 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Soft Label in Label Distribution Learning Perspective
Jan 31, 2023The primary goal of training in early convolutional neural networks (CNN) is the higher generalization performance of the model. However, as the expected calibration error (ECE), which quantifies the explanatory power of model inference, was recently introduced, research on training models that can be explained is in progress. We hypothesized that a gap in supervision criteria during training and inference leads to overconfidence, and investigated that performing label distribution learning (LDL) would enhance the model calibration in CNN training. To verify this assumption, we used a simple LDL setting with recent data augmentation techniques. Based on a series of experiments, the following results are obtained: 1) State-of-the-art KD methods significantly impede model calibration. 2) Training using LDL with recent data augmentation can have excellent effects on model calibration and even in generalization performance. 3) Online LDL brings additional improvements in model calibration and accuracy with long training, especially in large-size models. Using the proposed approach, we simultaneously achieved a lower ECE and higher generalization performance for the image classification datasets CIFAR10, 100, STL10, and ImageNet. We performed several visualizations and analyses and witnessed several interesting behaviors in CNN training with the LDL.
3D Convolutional Neural Networks for Dendrite Segmentation Using Fine-Tuning and Hyperparameter Optimization
May 02, 2022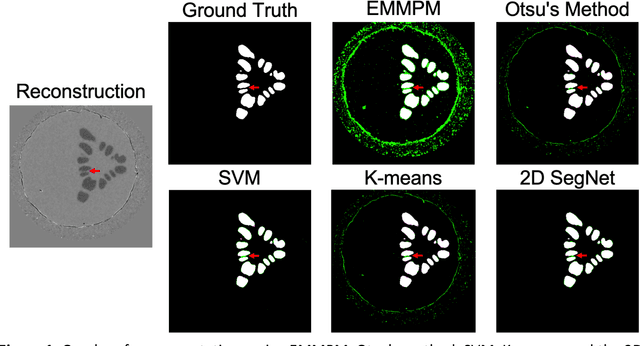
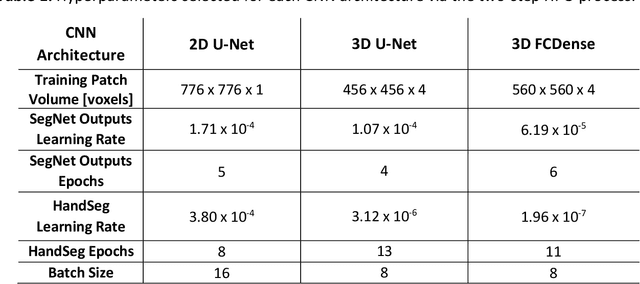

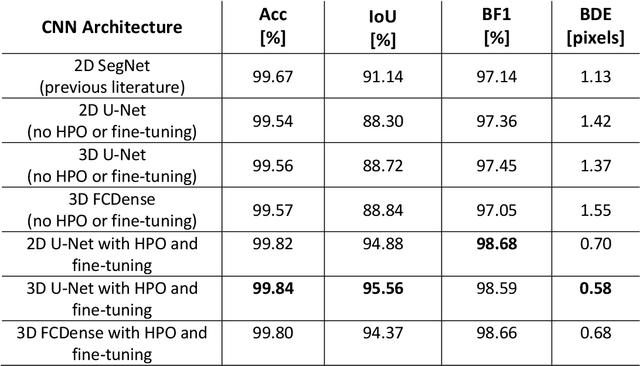
Dendritic microstructures are ubiquitous in nature and are the primary solidification morphologies in metallic materials. Techniques such as x-ray computed tomography (XCT) have provided new insights into dendritic phase transformation phenomena. However, manual identification of dendritic morphologies in microscopy data can be both labor intensive and potentially ambiguous. The analysis of 3D datasets is particularly challenging due to their large sizes (terabytes) and the presence of artifacts scattered within the imaged volumes. In this study, we trained 3D convolutional neural networks (CNNs) to segment 3D datasets. Three CNN architectures were investigated, including a new 3D version of FCDense. We show that using hyperparameter optimization (HPO) and fine-tuning techniques, both 2D and 3D CNN architectures can be trained to outperform the previous state of the art. The 3D U-Net architecture trained in this study produced the best segmentations according to quantitative metrics (pixel-wise accuracy of 99.84% and a boundary displacement error of 0.58 pixels), while 3D FCDense produced the smoothest boundaries and best segmentations according to visual inspection. The trained 3D CNNs are able to segment entire 852 x 852 x 250 voxel 3D volumes in only ~60 seconds, thus hastening the progress towards a deeper understanding of phase transformation phenomena such as dendritic solidification.
