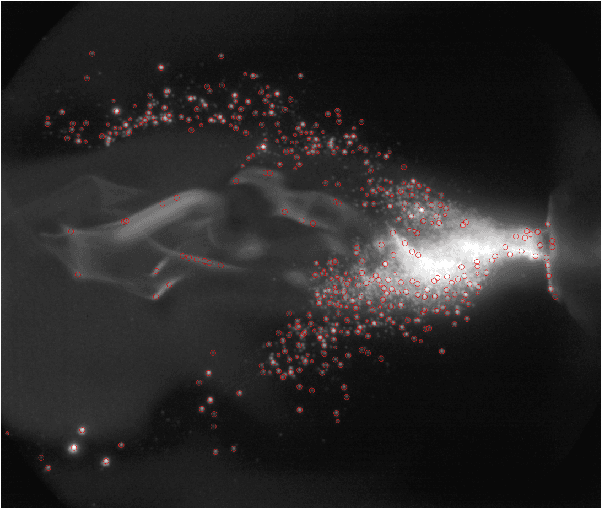
Flame Spray Pyrolysis (FSP) is a manufacturing technique to mass produce engineered nanoparticles for applications in catalysis, energy materials, composites, and more. FSP instruments are highly dependent on a number of adjustable parameters, including fuel injection rate, fuel-oxygen mixtures, and temperature, which can greatly affect the quality, quantity, and properties of the yielded nanoparticles. Optimizing FSP synthesis requires monitoring, analyzing, characterizing, and modifying experimental conditions.Here, we propose a hybrid CPU-GPU Difference of Gaussians (DoG)method for characterizing the volume distribution of unburnt solution, so as to enable near-real-time optimization and steering of FSP experiments. Comparisons against standard implementations show our method to be an order of magnitude more efficient. This surrogate signal can be deployed as a component of an online end-to-end pipeline that maximizes the synthesis yield.
Targeting SARS-CoV-2 with AI- and HPC-enabled Lead Generation: A First Data Release
May 28, 2020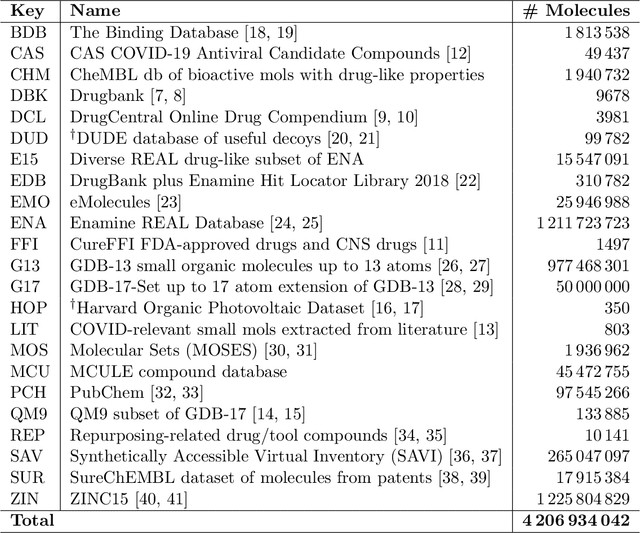
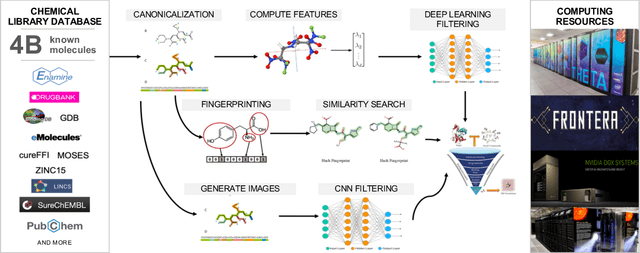

Researchers across the globe are seeking to rapidly repurpose existing drugs or discover new drugs to counter the the novel coronavirus disease (COVID-19) caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). One promising approach is to train machine learning (ML) and artificial intelligence (AI) tools to screen large numbers of small molecules. As a contribution to that effort, we are aggregating numerous small molecules from a variety of sources, using high-performance computing (HPC) to computer diverse properties of those molecules, using the computed properties to train ML/AI models, and then using the resulting models for screening. In this first data release, we make available 23 datasets collected from community sources representing over 4.2 B molecules enriched with pre-computed: 1) molecular fingerprints to aid similarity searches, 2) 2D images of molecules to enable exploration and application of image-based deep learning methods, and 3) 2D and 3D molecular descriptors to speed development of machine learning models. This data release encompasses structural information on the 4.2 B molecules and 60 TB of pre-computed data. Future releases will expand the data to include more detailed molecular simulations, computed models, and other products.