PEg TRAnsfer Workflow recognition challenge report: Does multi-modal data improve recognition?
Feb 11, 2022
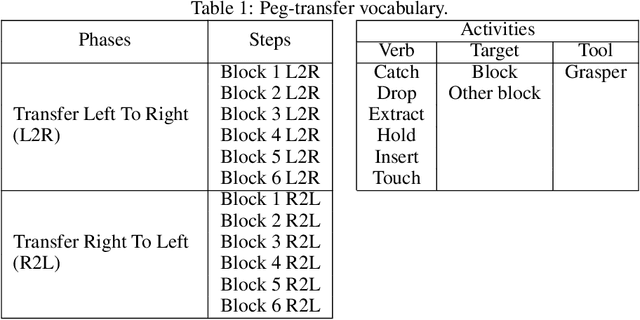
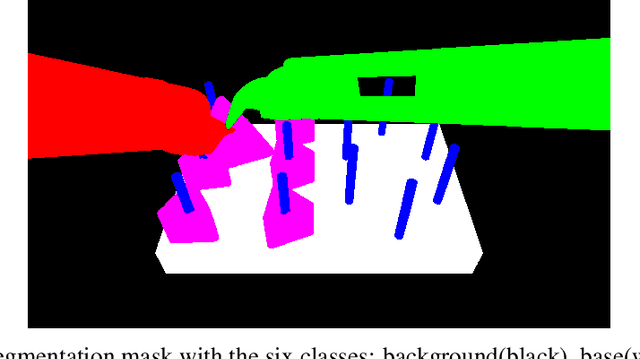
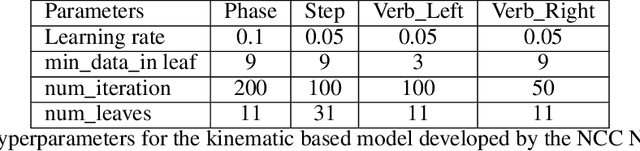
This paper presents the design and results of the "PEg TRAnsfert Workflow recognition" (PETRAW) challenge whose objective was to develop surgical workflow recognition methods based on one or several modalities, among video, kinematic, and segmentation data, in order to study their added value. The PETRAW challenge provided a data set of 150 peg transfer sequences performed on a virtual simulator. This data set was composed of videos, kinematics, semantic segmentation, and workflow annotations which described the sequences at three different granularity levels: phase, step, and activity. Five tasks were proposed to the participants: three of them were related to the recognition of all granularities with one of the available modalities, while the others addressed the recognition with a combination of modalities. Average application-dependent balanced accuracy (AD-Accuracy) was used as evaluation metric to take unbalanced classes into account and because it is more clinically relevant than a frame-by-frame score. Seven teams participated in at least one task and four of them in all tasks. Best results are obtained with the use of the video and the kinematics data with an AD-Accuracy between 93% and 90% for the four teams who participated in all tasks. The improvement between video/kinematic-based methods and the uni-modality ones was significant for all of the teams. However, the difference in testing execution time between the video/kinematic-based and the kinematic-based methods has to be taken into consideration. Is it relevant to spend 20 to 200 times more computing time for less than 3% of improvement? The PETRAW data set is publicly available at www.synapse.org/PETRAW to encourage further research in surgical workflow recognition.
hSDB-instrument: Instrument Localization Database for Laparoscopic and Robotic Surgeries
Oct 26, 2021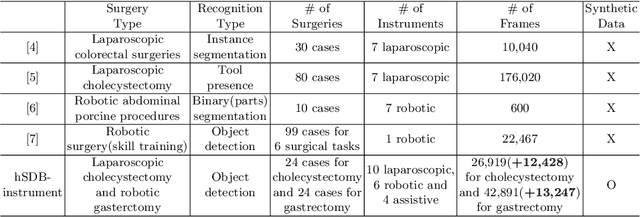
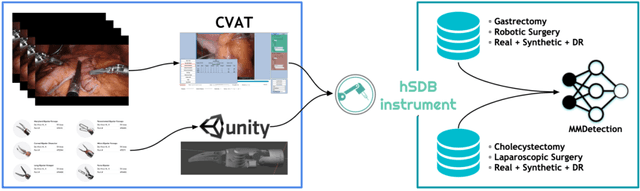
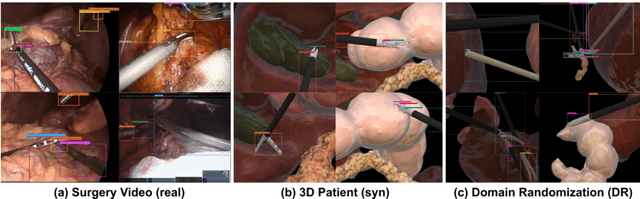
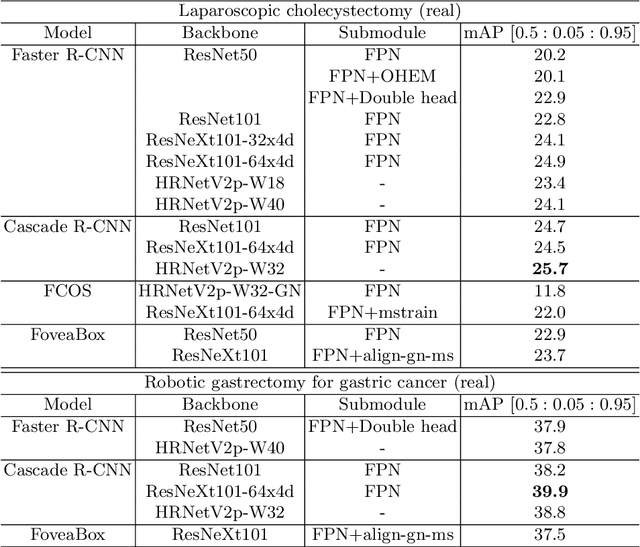
Automated surgical instrument localization is an important technology to understand the surgical process and in order to analyze them to provide meaningful guidance during surgery or surgical index after surgery to the surgeon. We introduce a new dataset that reflects the kinematic characteristics of surgical instruments for automated surgical instrument localization of surgical videos. The hSDB(hutom Surgery DataBase)-instrument dataset consists of instrument localization information from 24 cases of laparoscopic cholecystecomy and 24 cases of robotic gastrectomy. Localization information for all instruments is provided in the form of a bounding box for object detection. To handle class imbalance problem between instruments, synthesized instruments modeled in Unity for 3D models are included as training data. Besides, for 3D instrument data, a polygon annotation is provided to enable instance segmentation of the tool. To reflect the kinematic characteristics of all instruments, they are annotated with head and body parts for laparoscopic instruments, and with head, wrist, and body parts for robotic instruments separately. Annotation data of assistive tools (specimen bag, needle, etc.) that are frequently used for surgery are also included. Moreover, we provide statistical information on the hSDB-instrument dataset and the baseline localization performances of the object detection networks trained by the MMDetection library and resulting analyses.
* https://hsdb-instrument.github.io
Self-Supervised Knowledge Transfer via Loosely Supervised Auxiliary Tasks
Oct 25, 2021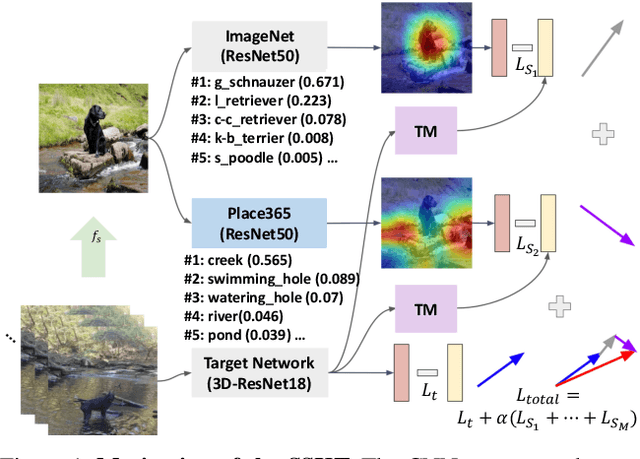
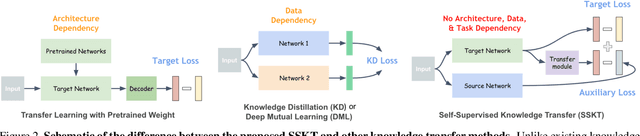
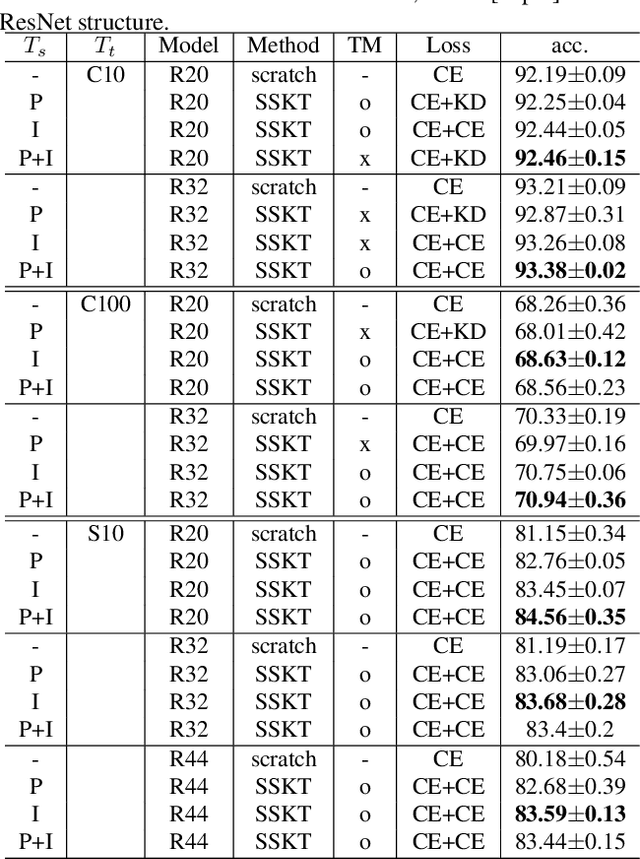
Knowledge transfer using convolutional neural networks (CNNs) can help efficiently train a CNN with fewer parameters or maximize the generalization performance under limited supervision. To enable a more efficient transfer of pretrained knowledge under relaxed conditions, we propose a simple yet powerful knowledge transfer methodology without any restrictions regarding the network structure or dataset used, namely self-supervised knowledge transfer (SSKT), via loosely supervised auxiliary tasks. For this, we devise a training methodology that transfers previously learned knowledge to the current training process as an auxiliary task for the target task through self-supervision using a soft label. The SSKT is independent of the network structure and dataset, and is trained differently from existing knowledge transfer methods; hence, it has an advantage in that the prior knowledge acquired from various tasks can be naturally transferred during the training process to the target task. Furthermore, it can improve the generalization performance on most datasets through the proposed knowledge transfer between different problem domains from multiple source networks. SSKT outperforms the other transfer learning methods (KD, DML, and MAXL) through experiments under various knowledge transfer settings. The source code will be made available to the public.
Rethinking Generalization Performance of Surgical Phase Recognition with Expert-Generated Annotations
Oct 22, 2021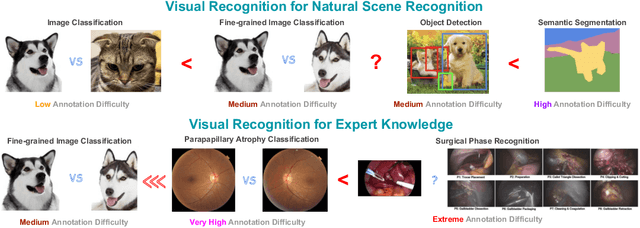

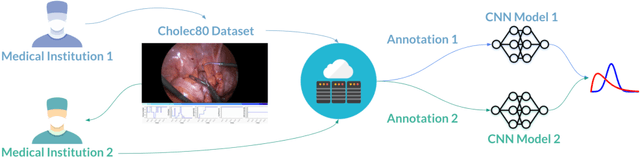
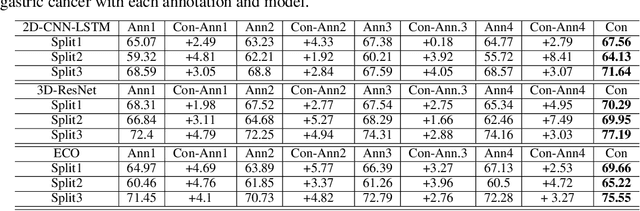
As the area of application of deep neural networks expands to areas requiring expertise, e.g., in medicine and law, more exquisite annotation processes for expert knowledge training are required. In particular, it is difficult to guarantee generalization performance in the clinical field in the case of expert knowledge training where opinions may differ even among experts on annotations. To raise the issue of the annotation generation process for expertise training of CNNs, we verified the annotations for surgical phase recognition of laparoscopic cholecystectomy and subtotal gastrectomy for gastric cancer. We produce calibrated annotations for the seven phases of cholecystectomy by analyzing the discrepancies of previously annotated labels and by discussing the criteria of surgical phases. For gastrectomy for gastric cancer has more complex twenty-one surgical phases, we generate consensus annotation by the revision process with five specialists. By training the CNN-based surgical phase recognition networks with revised annotations, we achieved improved generalization performance over models trained with original annotation under the same cross-validation settings. We showed that the expertise data annotation pipeline for deep neural networks should be more rigorous based on the type of problem to apply clinical field.
Semi-Supervised Object Detection with Sparsely Annotated Dataset
Jun 21, 2020
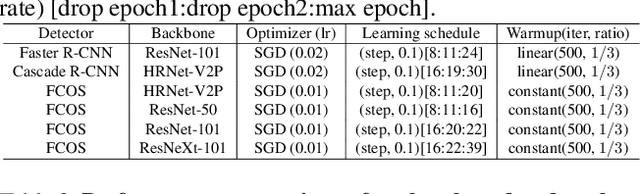
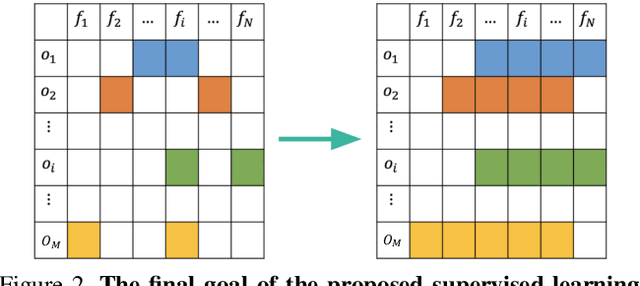
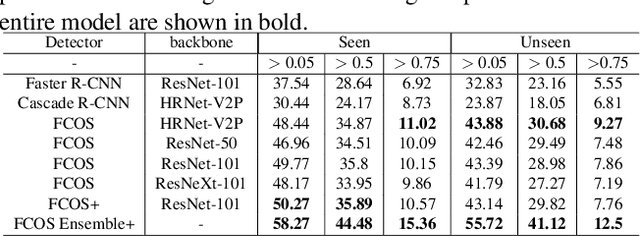
In training object detector based on convolutional neural networks, selection of effective positive examples for training is an important factor. However, when training an anchor-based detectors with sparse annotations on an image, effort to find effective positive examples can hinder training performance. When using the anchor-based training for the ground truth bounding box to collect positive examples under given IoU, it is often possible to include objects from other classes in the current training class, or objects that are needed to be trained can only be sampled as negative examples. We used two approaches to solve this problem: 1) the use of an anchorless object detector and 2) a semi-supervised learning-based object detection using a single object tracker. The proposed technique performs single object tracking by using the sparsely annotated bounding box as an anchor in the temporal domain for successive frames. From the tracking results, dense annotations for training images were generated in an automated manner and used for training the object detector. We applied the proposed single object tracking-based semi-supervised learning to the Epic-Kitchens dataset. As a result, we were able to achieve \textbf{runner-up} performance in the Unseen section while achieving the first place in the Seen section of the Epic-Kitchens 2020 object detection challenge under IoU > 0.5 evaluation